




问题现象
大模型推理过程中精度调优的目标是为了保障模型在昇腾平台上的推理能力,通常使用数据集校准或与标杆模型的输出进行比较的方式对模型的推理能力进行评估。在精度调优过程中,常见的精度问题主要有以下几种:
- 模型胡言乱语,无法正常对话。
- 模型与标杆在回答时存在语义偏差,或确定性问题的回答存在明显差异(例如判断题的结果)。
- 数据集评测不通过。
虽然常见问题的现象、根因各异,但都可以通过本文介绍的大模型推理精度问题快速分析方法进行定位分析。
定位流程
大模型推理精度问题定位流程如下图所示。
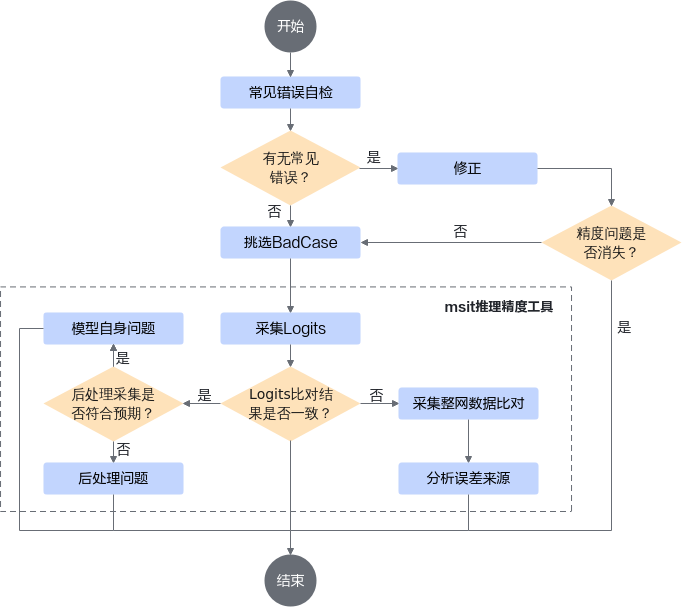
- 排查由于配置错误导致的精度问题,可通过检查模型配置、模型结构、传参以及自定义算子实现等进行排查。
- 如果配置无误,则选择存在明显精度问题的BadCase进一步分析定位。
- 开启确定性计算,采集模型输出的Logits。
- 将Logits和标杆数据进行比对。
- 如果比对结果一致,则排查“后处理”采样问题,进一步定位是模型自身问题还是“后处理”问题。
- 如果比对结果不一致,则采集模型输出异常处中间计算结果,逐层比对分析误差来源。
检查配置
模型配置
- 检查昇腾平台是否支持模型推理。昇腾平台基于MindIE推理框架适配了多种开源大模型,需要确认模型、设备、数据类型均配套且符合要求。如果需要了解MindIE支持的模型,请参见《MindIE模型支持列表》,支持的大语言模型请参见“大语言模型列表”。
- 检查模型加载的权重来源是否为同一文件。如果模型权重不一致,会直接导致推理计算存在差异,推理精度无法对齐。
- 检查模型配置文件,确认参数配置与标杆模型配置一致。常见的参数配置有pad_token_id、eos_token_id、max_sequence等,这些配置文件通常保存在模型权重路径下,可通过对齐config解决部分精度问题。
环境配置
如果模型在某一环境执行时精度正常,但在其他环境执行时精度异常,或更换软件版本后精度异常,则需要排查环境配置,需检查各个组件的版本是否一致,且和硬件环境适配,版本配套问题请查看《
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









