







 本文解析了Spark为何被称为内存计算模型,并对比了Spark与MapReduce的不同之处,包括数据处理的效率提升、中间结果存储方式的变化及任务调度机制的改进。
本文解析了Spark为何被称为内存计算模型,并对比了Spark与MapReduce的不同之处,包括数据处理的效率提升、中间结果存储方式的变化及任务调度机制的改进。
1,spark为什么称为内存计算模型?
第一,不是说spark的数据都加载到内存中进行计算就是内存计算模型了,基于冯诺依曼架构,任何计算不都是加载到内存中计算么?
第二个,数据集太大的话,例如到PB级,目前任何内存也处理不了
第三,实则是spark会把一部分数据集的子集加载进内存,然后这其中的一部分中间计算的结果存放在内存,方便下一步的计算,而不是大量中间结果写到HDFS中
2,spark的计算过程
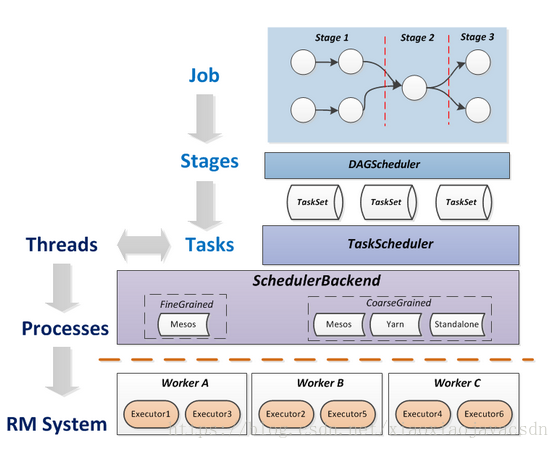
划分stage:对Task进行分类
ShuffleMapStage->Shuffle->ResultStage
Shuffle即是Reduce/GroupBy等操作
Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存。
3,spark解决mapreduce的问题,
- 抽象层次低,需要手工编写代码来完成,使用上难以上手。
- =>基于RDD的抽象,实数据处理逻辑的代码非常简短。。
- 只提供两个操作,Map和Reduce,表达力欠缺。
- =>提供很多转换和动作,很多基本操作如Join,GroupBy已经在RDD转换和动作中实现。
- 一个Job只有Map和Reduce两个阶段(Phase),复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的。
- =>一个Job可以包含RDD的多个转换操作,在调度时可以生成多个阶段(Stage),而且如果多个map操作的RDD的分区不变,是可以放在同一个Task中进行。
- 处理逻辑隐藏在代码细节中,没有整体逻辑
- =>在Scala中,通过匿名函数和高阶函数,RDD的转换支持流式API,可以提供处理逻辑的整体视图。代码不包含具体操作的实现细节,逻辑更清晰。
- 中间结果也放在HDFS文件系统中
- =>中间结果放在内存中,内存放不下了会写入本地磁盘,而不是HDFS。
- ReduceTask需要等待所有MapTask都完成后才可以开始
- => 分区相同的转换构成流水线放在一个Task中运行,分区不同的转换需要Shuffle,被划分到不同的Stage中,需要等待前面的Stage完成后才可以开始。
- 时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
- =>通过将流拆成小的batch提供Discretized Stream处理流数据。
- 对于迭代式数据处理性能比较差
- =>通过在内存中缓存数据,提高迭代式计算的性能。
4,mapreduce的天然优势
对机器的要求更低
超大规模的简单计算有优势
5,总结
其实,MapReduce和Spark不是来源于同一篇论文么?

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









