




 本文深入探讨Spark中RDD、DataFrame与DataSet的区别与联系,包括它们的惰性机制、缓存策略、操作特性及与SparkSQL的集成。通过实例演示自定义UDF与UDAF的使用,以及repartition与coalesce的功能差异。
本文深入探讨Spark中RDD、DataFrame与DataSet的区别与联系,包括它们的惰性机制、缓存策略、操作特性及与SparkSQL的集成。通过实例演示自定义UDF与UDAF的使用,以及repartition与coalesce的功能差异。
最近几篇写spark的文章若无特殊说明均基于spark2.0版本
文中用到的json文件点这里
First:RDD、DataFrame、DataSet的区别
博客园这位兄弟总结的不错-By-horseman-传送门
1.都是Spark平台下的分布式弹性数据集
2.三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算
3.三者都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
4.三者都有partition的概念
5.三者有许多共同的函数,如filter,排序等
6.在对DataFrame和Dataset进行操作许多操作都需要隐式转换这个包进行支持
7.DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型
区别:
1.RDD不支持sparksql操作
2.DataFrame与Dataset一般与spark ml同时使用
3.DataFrame与Dataset均支持sparksql的操作,比如select,groupby之类,还能注册临时表/视窗,进行sql语句操作
4.DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
5.Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同
DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段
1.在SparkSQL中使用自定义UDF 统计字符串长度
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 自定义UDF
* 需求:统计字符串长度
*/
object UDFDemo {
def main(args: Array[String]): Unit = {
//val conf = new SparkConf().setAppName("UDFDemo").setMaster("local")
//val spark = SparkSession.builder().config(conf).getOrCreate()
val spark = SparkSession
.builder()
.appName("HomeWork07_UDFDemo")
.master("local")
.getOrCreate()
//模拟数据
val names = List("tom", "jerry", "shuke")
val namesDF = spark.createDataFrame(names.map(Person))
//注册临时视图
namesDF.createOrReplaceTempView("t_person")
//注册自定义udf
spark.udf.register("strlen", (name: String) => name.length)
//调用udf进行查询
val res: DataFrame = spark.sql("select name as names, strlen(name) from t_person")
res.show()
// namesDF.show()
spark.stop()
}
}
case class Person(name: String)
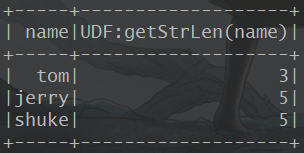
2.用UDAF实现单词统计
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
/**
* UDAF用于进行聚合操作
*/
class PersonWCUDAF extends UserDefinedAggregateFunction {
// 定义输入类型
override def inputSchema: StructType = {
StructType(Array(StructField("count", StringType, true)))
}
// 定义缓冲类型
override def bufferSchema: StructType = {
StructType(Array(StructField("count", IntegerType, true)))
}
// 定义输出类型(返回值的类型)
override def dataType: DataType = IntegerType
//是否是确定的 如果为true就代表返回值和输入的值是相同的
override def deterministic: Boolean = true
// 初始化操作方法,可以在这个方法中进行初始化值
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0
}
// 局部聚合(分区内的聚合),input指传进来的新值
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getAs[Int](0) + 1
}
// 全局聚合,buffer1 、buffer2代表各分区的聚合结果
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getAs[Int](0) + buffer2.getAs[Int](0)
}
// 在这个buffer中可以进行其他的操作,比如给他加某个值,或者给他截取等等操作
override def evaluate(buffer: Row): Any = buffer.getAs[Int](0)
}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 用UDAF实现单词统计
*/
object HomeWork07_UDAF {
def main(args: Array[String]): Unit = {
//模板代码
val spark: SparkSession = SparkSession
.builder()
.appName("HomeWork07_UDAF")
.master("local")
.getOrCreate()
//make data
val names = Array("yusheng", "moruo", "yusheng", "daima", "bosimiao", "daima")
val namesDF: DataFrame = spark.createDataFrame(names.map(Persons))
//注册临时表
namesDF.createOrReplaceTempView("t_person")
//注册UDAF
spark.udf.register("nice", new PersonsNiceUDAF)
//开始查询
val res: DataFrame = spark.sql("select name,nice(name) from t_person group by name")
res.show()
spark.stop()
}
}
case class Persons(name: String)
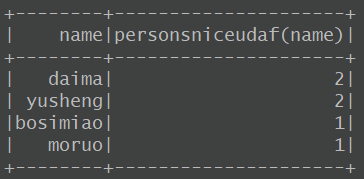
typed练习
以下写了几个:重分区:repartition coalesce
distinct dropDuplicates
executor filter
joinWith sort
collect_Set
collect_List
avg sum max min count countDistinct
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* typed练习
*/
object HomeWork07_TypedDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("HomeWork07_TypedDemo")
.master("local")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val employee: DataFrame = spark.read.json("d://temp/employee.json")
val employeeDS = employee.as[Employee1]
val employee2: DataFrame = spark.read.json("d://temp/employee2.json")
val employee2DS = employee2.as[Employee1]
val department = spark.read.json("d://temp/department.json")
val departmentDS = department.as[Department1]
println("初始化分区为" + employee.rdd.partitions.size)
// 重分区 ,repartition默认为shuffle,coalesce默认shuffle为false
val empRep: Dataset[Row] = employee.repartition(8)
val empCoa: Dataset[Row] = employee.coalesce(7)
println("repartition修改后的分区数:" + empRep.rdd.partitions.size)
println("coalesce修改后的分区数:" + empCoa.rdd.partitions.size)
//distinct dropDuplicates
//distinct按照整条数据进行完整对比进行去重
// dropDuplicates是根据指定的一个字段对比进行去重
employee.distinct().show()
employee.dropDuplicates(Array("name")).show()
// executor filter
//获取当前Datset中有但是另外一个dataSet中没有的元素
// 需要返回一个过滤逻辑,如果返回true,则保留该元素,否则就过滤掉
employeeDS.except(employee2DS).show()
employee2DS.filter(emp => emp.age > 30).show() // 过滤掉年龄小于30岁的
// joinWith sort
// sort 指定字段进行排序
employeeDS.joinWith(departmentDS, $"depId" === $"id").show()
employeeDS.sort($"age".desc).show()
// collect_Set 将指定字段的值都手机在一起 会按照这个字段进行去重
// collect_List 同上,但不会按照字段去重复
employee
.groupBy(employeeDS("depId"))
.agg(collect_set(employeeDS("name")), collect_set(employee("name")))
.show()
// avg sum max min count countDistinct
employee
.join(department, $"depId" === $"id")
.groupBy(department("name"))
.agg(avg(employee("salary")), sum(employee("salary")),
max(employee("salary")), min(employee("salary")),
count(employee("name")), countDistinct(employee("name")))
.show()
// umtype select * from any where
spark.stop()
}
}
case class Employee1(name: String, age: Long, depId: Long, gender: String, salary: Double)
case class Department1(id: Long, name: String)
3.repartition 和 coalesce的区别
作用:对RDD分区进行重新划分
repartition内部调用了coalesce,其中shuffle为true
举例子说明:
RDD有N个分区,需要把重新划分成M个分区
1.N少于M
一般情况下N个分区有数据不均匀的情况,利用HashPartition函数将分区重新分区为M个,这时需要把shuffle设置为true
2.N大于M且和M相差不多
假如N是1000,M是100,那么就可以将N分区中的若干个分区合并成一个新的分区,最终合并称成M个分区,这时候可以将Shuffle设置为false。在shuffle的情况下,如果M》N,coalesce是无效的,就是不进行shuffle过程,父RDD与子RDD之间是窄依赖关系
3.N 》M 且和M相差悬殊
这时如果将shuffle设置为false,父RDD和子RDD之间是窄依赖关系,在们在同一个stage中,可能会造成并行度不够,从而影响性能,如果M为1的时候,为了使coalesce之前的操作有更好的并行度,可以将shuffle设置为true
来自 博客园-流了个火
四:安装运行mangoDB
Windows安装还要手动添加服务进程,和mysql一样,不算难,网上也有很多教程。
五:kafka 安装 运行简单的命令
1.Kafka是什么:
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
2.了解下JMS
JMS是什么:JMS是Java提供的一套技术规范
JMS干什么用:用来异构系统 集成通信,缓解系统瓶颈,提高系统的伸缩性增强系统用户体验,使得系统模块化和组件化变得可行并更加灵活
通过什么方式:生产消费者模式(生产者、服务器、消费者)

六:抛疑问,为什么需要消息队列
消息系统的核心作用就是三点:解耦,异步和并行
。。。

















 1622
1622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









