







 超级会员免费看
超级会员免费看
 本文介绍如何通过Spark的Structured Streaming从Kafka流中读取数据,进行实时处理后,将结果写入MySQL数据库。内容涵盖MySQL建库建表、Structured Streaming应用程序编写、应用程序打包与提交到Spark集群的详细步骤。
本文介绍如何通过Spark的Structured Streaming从Kafka流中读取数据,进行实时处理后,将结果写入MySQL数据库。内容涵盖MySQL建库建表、Structured Streaming应用程序编写、应用程序打包与提交到Spark集群的详细步骤。
本篇文章在上一篇的基础上继续进行完善,使用Structured Streaming实时处理Kafka中的单词数据,并将处理结果写入到MySQL中。处理流程如图

MySQL建库建表
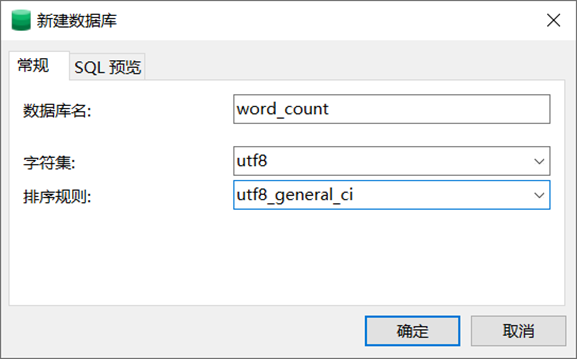
使用Navicat在MySQL中创建数据库word_count,并设置字符集为utf8,排序规则为utf8_general_ci,如图
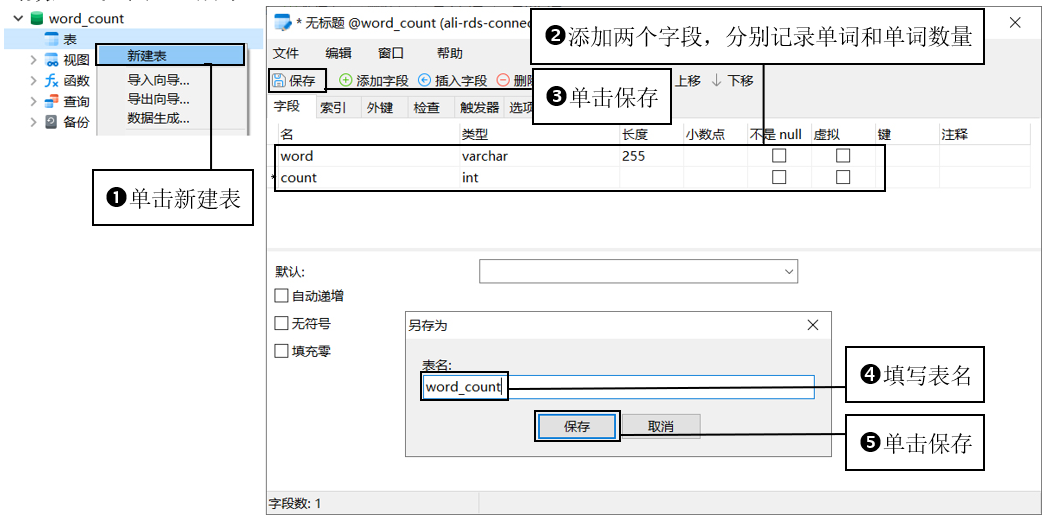
在数据库word_count中创建表word_count,并添加两个字段:word、count,分别代表单词和单词数量,如图
Structured Streaming应用程序编写
本节编写Structured Streaming应用程序,实时处理Kafka中的单词数据,并将处理结果写入到MySQL指定的表

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











