









Kafka 入门学习简介
1. kafka是什么
- Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications
- 官网http://kafka.apache.org/
- 就是一个开源,分布式消息缓存框架,基于日志,高吞吐,数据分区容错性的框架。
- 特点
1.解耦:
允许你独⽴的扩展或修改两边的处理过程,只要确保它们遵守同样的接⼝约束。
2.冗余:
消息队列把数据进⾏持久化直到它们已经被完全处理,通过这⼀⽅式规避了数据丢失⻛险。许多消息队
列所采⽤的"插⼊-获取-删除"范式中,在把⼀个消息从队列中删除之前,需要你的处理系统明确的指出该消
息已经被处理完毕,从⽽确保你的数据被安全的保存直到你使⽤完毕。
3.扩展性:
因为消息队列解耦了你的处理过程,所以增⼤消息⼊队和处理的频率是很容易的,只要另外增加处理过
程即可。
4.灵活性 & 峰值处理能⼒:
在访问量剧增的情况下,应⽤仍然需要继续发挥作⽤,但是这样的突发流量并不常⻅。如果为以能处理
这类峰值访问为标准来投⼊资源随时待命⽆疑是巨⼤的浪费。使⽤消息队列能够使关键组件顶住突发的访问
压⼒,⽽不会因为突发的超负荷的请求⽽完全崩溃。
5.可恢复性:
系统的⼀部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使⼀个处理
消息的进程挂掉,加⼊队列中的消息仍然可以在系统恢复后被处理。
6.顺序保证:
在⼤多使⽤场景下,数据处理的顺序都很重要。⼤部分消息队列本来就是排序的,并且能保证数据会按
照特定的顺序来处理。(Kafka 保证⼀个 Partition 内的消息的有序性)
7.缓冲:
有助于控制和优化数据流经过系统的速度,解决⽣产消息和消费消息的处理速度不⼀致的情况。
8.异步通信:
很多时候,⽤户不想也不需要⽴即处理消息。消息队列提供了异步处理机制,允许⽤户把⼀个消息放⼊
队列,但并不⽴即处理它。想向队列中放⼊多少消息就放多少,然后在需要的时候再去处理它们。
- 概念
1.producer:
消息⽣产者,发布消息到 kafka 集群的Borker(下⾯的Leader分区)。
2.broker:
kafka 集群中安装Kafka的服务器(容器),broker要有唯⼀的ID。
3.topic:
每条发布到 kafka 集群的消息属于的类别,即 kafka 是⾯向 topic 的(相当于数据库中的表)
4.partition:
partition 是物理上的概念,每个 topic 包含⼀个或多个 partition。kafka 分配的单位是
partition。
5.consumer:
从 kafka 集群中消费消息的终端或服务。
6.Consumer group:
high-level consumer API 中,每个 consumer 都属于⼀个 consumer group,每条消息只能被
consumer group 中的⼀个 Consumer 消费,但可以被多个 consumer group 消费。
7.replica:
partition 的副本,保障 partition 的⾼可⽤。
8.leader:
replica 中的⼀个⻆⾊, producer 和 consumer 只跟 leader 交互。
9.follower:
replica 中的⼀个⻆⾊,从 leader 中复制数据。
10.zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息
1.Kafka的⽣产者直接向Broker的Leader分区写⼊数据,不需要连接ZK
2.Kafka的消费者(⽼的API需要先连接ZK,获取Broker信息和topic、分区偏移量信息),新的API不需要
连接ZK(直连⽅式,新的API,底层的API,效率更⾼)
2. kafka如何安装
- 安装zookeeper
- 安装Kafka集群
上传Kafka安装包
解压
修改配置⽂件
vi servier.properties
#指定broker的id
broker.id=1 #数据存储的⽬录
log.dirs=/data/kafka
#指定zk地址
zookeeper.connect=doit01:2181,doit02:2181,doit03:2181
#可以删除topic的数据(⽣成环境不⽤配置)
#delete.topic.enable=true
将配置好的kafka拷⻉的其他节点
修改其他节点Kafka的broker.id
- 启动zk
/bigdata/zookeeper-3.4.13/bin/zkServer.sh start
/bigdata/zookeeper-3.4.13/bin/zkServer.sh status
- 在所有节点启动Kafka
/doit/kafka_2.12-2.4.1/bin/kafka-server-start.sh -daemon /bigdata/kafka_2.12-
2.4.1/config/server.properties
- 查看Kafka进程信息
jps
3. kafka如何使用
- 查看Kafka的topic
/doit/kafka_2.12-2.4.1/bin/kafka-topics.sh --list --zookeeper localhost:2181
- 创建topic
/doit/kafka_2.12-2.4.1/bin/kafka-topics.sh --zookeeper localhost:2181 --create --
topic wordcount --replication-factor 3 --partitions 3
- 启动⼀个⽣产者命令⾏客户端
/doit/kafka_2.12-2.4.1/bin/kafka-console-producer.sh --broker-list doit01:9092,doit02:9092,doit03:9092 --topic wordcount
- 启动⼀个消费者命令⾏客户端
/doit/kafka_2.12-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server doit01:9092,doit02:9092,doit03:9092 --topic wordcount --
from-beginning
–from-beginning 消费以前产⽣的所有数据,如果不加,就是消费消费者启动后产⽣的数据
- 删除topic
/doit/kafka_2.12-2.4.1/bin/kafka-topics.sh --delete --topic wordcount --zookeeper
localhost:2181
- 查看topic详细信息
/doit/kafka_2.12-2.4.1/bin/kafka-topics.sh --zookeeper localhost:2181 --describe --
topic wordcount
- 查看某个topic的偏移量
/doit/kafka_2.12-2.4.1/bin/kafka-console-consumer.sh --topic __consumer_offsets --
bootstrap-server doit01:9092,doit02:9092,doit03:9092
--formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --
consumer.config /bigdata/kafka_2.12-2.4.1/config/consumer.properties --from-beginning
4. kafka内部机制
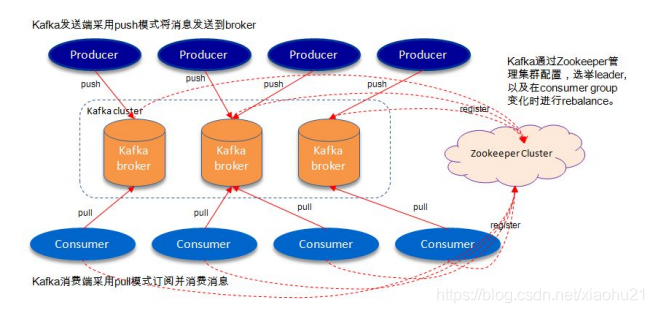
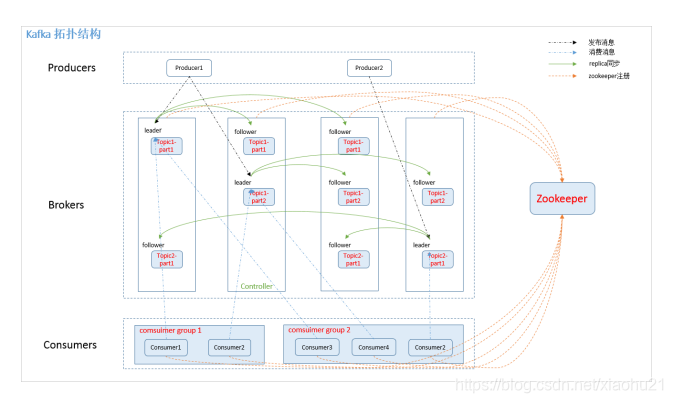
5. kafka使用注意事项(踩坑点)
- kafka的参数配置,如日志,日志存储时间,分区数,主题,消费者组等
- kafka版本选择,尽量选择高版本,支持被压,直连机制
- kafka压测,需要测试kafka集群的吞吐能力
- kafka监控,需要知道集群本身的状态和实时情况
- 版本和数仓架构中框架兼容性,目前这些都有成熟匹配的框架版本号,尽量小版本号也一致,防止版本冲突或者出问题。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









