




 本文探讨了sigmoid函数在神经网络中的作用及局限性,并介绍了通过BatchNormalization缓解梯度消失问题的方法,同时提出了一种改进的激活函数以提高输出的区分度。
本文探讨了sigmoid函数在神经网络中的作用及局限性,并介绍了通过BatchNormalization缓解梯度消失问题的方法,同时提出了一种改进的激活函数以提高输出的区分度。
1、sigmoid函数及其应用
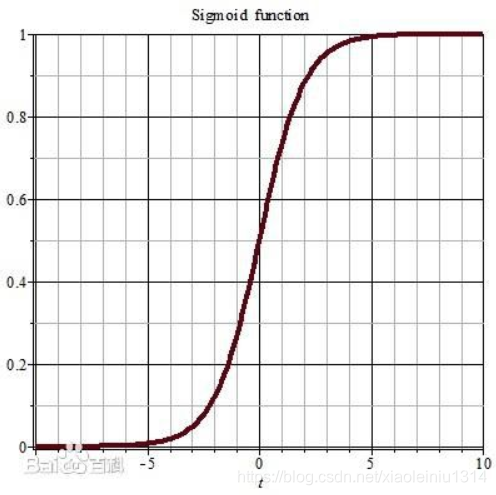
图1:sigmoid 函数
如图1为sigmoid函数,它是神经网络中的一种激活函数,可以将输出限制在(0,1)范围内。目前我能想到的sigmoid函数在神经网络中的两种应用是:
a、 作为神经网络中间层的一个激活函数,对于这种应用而言,sigmoid函数有两个特性是重要的,一是输出在(0,1)之间,二是非线性;
b、 对于回归任务,在网络的最后一层将数据框定在(0,1)之间,对于这种应用而言,似乎更关注于sigmoid函数的输出在(0,1)之间这个特性,而其非线性特性就显得不那么必要;
2、sigmoid函数饱和区带来的问题
所谓sigmoid函数的饱和区,是指图1中左下角和右上角的平缓区域。相对于第1小节提到的sigmoid函数的两种应用,饱和区(平缓区域)会带来以下问题:
a、 梯度消失问题(平缓区梯度几乎为0),这个问题对于sigmoid函数的两种应用都是存在的;
b、 对于输入x,输出y的区分度不高,这个问题主要针对第二种应用;
3、如何解决sigmoid函数饱和区问题
针对第2小节提出的a问题,一种解决方法是在sigmoid层之前引入Batch Normalization层。批规范化(Batch Normalization,BN)方法(实现见图2),就是对每个神经元的输出规范化,即均值为 0,方差为 1,之后再进入激活函数。每一层规范化后,输出就以极大的概率落在靠近中心的区间,如 [-1, 1],这时sigmoid函数的梯度变化很大,也就解决了梯度消失的问题。
但是这样做又有一个缺点,可以看到图1中sigmoid 函数[-1, 1] 这段区间近似直线,也就是激活函数变成了线性的,所以整个网络绝大多数就都是线性表达,降低了神经网络的表达能力。所以BN的作者又再次引入了两个变量(图2最后一行中的γ\gammaγ和β\betaβ),对规范化后的神经元输出做了一次线性映射,参数也是可以学习的,使得最终输出落在非线性区间的概率大一些。这样就在 sigmoid 函数梯度小和线性表达之间做了一个平衡,使得神经网络有了非线性变换,保证了其学习能力,也使梯度比较大,加快了训练速度。

图2:Batch Normalization 具体实现
针对第2小节提出的b问题,我们可以将激活函数由sigmoid更换为下图的函数(自己想的,暂且叫做similar-ReLU吧)。简单的解释下这个函数,输入小于0的,强制为0,输入大于1的,强制为1,输入位于(0,1)之间的,输出不变。这样就使得输出在(0,1)之间的值有了区分度。
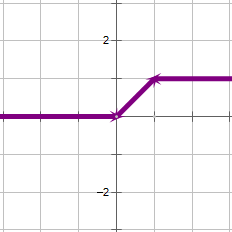
图3:similar-ReLU 函数

















 214
214




 到【灌水乐园】发言
到【灌水乐园】发言







