







 本文详细介绍了Apache Impala的安装与配置过程,包括Impala的基本概念、与Hive的关系及其异同点。强调了Impala作为高效SQL查询工具的优势,以及在大数据领域的实时查询性能。文章还提供了完整的安装步骤,包括配置本地yum源、安装Impala、修改Hadoop和Hive配置等,旨在帮助读者顺利部署和使用Impala。
本文详细介绍了Apache Impala的安装与配置过程,包括Impala的基本概念、与Hive的关系及其异同点。强调了Impala作为高效SQL查询工具的优势,以及在大数据领域的实时查询性能。文章还提供了完整的安装步骤,包括配置本地yum源、安装Impala、修改Hadoop和Hive配置等,旨在帮助读者顺利部署和使用Impala。
Impala基本介绍
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sql工具,
impala是参照谷歌的新三篇论文(Caffeine–网络搜索引擎、Pregel–分布式图计算、Dremel–交互式分析工具)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应我们即将学的HBase和已经学过的HDFS以及MapReduce。
impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。

Impala与Hive关系
mpala是基于hive的大数据分析查询引擎,直接使用hive的元数据库metadata,意味着impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。所以需要安装impala的话,必须先安装hive,保证hive安装成功,并且还需要启动hive的metastore服务。
Hive元数据包含用Hive创建的database、table等元信息。元数据存储在关系型数据库中,如Derby、MySQL等。
客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
nohup hive --service metastore >> ~/metastore.log 2>&1 &
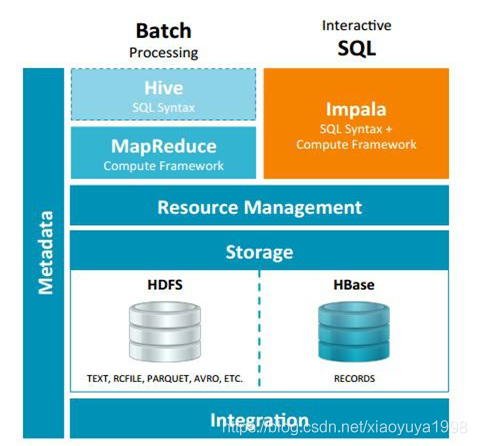
Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
Impala与Hive异同
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。
但是Impala跟Hive最大的优化区别在于:没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比,Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
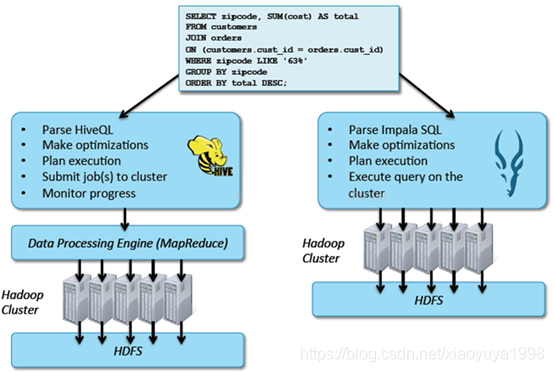
Impala安装部署
1. 安装前提
集群提前安装好hadoop,hive。
hive安装包scp在所有需要安装impala的节点上,因为impala需要引用hive的依赖包。
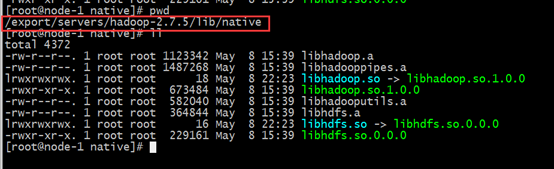
hadoop框架需要支持C程序访问接口,查看下图,如果有该路径下有这么文件,就证明支持C接口。
2. 下载安装包、依赖包
由于impala没有提供tar包进行安装,只提供了rpm包。因此在安装impala的时候,需要使用rpm包来进行安装。rpm包只有cloudera公司提供了,所以去cloudera公司网站进行下载rpm包即可。
但是另外一个问题,impala的rpm包依赖非常多的其他的rpm包,可以一个个的将依赖找出来,也可以将所有的rpm包下载下来,制作成我们本地yum源来进行安装。这里就选择制作本地的yum源来进行安装。
所以首先需要下载到所有的rpm包,下载地址如下
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/cdh5.14.0-centos6.tar.gz
3. 虚拟机新增磁盘(可选)
由于下载的cdh5.14.0-centos6.tar.gz包非常大,大概5个G,解压之后也最少需要5个G的空间。而我们的虚拟机磁盘有限,可能会不够用了,所以可以为虚拟机挂载一块新的磁盘,专门用于存储的cdh5.14.0-centos6.tar.gz包。
注意事项:新增挂载磁盘需要虚拟机保持在关机状态。
如果磁盘空间有余,那么本步骤可以省略不进行。
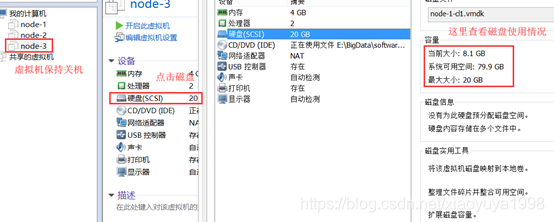
3.1. 关机新增磁盘
虚拟机关机的状态下,在VMware当中新增一块磁盘。
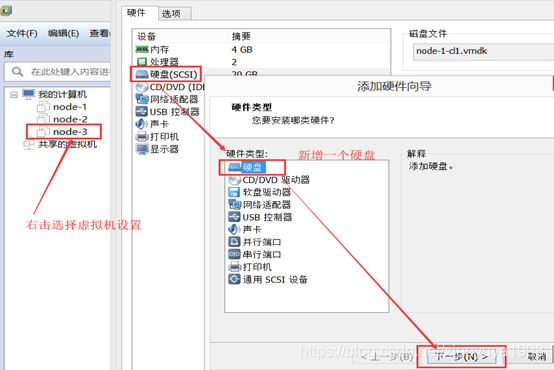
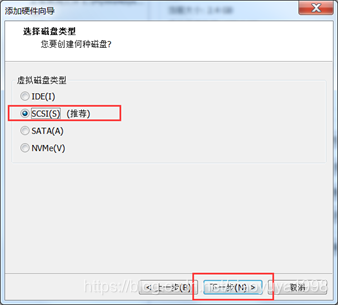
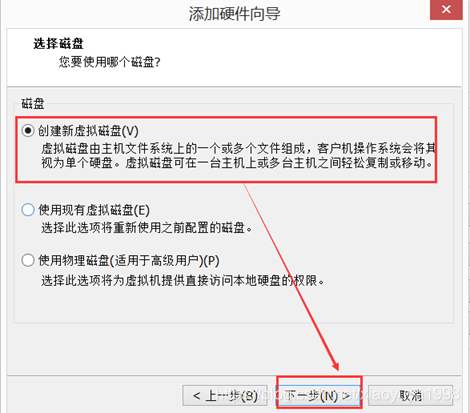
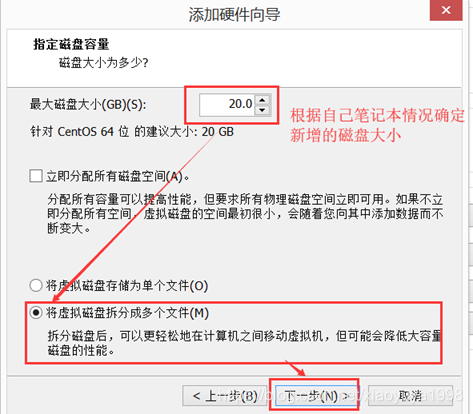
3.2. 开机挂载磁盘
开启虚拟机,对新增的磁盘进行分区,格式化,并且挂载新磁盘到指定目录。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2026
2026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









