




 本文深入探讨了Spark的关键特性,包括Thrift服务部署框架、RabbitMQ消息传递系统、Spark任务提交参数详解、RDD持久化策略、Job与Stage执行机制、广播变量优化及DAG调度策略,为读者提供全面的Spark技术理解。
本文深入探讨了Spark的关键特性,包括Thrift服务部署框架、RabbitMQ消息传递系统、Spark任务提交参数详解、RDD持久化策略、Job与Stage执行机制、广播变量优化及DAG调度策略,为读者提供全面的Spark技术理解。
1.什么是Thrift 看了百科
Thrift是一个跨语言的服务部署框架,最初由Facebook于2007年开发,2008年进入Apache开源项目。
Thrift通过IDL(Interface Definition Language,接口定义语言)来定义RPC(Remote Procedure Call,远程过程调用)的接口和数据类型,
然后通过thrift编译器生成不同语言的代码(目前支持C++,Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, Smalltalk和OCaml),
并由生成的代码负责RPC协议层和传输层的实现。
2.在搜索为什么正好一次(Exactly-Once)传递是不可能的 发现了RabbitMQ
什么是RabbitMQ
未解答
3.spark-submit提交任务脚本
bin/spark-submit [options] <app jar | python file> [app options]
常见的options(标记列表)有更多
如:
--master 表示要连接的集群管理器。这个标记可接受的选项为
park://host:port 指定连接到指定端口的Spark独立集群上。默认情况下Spark独立主节点使用7077端口
mesos://host:port 连接到指定端口的Mesos集群上。默认情况下Mesos主节点监听5050端口
yarn 连接到一个YARN集群。当在YARN上运行时,需要设置环境变量HADOOP
local 运行本地模式,使用单核
local[N] 运行本地模式,使用N个核心
local[*] 运行本地模式,使用尽可能多的核心
--deploy-mode 选择在本地(客户端 "client")启动驱动器程序,还是在集群中的一台工作节点机器(集群“cluster”)上启动。在客户端模式下,spark-submit会将驱动器程序运行于spark-submit被调用的这台机器上。在集群模式下,驱动器程序会被传输并执行于集群的一个工作节点上。默认是本地模式。
--class 运行java或Scala程序时的主类
--name 应用的显示名,会显示在spark的网页显示界面中
--jars 需要上传并放到应用的CLASSPATH中的JAR包的列表。如果应用依赖于少量第三方的JAR包,可以把它们放在这个参数里
--files 需要放到应用工作目录的文件的列表。这个参数一般用来放需要分发到各节点的数据文件
--py-files 需要添加到PYTHONPATH中的文件的列表。其中可以包含.py、.egg、以及.zip文件
--total-executor-cores 总的核数
--executor-memory 执行器进程使用的内存量,以字节为单位。可以使用后缀指定更大的单位,比如"512m"(512MB) 或"15g"(15GB)
--driver-memory 驱动器进程使用的内存量,以字节为单位。可以使用后缀指定更大的单位,比如'512m'(512MB) 或"15g"(15GB)
4.spark中cache和persist的区别
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
可以看出cache底层调用的是persist,而且这里的Persist默认的存储级别是"MEMORY_ONLY"
persist呢
往上跟踪
/**
* Set this RDD's storage level to persist its values across operations after the first time
* it is computed. This can only be used to assign a new storage level if the RDD does not
* have a storage level set yet. Local checkpointing is an exception.
*/
def persist(newLevel: StorageLevel): this.type = {
if (isLocallyCheckpointed) {
// This means the user previously called localCheckpoint(), which should have already
// marked this RDD for persisting. Here we should override the old storage level with
// one that is explicitly requested by the user (after adapting it to use disk).
persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)
} else {
persist(newLevel, allowOverride = false)
}
}
将RDD的存储级别设置在第一次操作之后跨操作持久化其值,他是计算出来的。只有在RDD没有指定新存储级别的情况下,才可以使用它设置好存储级别。本地检查点是一个例外。
所在再往上追踪
/**
* Mark this RDD for persisting using the specified level.
*
* @param newLevel the target storage level
* @param allowOverride whether to override any existing level with the new one
*/
private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = {
// TODO: Handle changes of StorageLevel
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) {
throw new UnsupportedOperationException(
"Cannot change storage level of an RDD after it was already assigned a level")
}
// If this is the first time this RDD is marked for persisting, register it
// with the SparkContext for cleanups and accounting. Do this only once.
if (storageLevel == StorageLevel.NONE) {
sc.cleaner.foreach(_.registerRDDForCleanup(this))
sc.persistRDD(this)
}
storageLevel = newLevel
this
}
可以看到StorageLevel有12种缓存级别
/**
* Various [[org.apache.spark.storage.StorageLevel]] defined and utility functions for creating
* new storage levels.
*/
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
五个参数什么意思呢
@DeveloperApi
class StorageLevel private(
private var _useDisk: Boolean, //使用磁盘
private var _useMemory: Boolean, //使用内存
private var _useOffHeap: Boolean, //使用堆外缓存
private var _deserialized: Boolean, //反序列化
private var _replication: Int = 1) //备份数,默认是1
extends Externalizable { ...}
spark中job,stage,task之间的联系
job任务的task数量等于stage数量*task数量(job没有改变分区)
每一个stage中task的最大并行度:
理论上,每一个stage有多少分区就有多少的task,task的数量就是stage任务的最大的并行度(一般情况下,我们一个task运行的时候使用一个core)
实际上:最大的并行度取决于我们的application任务运行时的executor拥有的cores数量
具体讲的比较连贯的我推荐这个哥们写的-By-Morgan_Mu 传送门
task(任务):分发到executor上的工作任务,是spark实际执行任务的最小单元。
关于task的原理推荐这个-By-博客园-那一抹风-传送门
4.shuffle write发生在map端,为什么要发生writ操作:
1.为了避免大量的分区文件占用大流量的内存而导致OOM
2.保存到磁盘可以保证数据的安全性
5.比较鸡肋的jdbcRDD
看到注释就可以看到。只能查询,不能增删改
// TODO: Expose a jdbcRDD function in SparkContext and mark this as semi-private
/**
* An RDD that executes a SQL query on a JDBC connection and reads results.
* For usage example, see test case JdbcRDDSuite.
*
* @param getConnection a function that returns an open Connection.
* The RDD takes care of closing the connection.
* @param sql the text of the query.
* The query must contain two ? placeholders for parameters used to partition the results.
* For example,
* {{{
* select title, author from books where ? <= id and id <= ?
* }}}
* @param lowerBound the minimum value of the first placeholder
* @param upperBound the maximum value of the second placeholder
* The lower and upper bounds are inclusive.
* @param numPartitions the number of partitions.
* Given a lowerBound of 1, an upperBound of 20, and a numPartitions of 2,
* the query would be executed twice, once with (1, 10) and once with (11, 20)
* @param mapRow a function from a ResultSet to a single row of the desired result type(s).
* This should only call getInt, getString, etc; the RDD takes care of calling next.
* The default maps a ResultSet to an array of Object.
*/
class JdbcRDD[T: ClassTag](
sc: SparkContext,
getConnection: () => Connection,
sql: String,
lowerBound: Long,
upperBound: Long,
numPartitions: Int,
mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _)
extends RDD[T](sc, Nil) with Logging {...}
6.spark的两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable),累加器用来对信息进行聚合,而广播变量用来高效分发较大的对象。
暂时分析一下广播变量:
广播变量可以将Driver的某个变量的值以广播的形式传给Executor端,
Executor端在使用该值的时候就可以不仅过网络IO从Driver端获取,而是直接从本地的缓存读取该值。
这样既可以减少网络IO,又可以节省缓存(因为一个Executor只有一份广播变量就可以了)
广播过来的值会保存在Executor端的BlockManager
注意!:广播变量不可以广播RDD,因为RDD不会封装具体的值,只能广播确切的值,
广播变量不易太大,如果太大,会把Executor端的缓存占用太多而导致计算时内存太小而导致计算缓慢或者出现OOM
广播变量只能在Driver端定义,不能在Executor端定义。
优化:当广播一个较大的值时,选择一个既快又好的序列化格式是很重要的,因为序列化对性的时间很长或者传送时间花费的时间太久,这段时间就容易称为性能瓶颈。java Scala中默认使用的序列化库是Java序列化库,因此他对除基本类型的数组以外的任何对象都比较低效。可以使用spark.serializer 属性选择另一个序列化库来优化序列化过程(例如这个Kryo序列化库)
7.Lineage
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,他她可以根据这些信息来重新运算和恢复丢失的数据分区
8.DAG的生成
DAG(Directed Acylic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分为不同的Stage,对于窄依赖,partition的转换处理在stage中完成计算。对于宽依赖,由于有shuffle的存在,只能在parent RDD处理完之后,才能开始接下来的计算,因此宽依赖是划分stage的依据。
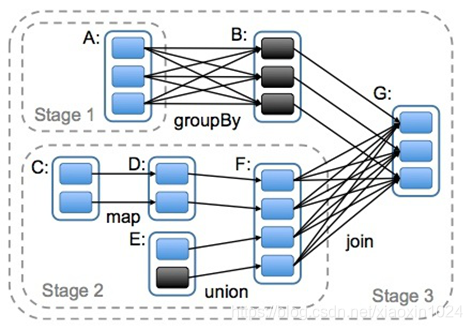

















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









