|
Python爬虫实战之爬取网站全部图片(一)
最新推荐文章于 2024-04-05 14:08:36 发布
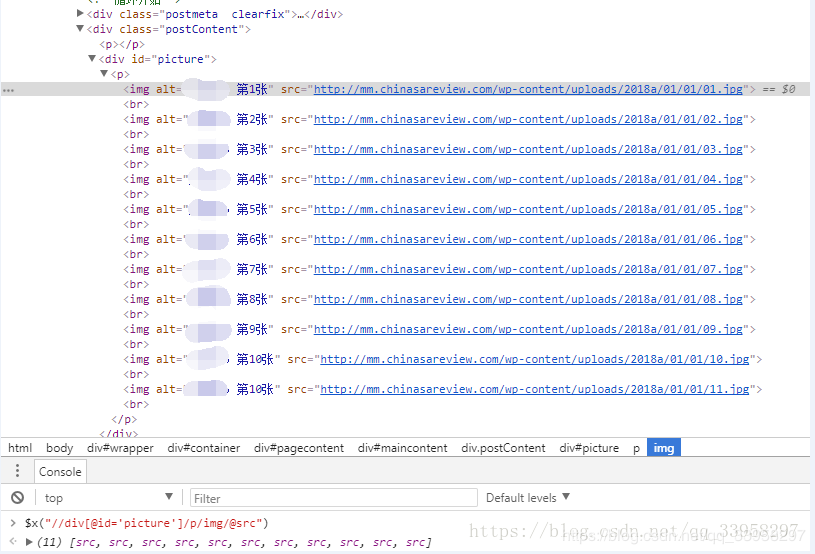
 本文详细介绍如何使用Python和相关库如Requests、lxml进行图片爬取,包括获取图片地址、图片名称,处理404错误及请求头信息。适用于初学者实践网络爬虫技术。
本文详细介绍如何使用Python和相关库如Requests、lxml进行图片爬取,包括获取图片地址、图片名称,处理404错误及请求头信息。适用于初学者实践网络爬虫技术。
本文详细介绍如何使用Python和相关库如Requests、lxml进行图片爬取,包括获取图片地址、图片名称,处理404错误及请求头信息。适用于初学者实践网络爬虫技术。
本文详细介绍如何使用Python和相关库如Requests、lxml进行图片爬取,包括获取图片地址、图片名称,处理404错误及请求头信息。适用于初学者实践网络爬虫技术。
|
 4063
4063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言