




 本文深入解析Spark中的Shuffle机制,包括其在作业执行中的作用、reduceByKey算子的执行流程,以及Hash-Based Shuffle和Sort Shuffle的运行机制。探讨了Shuffle过程中可能遇到的小文件过多、内存溢出等问题,并介绍了Spark如何通过优化机制解决这些问题。
本文深入解析Spark中的Shuffle机制,包括其在作业执行中的作用、reduceByKey算子的执行流程,以及Hash-Based Shuffle和Sort Shuffle的运行机制。探讨了Shuffle过程中可能遇到的小文件过多、内存溢出等问题,并介绍了Spark如何通过优化机制解决这些问题。
什么是Spark Shuffle
答案:每个Spark作业启动运行的时候,首先Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批Task,然后将这些Task分配到各个Executor进程中执行。一个stage的所有Task都执行完毕之后,在各个executor节点上会产生大量的文件,这些文件会通过IO写入磁盘(这些文件存放的时候这个stage计算得到的中间结果),然后Driver就会调度运行下一个stage。下一个stage的Task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到程序执行完毕,最终得到我们想要的结果。Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如groupByKey、countByKey、reduceByKey、join等等)每当遇到这种类型的RDD算子的时候,划分出一个stage界限来。(答案来自 链接:https://www.jianshu.com/p/069c37aad295 )
以reduceByKey为例
•reduceByKey的含义?
–reduceByKey会将上一个RDD中的每一个key对应的所有value聚合成一个value,然后生成一个新的RDD,元素类型是<key,value>对的形式,这样每一个key对应一个聚合起来的value
•问题:每一个key对应的value不一定都是在一个partition中,也不太可能在同一个节点上,因为RDD是分布式的弹性的数据集,他的partition极有可能分布在各个节点上。
•如何聚合?
–Shuffle Write:上一个stage的每个map task就必须保证将自己处理的当前分区中的数据相同的key写入一个分区文件中,可能会写入多个不同的分区文件中
–Shuffle Read:reduce task就会从上一个stage的所有task所在的机器上寻找属于自己的那些分区文件,这样就可以保证每一个key所对应的value都会汇聚到同一个节点上去处理和聚合
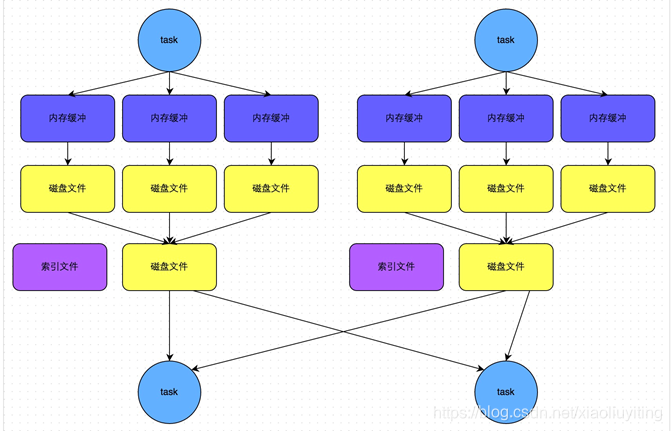
图解Hash-Based Shuffle
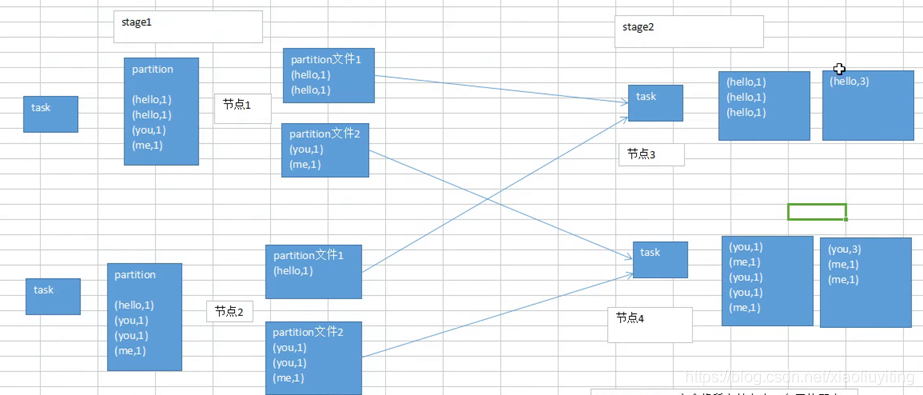
HashShuffle
1、普通机制
每一个map task都会产生R(reduce task的个数)个磁盘小文件,M个task会产生 M*R个磁盘小文件
磁盘小文件过多,影响
(1)写磁盘的时候,会产生大量的写文件对象
(2)读文件时会产生大量的读文件对象
(3)频繁的大量数据的通信
对象过多--》内存不足--》GC--》OOM
shuffle可能面临的问题?
•针对上图中Shuffle过程可能会产生的问题?
–小文件过多,耗时低效的IO操作
–OOM,读写文件以及缓存过多
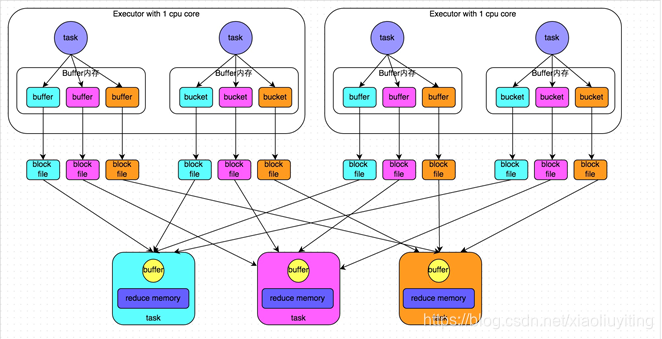
2、合并机制
每一个Executor(1 core)会产生R个磁盘小文件,磁盘小文件数=c*R
c代表core的数量,一个core一般给他分配2-3个task执行
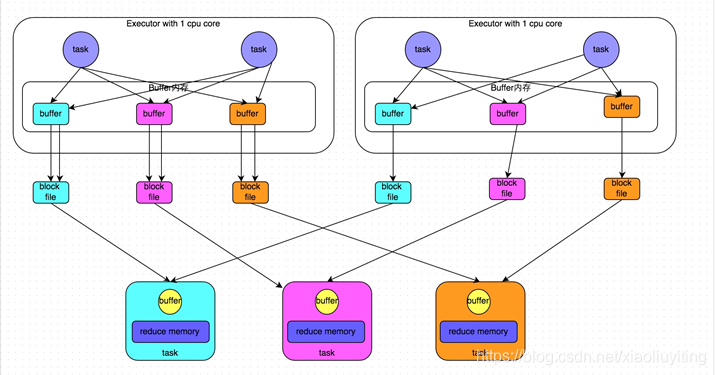
如何优化解决问题?
•优化后的HashShuffleManager
–优化后的HashShuffleManager的原理
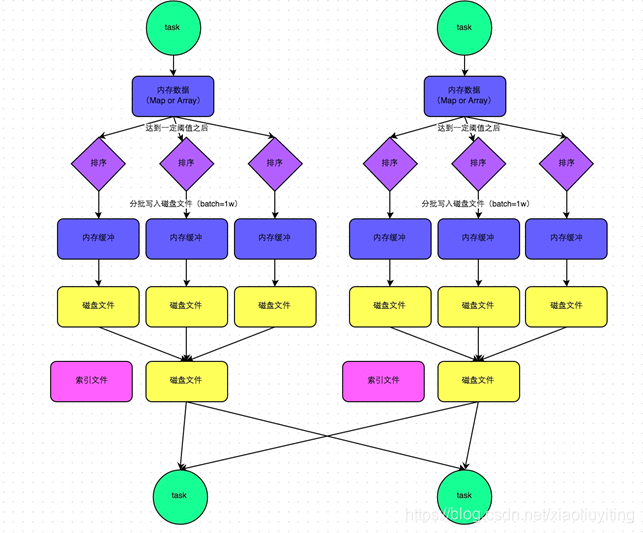
SortShuffle运行原理
•SortShuffle的运行机制主要分成两种:
–普通运行机制
–bypass运行机制
–
•SortShuffle两种运行机制的区别?
SortShuffleManager普通运行机制
SortShuffleManager bypass运行机制
bypass运行机制的触发条件如下:
shuffle reduce task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
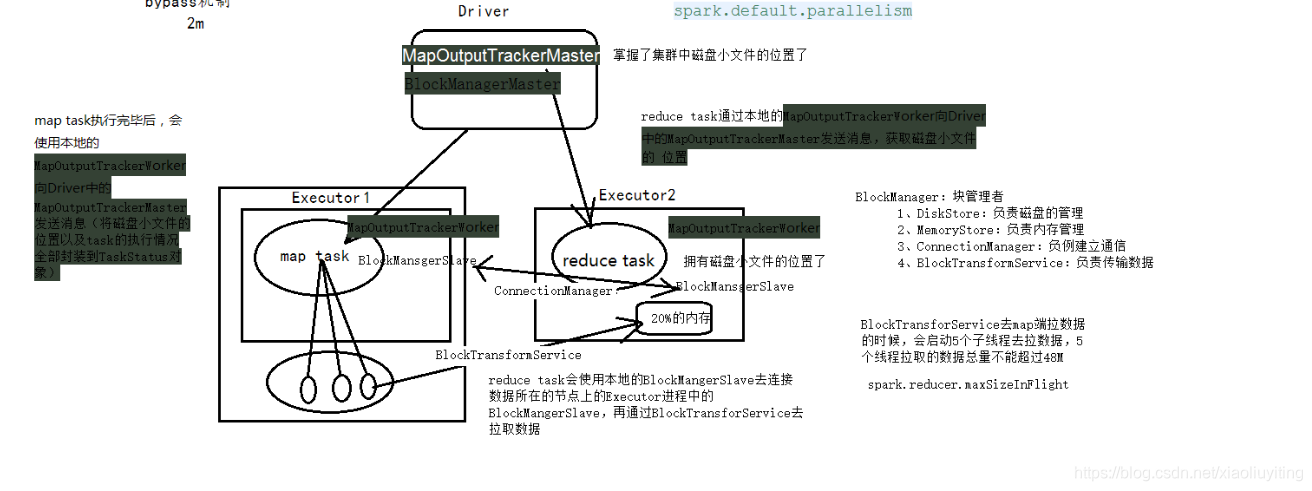
map task ,reduce task 流程图

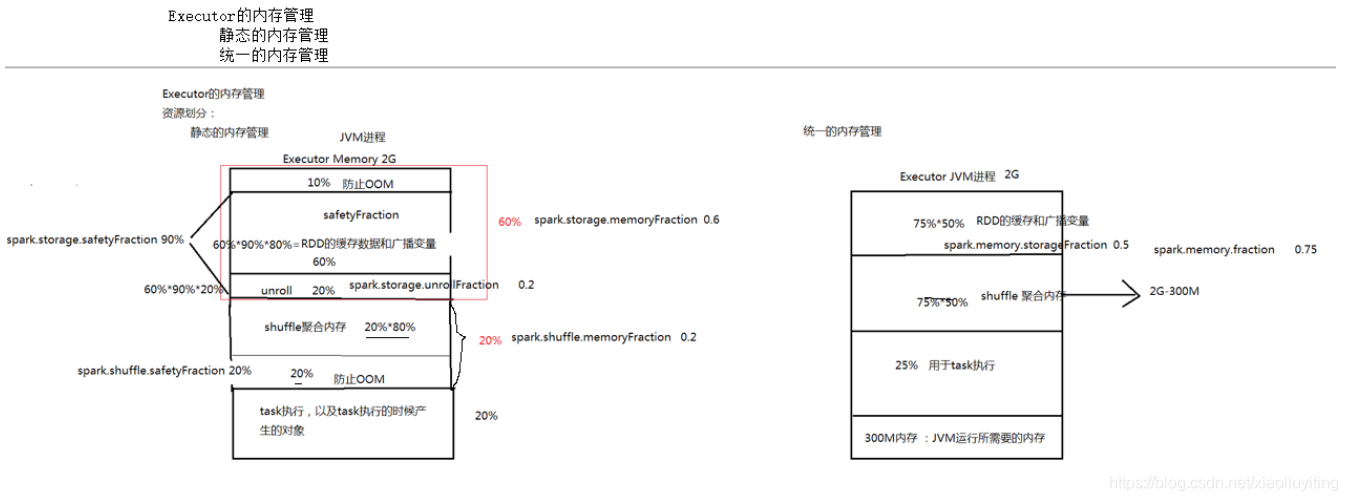
Executor的内存管理

















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









