




Shuffle,具有某种共同特征的一类数据需要最终汇聚(aggregate)到一个计算节点上进行计算。这些数据分布在各个存储节点上并且由不同节点的计算单元处理。以最简单的Word Count为例,其中数据保存在Node1、Node2和Node3;经过处理后,这些数据最终会汇聚到Nodea、Nodeb处理。
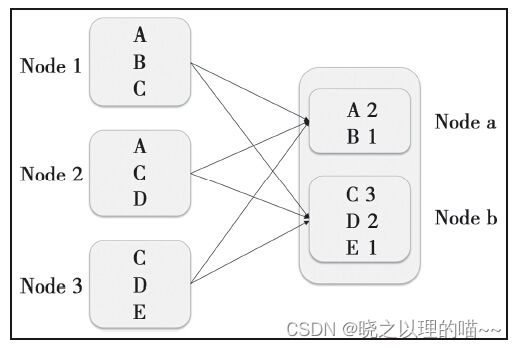
这个数据重新打乱然后汇聚到不同节点的过程就是Shuffle。但是实际上,Shuffle过程可能会非常复杂:
(1)数据量会很大,比如单位为TB或PB的数据分散到几百甚至数千、数万台机器上。
(2)为了将这个数据汇聚到正确的节点,需要将这些数据放入正确的Partition,因为数据大小已经大于节点的内存,因此这个过程中可能会发生多次硬盘续写。
(3)为了节省带宽,这个数据可能需要压缩,如何在压缩率和压缩解压时间中间做一个比较好的选择?
(4)数据需要通过网络传输,因此数据的序列化和发序列化也变得相对复杂。
一般来说,每个Task处理的数据可以完全载入内存(如果不能,可以减小每个Partition的大小),因此Task可以做到在内存中计算。除非非常复杂的计算逻辑,否则为了容错而持久化中间的数据是没有太大收益的,毕竟中间某个过程出错了可以从头开始计算。但是对于Shuffle来说,如果不持久化这个中间结果,一旦数据丢失,就需要重新计算依赖的全部RDD,因此有必要持久化这个中间结果。
一、Hash Based Shuffle Write
在很多运算场景中并不需要排序,多余的排序只能使性能变差,比如Hadoop的Map Reduce就是这么实现的,也就是Reducer拿到的数据都是已经排好序的。实际上Spark的实现很简单:每个Shuffle Map Task根据key的哈希值,计算出每个key需要写入的Partition然后将数据单独写入一个文件,这个Partition实际上就对应了下游的一个Shuffle Map Task或者Result Task。因此下游的Task在计算时会通过网络(如果该Task与上游的Shuffle Map Task运行在同一个节点上,那么此时就是一个本地的硬盘读写)读取这个文件并进行计算。
1,Basic Shuffle Writer实现解析
在Executor上执行Shuffle Map Task时,最终会调用org.apache.spark.scheduler.ShuffleMapTask的runTask。
主要逻辑:
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_<:Product2[Any, Any]]])return
writer.stop(success = true).get
(1)从SparkEnv中获得shuffleManager,就如前面提到的,Spark除了支持Hash和Sort Based Shuffle外,还支持external的Shuffle Service。用户可以通过实现几个类就可以使用自定义的Shuffle。
(2)从manager里取得Writer,在这里获得的是org.apache.spark.shuffle.hash.HashShuffleWriter。
(3)调用rdd开始运算,运算结果通过Writer进行持久化,逻辑在org.apache.spark.shuffle.hash.HashShuffleWriter#write。开始时通过org.apache.spark.Shuffle-Dependency是否定义了org.apache.spark.Aggregator来确定是否需要做Map端的聚合。然后将原始结果或者聚合后的结果通过org.apache.spark.shuffle.FileShuffleBlockManager#forMapTask的方法写入。写入完成后,会将元数据信息写入org.apache.spark.scheduler.MapStatus。然后下游的Task可以通过这个MapStatus取得需要处理的数据。
2,存在的问题
由于每个Shuffle Map Task需要为每个下游的Task创建一个单独的文件,因此文件的数量就是number(shuffle_map_task)*number(following_task)。如果Shuffle Map Task是1000,下游的Task是500,那么理论上会产生500000个文件(对于size为0的文件Spark有特殊的处理)。生产环境中Task的数量实际上会更多,因此这个简单的实现会带来以下问题:
(1)每个节点可能会同时打开多个文件,每次打开文件都会占用一定内存。假设每个Write Handler的默认需要100KB的内存,那么同时打开这些文件需要50GB的内存,对于一个集群来说,还是有一定的压力的。尤其是如果Shuffle Map Task和下游的Task同时增大10倍,那么整体的内存就增长到5TB。
(2)从整体的角度来看,打开多个文件对于系统来说意味着随机读,尤其是每个文件比较小但是数量非常多的情况。而现在机械硬盘在随机读方面的性能特别差,非常容易成为性能的瓶颈。如果集群依赖的是固态硬盘,也许情况会改善很多,但是随机写的性能肯定不如顺序写的。
3,Shuffle Consolidate Writer
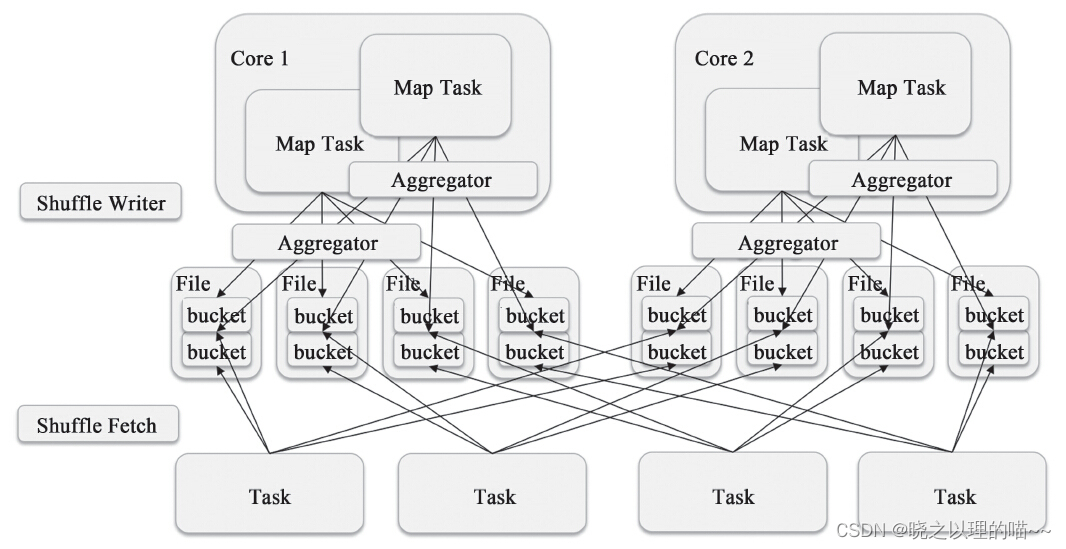
对于运行在同一个Core的Shuffle Map Task,第一个Shuffle Map Task会创建一个文件;之后的就会将数据追加到这个文件上而不是新建一个文件。因此文件数量就从number(shuffle_map_task)*number(following_task)变成了number(cores)*number(following_task)。当然,如果每个Core都只运行一个Shuffle Map Task,那么就和原来的机制一样了。但是Shuffle Map Task明显多于Core数量或者说每个Core都会运行多个Shuffle Map Task,所以这个实现能够显著减少文件的数量。
不同的org.apache.spark.shuffle.FileShuffleBlockManager#forMapTask#writers的实现:
val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) {
fileGroup = getUnusedFileGroup() //获得没有使用的FileGroup
Array.tabulate[BlockObjectWriter](numBuckets) {
bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializer,
bufferSize,
writeMetrics)
}
} else {
// Basic Shuffle Writer的实现
org.apache.spark.shuffle.FileShuffleBlockManager.ShuffleFileGroup可以理解成一个文件组,这个文件组的每个文件都对应一个Partition或者下游的Task。因此对第一个Shuffle Map Task来说,它创建了一个文件;而接下来的Shuffle Map Task都是以追加的方式写这个文件。
blockManager.getDiskWriter为每个文件创建一个org.apache.spark.storage.DiskBlock-ObjectWriter,DiskBlockObjectWriter可以直接向一个文件写入数据,如果文件已经存在那么会以追加的方式写入。
但是下游的Task如何区分文件不同的部分呢?在同一个Core上运行Shuffle Map Task相当于写了这个文件的不同的部分。答案就在org.apache.spark.shuffle.FileShuffleBlockManager.ShuffleFileGroup#getFileSegmentFor。
二、Shuffle Pluggable框架
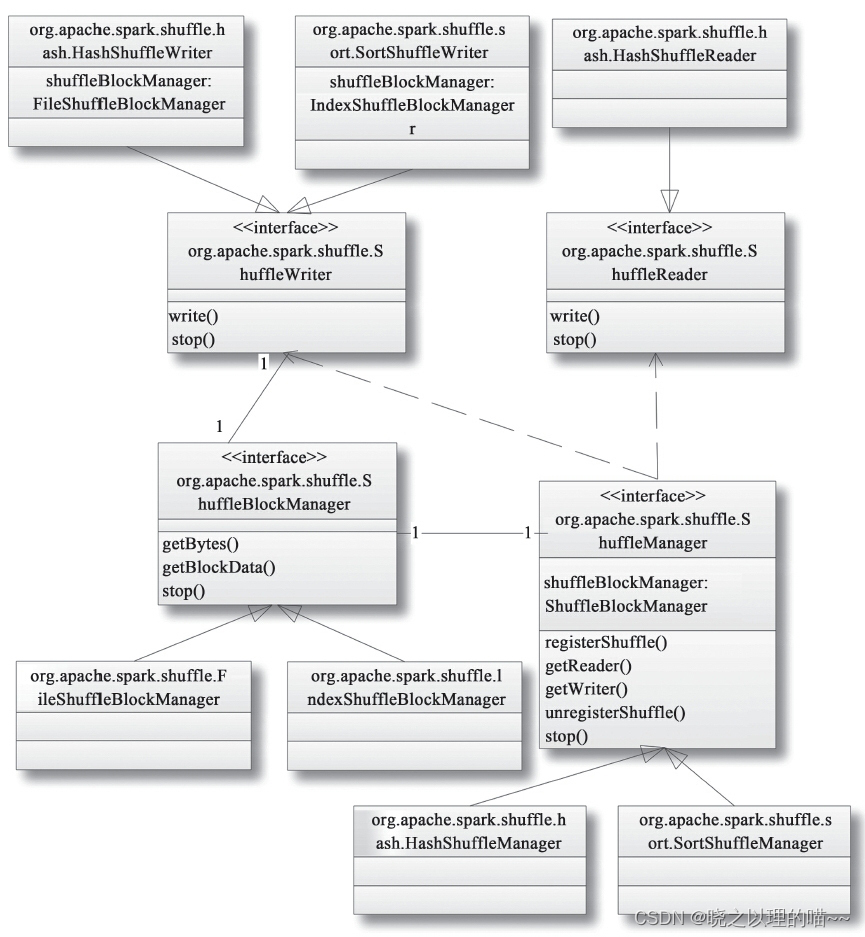
1,org.apache.spark.shuffle.ShuffleManager
Driver和每个Executor都会持有一个ShuffleManager,这个ShuffleManager可以通过配置项spark.shuffle.manager指定,并且由SparkEnv创建。Driver中的ShuffleManager负责注册Shuffle的元数据,比如shuffleId、Map Task的数量等。Executor中的ShuffleManager则负责读和写Shuffle的数据。
需要实现的函数及其功能说明如下:
(1)由Driver注册元数据信息
def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle
一般如果没有特殊的需求,可以使用下面的实现,实际上Hash Based Shuffle和Sort Based Shuffle都是这么实现的。
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
new BaseShuffleHandle(< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1441
1441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











