







文章目录
一、大模型服务的吞吐率太小怎么办?
-
备注
吞吐率 = 处理的请求数/处理需求的时间 -
解析
①分母是模型forward的时间(推理的时间) -》降低模型的推理延迟
②分子是一次处理的条数(batch size)和部署的服务器节点数量-》增大模型并行处理请求的能力 -
解决问题
①降低模型的推理延迟
1)减少计算量:权重+激活量化,若profile到服务的计算资源还有空余,比如GPU利用率还有
60%,也可以用投机采样来做,总体来说就是小模型猜测+大模型验证来做
2)提高访存利用率。若模型不是计算密集型,也就是计算速度大于访问内存速度,这时候瓶颈
主要是内存访问(self-attention大部分都是这种情况),所以要减少访问内存次数
②增强大模型的并行处理能力
1)在显存运行情况下,增加模型一次处理的batch size,静态、动态、连续batch
2)在业务允许情况下做水平扩展,增加节点数(还要调优:K8S+GPU利用监测+QLB负载均衡)
- 简单化的回答
①优化吞吐率最重要是模型处理的并行度,若增大batch size 会以10~30%的单词延时增加,换来数倍甚至数十倍的吞吐率加速-》continuous batching技术也就是迭代级调用
(原因:大模型服务不能假定固定长度的输入序列和输出序列,生成输出的变化可能导致GPU严重未充分利用,GPU不需要等所有序列完成才开始新的一个)
1)若是流式输出,则需要异步协程来实现资源的切换,实现在token粒度级别的多用户输出,tokenize和detokenize可用异步协程来实现
二、如何解决大模型的badcase?
- 方法集合
①进入模型前加一级或多级前置模块:用户问题会被逐级过滤和筛选,高频简单问题会优先处理(精度高、速度快、规则简单),比如当敏感词检测模型没拦住,可以加拒识模块,遇到问题可以及时hotfix
②加后处理:比如大模型常见幻觉问题,可以在后面加一个处理模块来二次过滤,根据不可控的内容来构建检索规则,直接对这种话术过滤删掉修复
③调prompt(特点是时间长,。一般不会很高效)
④模型微调优化(时间比较长,可能需要多次调优)
三、ollama的一些本地部署注意
四、说一下transformer原理(单字接龙)
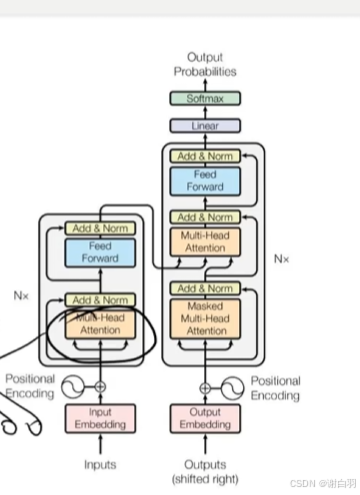
①把输出(例如中秋节吃什么)根据位置解码(positional endcoding)作为多维数字向量输入存在特征空间里面
②把汉字做线性回归linear,做softmax(概率最大的)的单个字作为输出,然后把这个字和之前的问题(例如中秋节吃什么)拼接起来再做下一个运算,得出概率最高的字作为输出
③编码器的作用:把文字的位置信息和问题映射到高维的语义空间里面去,输出一部分结合之前输出的文字一起运算后得出输出
④K矩阵:就是人类语言的输入经过编码器编程变为高维矩阵的语义空间,K矩阵就是语义空间的字典
⑤注意力机制到自注意力机制的转变:注意力机制类似于人类自我标注
五、LN和BN的区别
①都是对数据进行正规化,将输入数据归一至正态分布,加速训练收敛和稳定性
②BN:一个batch的向量,同一纬度的数据做正规化,但是不能处理变长数据
③LN:序列向量中,不同时刻的向量做正规化
六、如何选择RAG的embedding模型?
-
embedding的效果:
影响信息检索的效果和生成文本的质量 -
选择因素
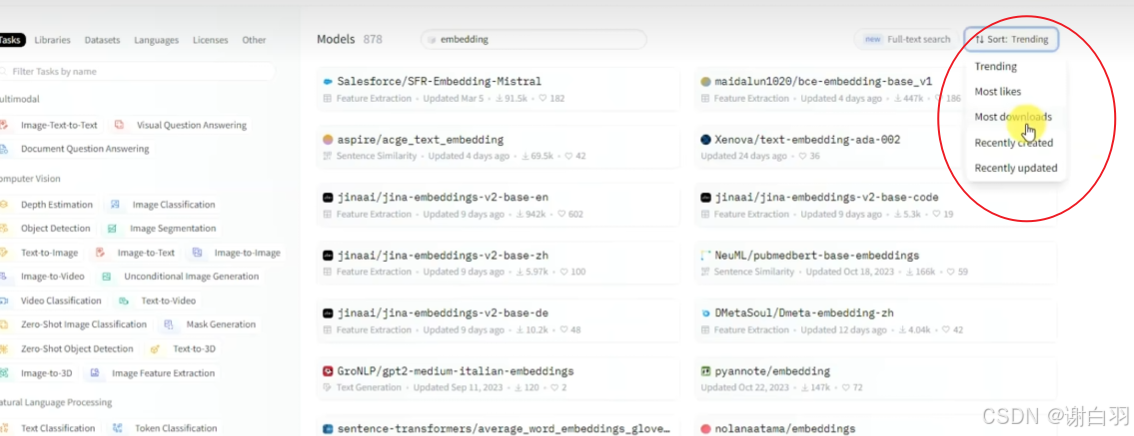
1)0huggingface趋势(最近下载量上升的模型)和下载量
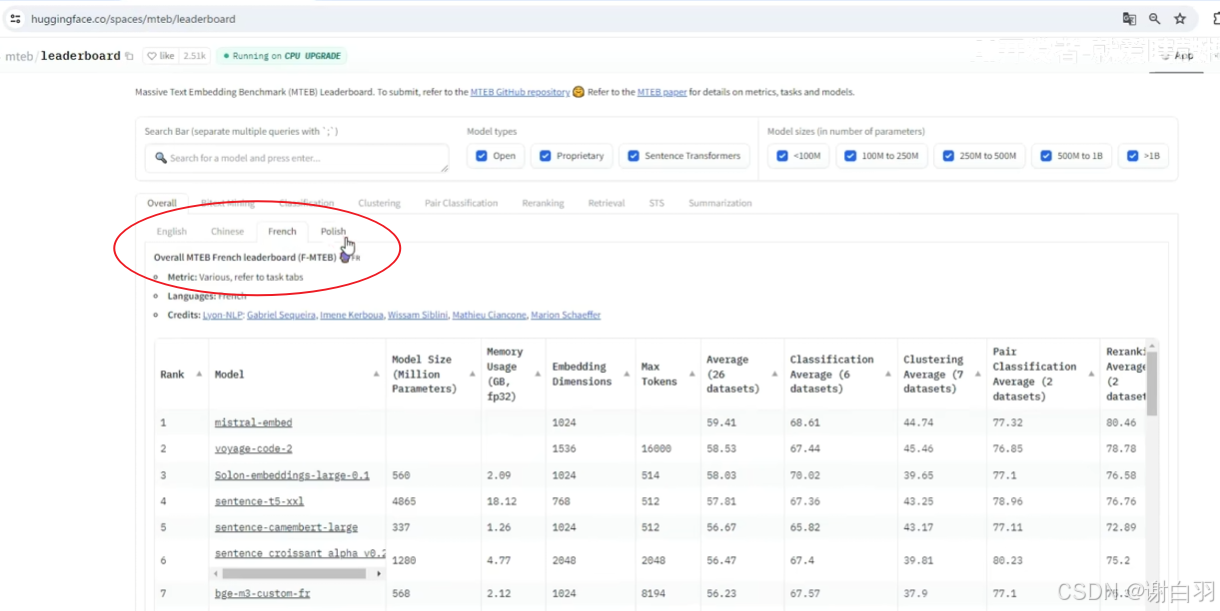
2)ETMB的排名
①趋势
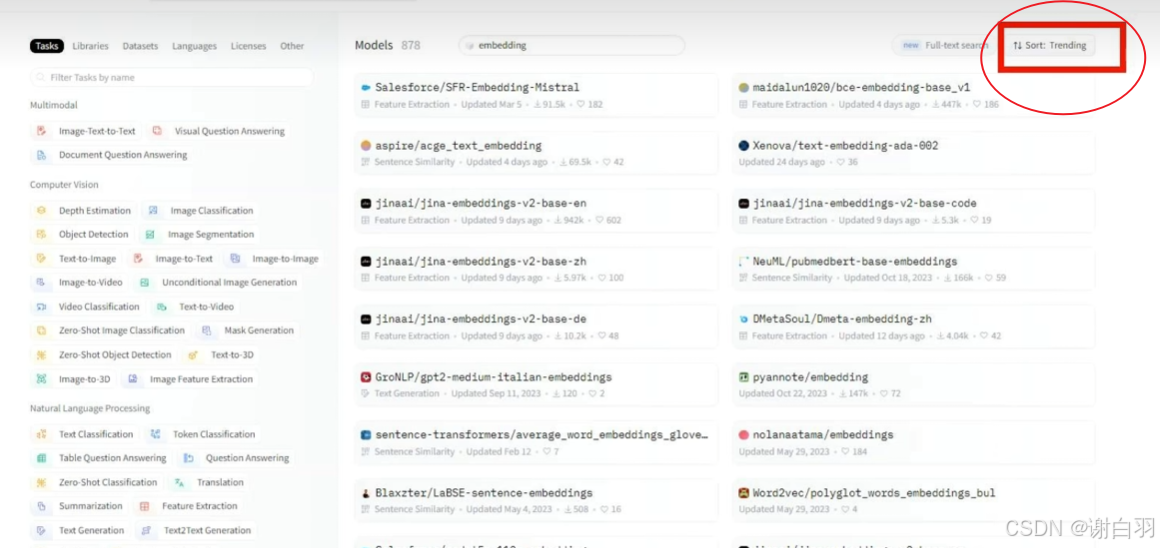
②下载量
③MTEB排行榜选择(根据语言)
七、如何选择以及为什么需要ReRank模型?
-
定义解释
ReRank模型就是对RAG检索返回的结果进行重新排序的模型 -
为什么需要rerank模型?
①因为切割文本形成的向量不可避免的存在确实信息的问题
②当文本太长时,大语言模型难以有效使用文本中间的信息,难总结
③过度填充上下文难以执行我们的指令
④对比不同的文本质量,提高召回率 -
如何选择ReRank模型?
①huggingface下载量
②QAnything实验对比结果

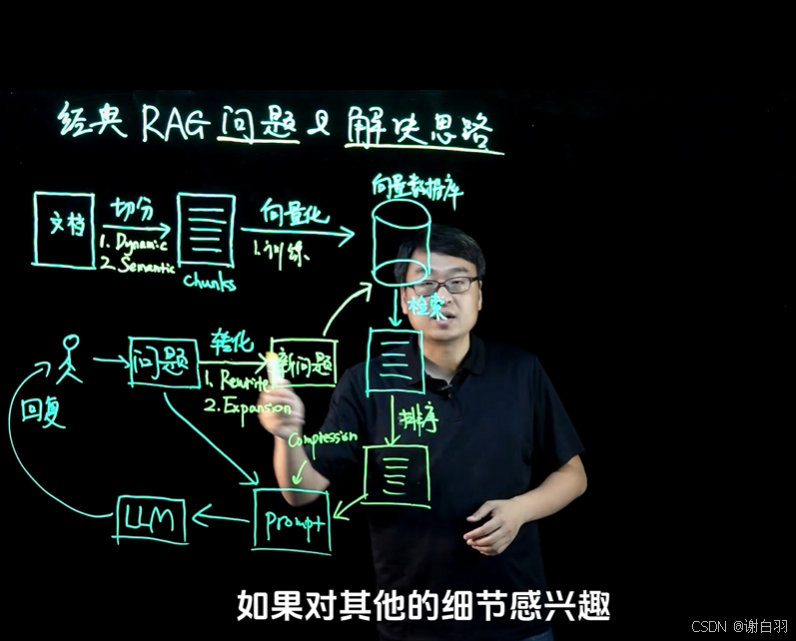
八、RAG是如何进行检索的?
1、使用 embedding 模型对文本进行 向量化处理
2、计算两个向量的 cosine距离作为相似度,对相似度排序后,来选择文本
九、RAG检索生成的效果不好,该如何优化?
方案1:选择使用更大的模型
llm = Ollama(model="qwen") #4b
llm = Ollama(model="qwen:14b")
llm = Ollama(model="qwen:72b")
方案2:embedding切分文档数据,采用评测效果好的模型,使用dynamic(随机交叉切割)或semantic(完整语义)
方案3:根据问题检索出来的片段进行rerank排序(采用评测效果好的模型),片段选出来后要进行compression压缩
方案4:客户的提问可能不清楚,需要rewrite重写优化和expansion有效扩充内容形成新问题
方案5:采用的模型可以做专门化的SFT微调,后面再根据客户返回做对齐Align(PPO/DPO)训练补齐
十、SFT指的什么,怎么拿到微调数据?
- SFT的微调格式
<Input输入,output标准答案>
- 对齐的数据格式
<input输入,accept可接受的答案,reject 决绝的答案>
-
标准答案来源
①人工专家标注给出答案 -
模型微调的步骤
①SFT去训练模型成SFT Model,把我们想要的东西告诉他
②将SFT Model 做对齐Alignment(PPO/DPO)成为Aligned Model,把不想要的东西也给他
(用户标记或是通过用户的日志来观察得出reject的答案)
十一、为什么现在大语言模型多用Decoder Only?
①工程应用上来说生成式任务做的出色,方便处理多轮对话
②Decoder Only是满秩的,表达能力更优,而encoder-decoder是低秩的
③KV-Cache:不需要再次重新计算之前的K和V,减少计算量;如果是e-d的话,还要跟单词之后的词做一些计算
④工程scale :训练多少的参数会有多少的效果,有实验支撑
十二、微调模型需要多少显存?
1)全参数(微调1B,16it)
①model weight(模型本身大小):2GB
②Gradient(计算梯度):跟①一样是GB,需要知道这个,我才知道模型接下来要怎么更新,也就是2GB
③optimize state:取决于用的优化器种类,例如Adam或SGD,一般是①的四倍,也就是8GB
④Activation:暂时略
总计合起来12GB
2)轻量化微调PEFT中的Lora
①model weight(模型本身大小):2GB
②(Gradient(计算梯度)+optimize state)x 2.5%=0.25GB
③Adapter :model weight x 0.25% = 0.05GB
总结起来就是2.3GB
十三、什么是自注意力机制?
1)例如句子: I hurt my back
2)每个单词都有多维度的向量表示
3)比如back,本身对自己的权重是60%,hurt对back权重是20%,my对back权重是15%。。。。那么就能得出back的一个加权平均值算到自己的向量里面表示back的含义,这个过程可能有多层

十四、什么是RLHF?(人类反馈强化学习)
其实就是在对齐的时候,有个奖励模型纠正经过SFT微调过的模型的行为

十五、幻觉的评估、幻觉体现和解决怎么做?
1)幻觉评估怎么做?
指标:
①生成式基准Generation :将幻觉视为生成特征,类似于流畅性和连贯性,对生成的文本进行评估
②区分式基准Discrimination:判别的是模型的真实陈述和幻觉陈述的能力,
链接
2)幻觉体现:

3)解决方法:
其他
1)如何通过ollama使用embedding模型?
Ollama可以支持Embedding模型。
https://ollama.com/blog/embedding-models
# 下载模型
ollama pull mofanke/acge_text_embedding
# 运行模型
from langchain_community.embeddings import OllamaEmbeddings
vectorstore = Chroma.from_documents(documents=splits, embedding=OllamaEmbeddings(model="mofanke/acge_text_embedding"))
2)如何使用Huggingface的Embedding模型?
# Embed
model_name = "maidalun1020/bce-embedding-base_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
vectorstore = Chroma.from_documents(documents=splits, embedding=hf)
https://api.python.langchain.com/en/latest/embeddings/langchain_community.embeddings.huggingface.HuggingFaceEmbeddings.html
3)如何使用Huggingface的LLM模型?
法一
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_id = "THUDM/chatglm3-6b"
tokenizer = AutoTokenizer.from_pretrained(model_id,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, device_map="auto")
pipe = pipeline(
"text-generation", model=model, tokenizer=tokenizer, max_new_tokens=2000
)
llm = HuggingFacePipeline(pipeline=pipe)
法二
from langchain.llms import HuggingFacePipeline
model_id = "THUDM/chatglm3-6b"
llm = HuggingFacePipeline.from_model_id(
model_id=model_id,
task="text-generation",
device=0,
model_kwargs={"temperature": 0.01, "max_length": 2000, "trust_remote_code": True},
)
# ?? 遗留问题:replace with device_map="auto" to use the accelerate library. (cannot work)
https://python.langchain.com/docs/integrations/llms/huggingface_pipelines/
4)如何修改RAG检索返回的文档数量?
只返回top K 个检索结果
retriever = db.as_retriever(search_kwargs={"k": 1})
5)向量数据库


















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









