






一、题目大意
给定一个序列A和参数p,若序列A中最大值为M,最小值为m,且满足M<=m*p,则称序列A为perfect sequence。
依据这个定义,题目要求在给定的序列中找出尽可能多的元素组成一个新的序列,使得这个序列为perfect sequence。
其中 N<==10^5, p<=10^9, 元素<=10^9。
二、题目解法
首先对序列进行排序。因为完美序列一定是该序列的一个连续子序列。
排好序后,从小到大枚举每个元素L[i](因为首元素开始的perfect sequence不一定最长),假定完美序列从该元素开始,令 x = L[i]×p,即在序列中寻找第一个大于x的元素,M即为该元素前一个元素(因为可能有多个重复元素,所以不能找第一个大于等于x的元素)。由此可以求得从L[i]开始的最大perfect sequence长度。
三、程序分析
1.

错误: 1.溢出:用 int 型,最后一个测试数据会溢出导致错误。 2.超时:直接插入排序,会超时。
2.

把p改成long型,问题1就解决了。 把p*L[i]强制类型转换成long类型也可以达到一样的效果。
但 直接插入排序 会导致超时的问题仍没有解决。
由此可见,接下来我们的目标就变成要找到合适的排序方法。
经过测试,折半插入排序和快速排序都会超时。
考虑到数据规模很大,我们采用堆排序和归并排序,顺利AC。
3.堆排序
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
void HeapAdjust(int *&L, int s, int m){
int rc=L[s];
for(int i=2*s; i<=m; i*=2){
if(i<m && L[i]<L[i+1]) i++;
if(L[i]<rc) break;
L[s]=L[i];
s=i;
}
L[s]=rc;
}
void HeapSort(int *&L, int n){
for(int i=n/2; i>0; i--){
HeapAdjust(L, i, n);
}
for(int i=n; i>1; i--){
int temp=L[1];
L[1]=L[i];
L[i]=temp;
HeapAdjust(L, 1, i-1);
}
}
int main(){
int n;
long p;
cin>>n>>p;
int *L=new int[n+1];
for(int i=1; i<=n; i++)
cin>>L[i];
HeapSort(L, n);
int m=1;
for(int i=1; i<=n; i++)
while(i+m-1<=n && L[i+m-1]<=p*L[i]) m++;
cout<<m-1;
delete []L;
return 0;
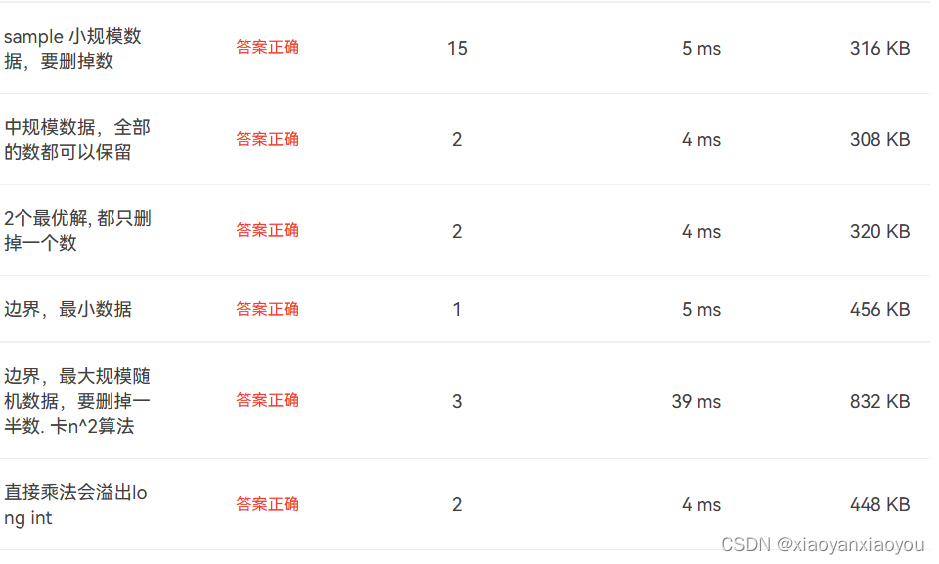
}
4. 归并排序
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
void Merge(int* L, int low, int mid, int high){
int* L2 = new int[high - low + 1];
int i = low, j = mid + 1, k = 0;
while (i <= mid && j <= high){
if (L[i] <= L[j]) L2[k++] = L[i++];
else L2[k++] = L[j++];
}
while (i <= mid){
L2[k++] = L[i++];
}
while (j <= high){
L2[k++] = L[j++];
}
k = 0;
for (int i = low; i <= high; i++){
L[i] = L2[k++];
}
delete[]L2;
}
void MergeSort(int* L, int low, int high){
if (low < high){
int mid = (low + high) / 2;
MergeSort(L, low, mid);
MergeSort(L, mid + 1, high);
Merge(L, low, mid, high);
}
}
int main(){
int n;
long p;
cin>>n>>p;
int *L=new int[n+1];
for(int i=1; i<=n; i++)
cin>>L[i];
MergeSort(L, 1, n);
int m=1;
for(int i=1; i<=n; i++)
while(i+m-1<=n && L[i+m-1]<=p*L[i]) m++;
cout<<m-1;
delete []L;
return 0;
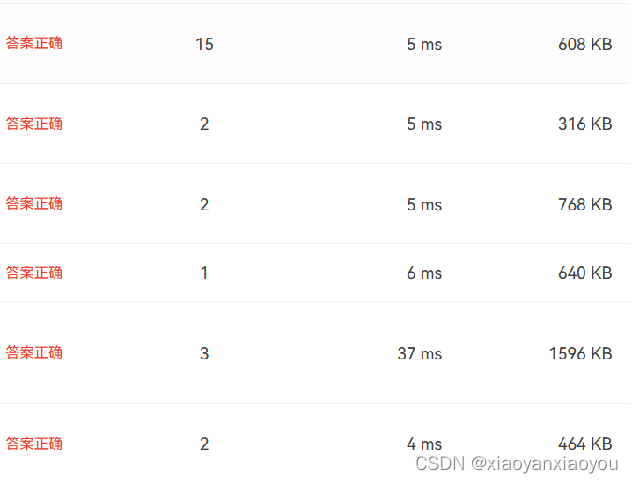
}
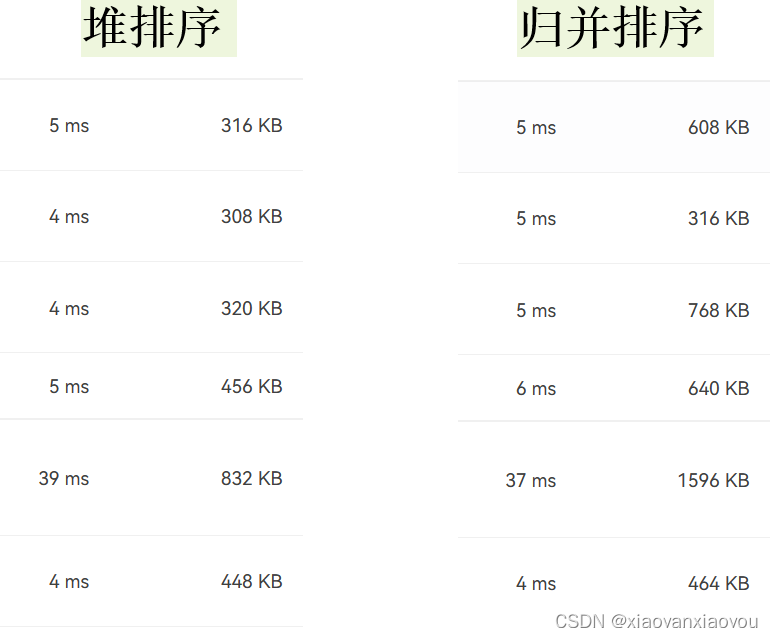
不过比较一下我们可以发现:
内存占用上,归并排序会偏大一些。
耗时上,堆排序普遍偏快,但在大规模数据的排序上还是归并排序更有优势。
5.sort函数
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
int main() {
int n, p, m=1;
scanf("%d %d", &n, &p);
int L[n];
for (int i=1; i<=n; i++) {
scanf("%d", &L[i]);
}
sort(L+1, L+n+1);
//for(int i=1; i<=n; i++){
for(int i=1; i<=n-m+1; i++){
while(i+m-1<=n && L[i+m-1]<=(long)p*L[i]) m++;
}
printf("%d\n", m-1);
return 0;
}
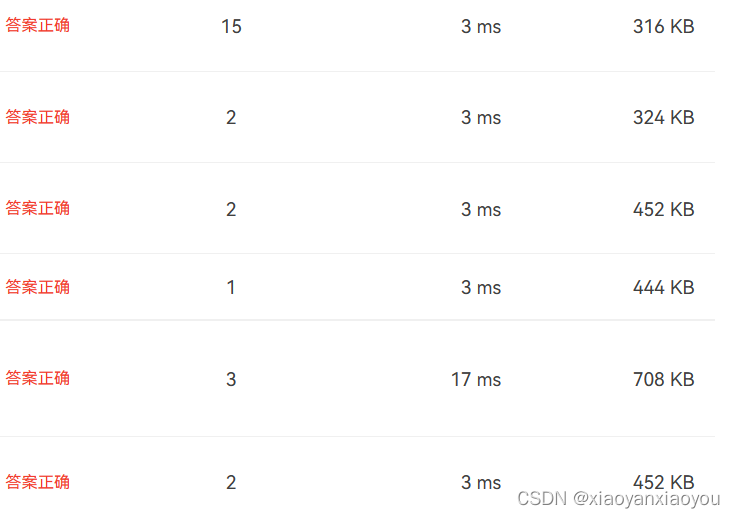
采用sort函数的话,代码的效率还能再提升一些。
除了排序函数,其他可以优化的地方还有找最长长度的部分。
除了如上采用的遍历查找,也可用 二分查找
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std; //二分查找
#define N 100010
int n, L[N];
int BinarySearch(int i, long x){
if(L[n]<=x) return n+1;
int low=i+1, high=n, mid;
while(low<high){
mid=(low+high)/2;
if(L[mid]<=x) low=mid+1;
else high=mid;
}
return low;
}
int main(){
int p;
scanf("%d%d", &n, &p);
for(int i=1; i<=n; i++)
scanf("%d", &L[i]);
sort(L+1, L+n+1);
int m=1;
for(int i=1; i<=n; i++){
int j=BinarySearch(i, (long)L[i]*p);
m=max(j-i, m);
}
cout<<m;
return 0;
}同样的效果也可用upper_bound函数实现
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std; //二分查找
#define N 100010
int main(){
int p, n, L[N];
scanf("%d%d", &n, &p);
for(int i=1; i<=n; i++)
scanf("%d", &L[i]);
sort(L+1, L+n+1);
int m=1;
for(int i=1; i<=n; i++){
int j=upper_bound(L+i+1, L+n+1, (long)L[i]*p) - L;
m=max(j-i, m);
}
cout<<m;
return 0;
}综上:
1. 解题方法就是先排序,后遍历,求最大完美序列长度。
2. 对于大规模数据排序,堆排序和归并排序都相对合适。
时间效率:堆排序平均较快,但在大规模数据的排序上,归并排序更有优势。
内存占用:归并排序较大。
3. 遍历时可用折半查找,这可以通过upper_bound函数实现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









