







目录
(一)apply、applymap 与 transform 的区别与应用
一、Pandas 基础回顾
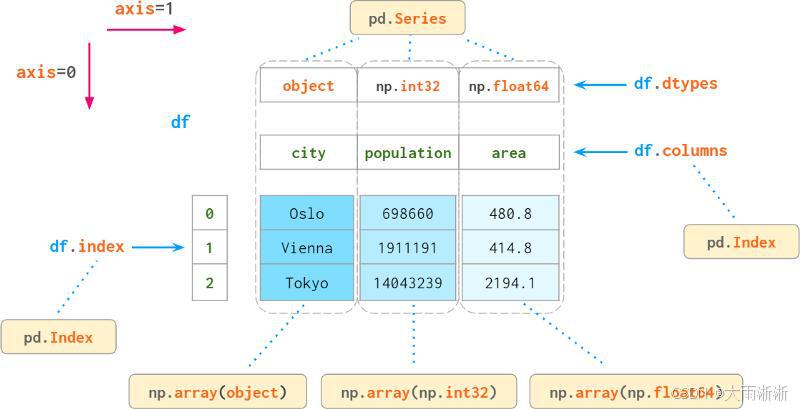
在数据处理与分析的广阔领域中,Pandas 就如同一位得力的 “数据魔法师”,是 Python 数据分析生态系统中不可或缺的核心库。凭借其强大的数据处理和分析能力,Pandas 在众多数据科学项目里发挥着关键作用,成为了数据科学家和 Python 开发者们的得力助手。
Pandas 中有两个最为核心的数据结构,即 Series 和 DataFrame,它们是我们开启数据处理大门的钥匙。Series 可以看作是一个一维的带标签数组,每一个元素都对应着一个唯一的索引标签。比如,我们想记录一个班级学生的数学成绩:
import pandas as pd
math_scores = pd.Series([90, 85, 78, 92, 88], index=['Alice', 'Bob', 'Charlie', 'David', 'Ella'])
print(math_scores)
输出结果:
Alice 90
Bob 85
Charlie 78
David 92
Ella 88
dtype: int64
通过这样的方式,我们不仅能清晰地看到每个学生的成绩,还能借助索引标签快速定位到特定学生的数据。
而 DataFrame 则像是一个二维的表格,由多个 Series 组成,每一列都是一个 Series,且所有列共享同一索引。例如,我们要记录班级学生的数学、语文和英语成绩:
data = {
'Math': [90, 85, 78, 92, 88],
'Chinese': [88, 90, 85, 80, 95],
'English': [95, 88, 92, 85, 86]
}
scores_df = pd.DataFrame(data, index=['Alice', 'Bob', 'Charlie', 'David', 'Ella'])
print(scores_df)
输出结果:
Math Chinese English
Alice 90 88 95
Bob 85 90 88
Charlie 78 85 92
David 92 80 85
Ella 88 95 86
这样,我们就可以方便地对整个班级学生的多门课程成绩进行综合分析,无论是查看某个学生的所有成绩,还是统计某门课程的整体情况,都能轻松实现。
二、数据选取与过滤的进阶技巧
(一)loc 与 iloc 的深度用法
在 Pandas 的数据处理中,数据选取是一项基础且关键的操作。loc和iloc作为 Pandas 中用于数据选取的重要方法,它们有着各自独特的功能和应用场景。loc基于索引标签进行数据选取,而iloc则依据整数位置来选取数据 。这一本质区别决定了它们在不同数据结构和需求下的使用方式。
假设我们有一个记录了学生成绩的 DataFrame:
import pandas as pd
data = {
'Math': [90, 85, 78, 92, 88],
'Chinese': [88, 90, 85, 80, 95],
'English': [95, 88, 92, 85, 86]
}
scores_df = pd.DataFrame(data, index=['Alice', 'Bob', 'Charlie', 'David', 'Ella'])
若我们想选取Bob的数学成绩,使用loc就可以轻松实现:
bob_math_score = scores_df.loc['Bob', 'Math']
print(bob_math_score)
输出结果为:
85
这里,loc通过行索引标签Bob和列索引标签Math精准定位到了相应的数据。
而如果我们想选取第二行(索引从 0 开始,即Bob这一行)和第二列(即Chinese这一列)的数据,使用iloc则更为合适:
second_row_second_col = scores_df.iloc[1, 1]
print(second_row_second_col)
输出结果同样是:
90
iloc按照整数位置,准确地找到了对应的数据。
当我们需要选取多行多列的数据时,loc和iloc的用法也十分直观。比如,要选取Alice到Charlie的Math和Chinese成绩:
subset1 = scores_df.loc['Alice':'Charlie', ['Math', 'Chinese']]
print(subset1)
输出结果:
Math Chinese
Alice 90 88
Bob 85 90
Charlie 78 85
这里loc根据行索引标签的范围和列索引标签列表进行选取。
若使用iloc,选取前三行和前两列的数据:
subset2 = scores_df.iloc[0:3, 0:2]
print(subset2)
输出结果:
Math Chinese
Alice 90 88
Bob 85 90
Charlie 78 85
iloc依据整数位置的范围进行数据筛选。通过这样的对比,我们能更清晰地看到loc和iloc在数据选取上的差异和各自的优势。
(二)复杂条件筛选
在实际的数据处理任务中,简单的单条件筛选往往难以满足需求,我们常常需要根据多个复杂条件来筛选数据。Pandas 提供了强大的逻辑运算符和query方法,让复杂条件筛选变得简洁高效。
以之前的学生成绩 DataFrame 为例,若我们想筛选出数学成绩大于 90 分且语文成绩大于 85 分的学生,就可以使用逻辑运算符&(与)来实现:
filtered_df1 = scores_df[(scores_df['Math'] > 90) & (scores_df['Chinese'] > 85)]
print(filtered_df1)
输出结果:
Math Chinese English
David 92 80 85
Ella 88 95 86
这里,(scores_df['Math'] > 90)和(scores_df['Chinese'] > 85)分别是两个条件,&运算符将它们连接起来,表示同时满足这两个条件的数据才会被筛选出来。
当条件更为复杂时,合理使用括号可以明确运算的优先级。比如,我们要筛选出数学成绩大于 90 分或者语文成绩大于 90 分,且英语成绩大于 85 分的学生:
filtered_df2 = scores_df[((scores_df['Math'] > 90) | (scores_df['Chinese'] > 90)) & (scores_df['English'] > 85)]
print(filtered_df2)
输出结果:
Math Chinese English
Alice 90 88 95
Bob 85 90 88
David 92 80 85
Ella 88 95 86
在这个例子中,先使用括号将(scores_df['Math'] > 90) | (scores_df['Chinese'] > 90)这部分条件括起来,表示先进行或运算,再与(scores_df['English'] > 85)进行与运算。
除了使用逻辑运算符,Pandas 的query方法也为我们提供了一种简洁直观的复杂条件筛选方式。同样以上述条件为例,使用query方法可以这样实现:
filtered_df3 = scores_df.query('(Math > 90 or Chinese > 90) and English > 85')
print(filtered_df3)
输出结果与前面使用逻辑运算符的结果一致。query方法直接在字符串中编写条件表达式,使代码更加易读和易懂,尤其在条件较多时,这种优势更加明显。
三、数据清理与预处理的高阶手段
(一)处理缺失值的策略升级
在实际的数据处理项目中,数据缺失是极为常见的问题。缺失值的存在可能会对后续的数据分析和建模产生严重的影响,因此,如何有效地处理缺失值至关重要。在 Pandas 中,除了基本的删除缺失值和填充固定值的方法外,还有许多更为高级和智能的策略。
插值法是一种基于已有数据点来推算缺失值的有效方法,它假设数据在一定范围内呈现出某种连续的趋势。Pandas 提供了interpolate方法来实现多种插值方式,其中线性插值是最为基础的一种。假设我们有一个时间序列数据,记录了某公司每天的销售额,但其中存在一些缺失值:
import pandas as pd
import numpy as np
data = {
'date': pd.date_range('2023-01-01', periods=10),
'sales': [100, np.nan, 120, np.nan, 150, 160, np.nan, 180, np.nan, 200]
}
sales_df = pd.DataFrame(data)
使用线性插值来填充缺失值:
sales_df['sales'] = sales_df['sales'].interpolate()
print(sales_df)
输出结果:
date sales
0 2023-01-01 100.0
1 2023-01-02 110.0
2 2023-01-03 120.0
3 2023-01-04 135.0
4 2023-01-05 150.0
5 2023-01-06 160.0
6 2023-01-07 170.0
7 2023-01-08 180.0
8 2023-01-09 190.0
9 2023-01-10 200.0
从结果中可以看到,线性插值根据相邻数据点的值,合理地推算出了缺失的销售额,使得数据更加完整和平滑。
对于一些具有复杂关系的数据,我们还可以使用机器学习模型来预测缺失值。以简单的线性回归模型为例,假设我们有一个包含多个特征的数据集,其中某个特征存在缺失值:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 假设data_df是包含多个特征的数据集,'feature_to_fill'是存在缺失值的特征
data_df = pd.read_csv('your_data.csv')
X = data_df.drop('feature_to_fill', axis=1)
y = data_df['feature_to_fill']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测缺失值
missing_index = data_df['feature_to_fill'].isnull()
X_missing = data_df[missing_index].drop('feature_to_fill', axis=1)
data_df.loc[missing_index, 'feature_to_fill'] = model.predict(X_missing)
通过这种方式,利用其他特征与目标特征之间的关系,模型能够预测出较为合理的缺失值,进一步提升数据的质量和可用性。
(二)异常值检测与处理
异常值是数据集中那些与其他数据点显著不同的数据,它们可能是由于数据收集错误、测量误差或特殊事件等原因产生的。异常值的存在会严重干扰数据分析的结果,尤其是在一些基于统计模型的分析中,可能会导致模型的偏差和不准确。因此,有效地检测和处理异常值是数据预处理的关键步骤。
箱线图是一种直观且有效的异常值检测工具,它通过展示数据的四分位数、中位数以及上下边界,能够清晰地呈现数据的分布情况。我们以之前学生成绩的 DataFrame 为例,绘制数学成绩的箱线图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











