




 本文介绍了如何在Google Colab环境中使用AlphaFold2进行蛋白质结构预测,包括Google Colab的介绍、代码下载、关键步骤分析和预测结果可视化。
本文介绍了如何在Google Colab环境中使用AlphaFold2进行蛋白质结构预测,包括Google Colab的介绍、代码下载、关键步骤分析和预测结果可视化。
2021SC@SDUSC
前言
今天尝试在google colab快速跑通Alphafold2的简易版,进行蛋白质预测初体验
一、Google Colab介绍
Google Colab是一个免费的 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行。并且可以免费使用Google的GPU 。Google Colab可以将你的Jupyter 笔记本存储在Google的云端硬盘当中,借助 Google Colab,可以在云端编写和执行代码、保存和共享分析结果,以及利用强大的计算资源,所有这些都可通过浏览器免费使用。
有关Google colab使用可以参考:
https://zhuanlan.zhihu.com/p/54389036
二、代码地址
这里用了Sergey Ovchinnikov 提供的“alphafold_single_sequence.ipynb”的代码
代码地址:
https://colab.research.google.com/drive/1PePaHHp1J-L1rufW4_r7v7VpZjYVUbTH#scrollTo=pxALY3Gh_SZj
三、代码分析
(1)先是导入和安装各种库
%%bash
git clone https://github.com/deepmind/alphafold.git
mv alphafold alphafold_
mv alphafold_/alphafold .
上图是克隆一个 Git 仓库到本地,并且切换到,切换到alphafold 目录下
%%bash
wget -qnc https://storage.googleapis.com/alphafold/alphafold_params_2021-07-14.tar
tar -xf alphafold_params_2021-07-14.tar
rm alphafold_params_2021-07-14.tar
mkdir params
mv params_* params/
上图是下载一个alphafold模型,将其解压,再删除原先的压缩包,创建新的目录
%%bash
pip -q install biopython
pip -q install dm-haiku
pip -q install ml-collections
pip -q install mock
pip -q install py3Dmol
from typing import Dict
import os
import mock
import numpy as np
import pickle
import py3Dmol
上面两张图是安装引用各种需要的工具模块
from alphafold.common import protein
from alphafold.data import pipeline
from alphafold.data import templates
from alphafold.model import data
from alphafold.model import config
from alphafold.model import model
上图是从alphafold.common中引入protein,从alphafold.data中引入pipeline、templates,从alphafold.model中引入data、config、model



(2)定义一个结构预测函数
def predict_structure(
fasta_path: str,
fasta_name: str,
output_dir_base: str,
data_pipeline: pipeline.DataPipeline,
model_runners: Dict[str, model.RunModel],
random_seed: int):
"""Predicts structure using AlphaFold for the given sequence."""
output_dir = os.path.join(output_dir_base, fasta_name)
if not os.path.exists(output_dir): os.makedirs(output_dir)
msa_output_dir = os.path.join(output_dir, 'msas')
if not os.path.exists(msa_output_dir): os.makedirs(msa_output_dir)
# 得到features
feature_dict = data_pipeline.process(input_fasta_path=fasta_path, msa_output_dir=msa_output_dir)
# 这里是要运行model.
for model_name, model_runner in model_runners.items():
processed_feature_dict = model_runner.process_features(feature_dict, random_seed=random_seed)
prediction_result = model_runner.predict(processed_feature_dict)
unrelaxed_protein = protein.from_prediction(processed_feature_dict, prediction_result)
unrelaxed_pdb_path = os.path.join(output_dir, f'unrelaxed_{model_name}.pdb')
with open(unrelaxed_pdb_path, 'w') as f:
f.write(protein.to_pdb(unrelaxed_protein))
其中
fasta_path:预测蛋白质fasta文件的路径
fasta_name:预测蛋白质fasta文件的名字
output_dir_base:保存到的路径
data_pipeline.process(input_fasta_path=fasta_path, msa_output_dir=msa_output_dir)是为了要获取到features
for model_name, model_runner in model_runners.items():是要开始运行model了
(3)组建过程
query_sequence = "GWSTELEKHREELKEFLKKEGITNVEIRIDNGRLEVRVEGGTERLKRFLEELRQKLEKKGYTVDIKIE"
上图是输入待预测氨基酸的序列的地方
"""fake template"""
output_templates_sequence = []
output_confidence_scores = []
templates_all_atom_positions = []
templates_all_atom_masks = []
for _ in query_sequence:
templates_all_atom_positions.append(
np.zeros((templates.residue_constants.atom_type_num, 3)))
templates_all_atom_masks.append(np.zeros(templates.residue_constants.atom_type_num))
output_templates_sequence.append('-')
output_confidence_scores.append(-1)
output_templates_sequence = ''.join(output_templates_sequence)
templates_aatype = templates.residue_constants.sequence_to_onehot(output_templates_sequence,
templates.residue_constants.HHBLITS_AA_TO_ID)
template_features = {'template_all_atom_positions': np.array(templates_all_atom_positions)[None],
'template_all_atom_masks': np.array(templates_all_atom_masks)[None],
'template_sequence': [f'none'.encode()],
'template_aatype': np.array(templates_aatype)[None],
'template_confidence_scores': np.array(output_confidence_scores)[None],
'template_domain_names': [f'none'.encode()],
'template_release_date': [f'none'.encode()]}
"""fake pipeline for testing"""
data_pipeline_mock = mock.Mock()
data_pipeline_mock.process.return_value = {
**pipeline.make_sequence_features(sequence=query_sequence,
description="none",
num_res=len(query_sequence)),
**pipeline.make_msa_features(msas=[[query_sequence]],
deletion_matrices=[[[0]*len(query_sequence)]]),
**template_features
}
fasta_path = os.path.join('target.fasta')
with open(fasta_path, 'wt') as f:
f.write(f">A\n{query_sequence}")
fasta_name = 'none'
out_dir = "."
在上述代码中出现了pipeline,因为以前没有接触过,所以去学习了一下:
pipeline可以将许多算法模型串联起来,形成一个典型的机器学习问题工作流。
Pipeline处理机制就像是把所有模型塞到一个管子里,然后依次对数据进行处理,得到最终的分类结果,
# 加载model_1,在正式的代码中是有5个model的
model_runners = {}
model_name = "model_1"
model_config = config.model_config(model_name)
model_config.data.eval.num_ensemble = 1
model_params = data.get_model_haiku_params(
model_name=model_name, data_dir=".")
model_runner = model.RunModel(model_config, model_params)
model_runners[model_name] = model_runner
在上图中只加载了model_1,但alphafold在google colab的代码中是有5个model的
(4)开始运行
predict_structure(
fasta_path=fasta_path,
fasta_name=fasta_name,
output_dir_base=".",
data_pipeline=data_pipeline_mock,
model_runners=model_runners,
random_seed=0)
这里就调用了之前定义的predict_structure函数,进行蛋白质预测
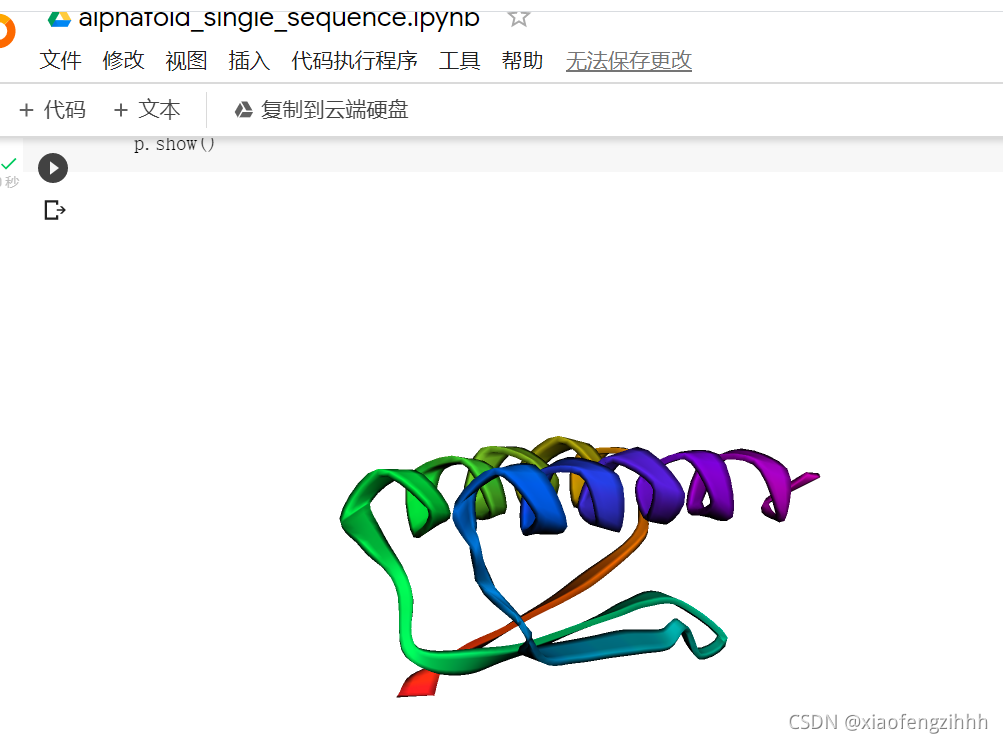
(5)画图展示
p = py3Dmol.view(js='https://3dmol.org/build/3Dmol.js')
p.addModel(open("none/unrelaxed_model_1.pdb", 'r').read(), 'pdb')
p.setStyle({'cartoon': {'color': 'spectrum'}})
p.zoomTo()
p.show()
上图中使用py3Dmol来画图,其中addModel函数是把模型的pdb文件加载进来,setStyle函数是来负责调整最终展示出图片的渲染效果
四、效果展示

















 473
473



 到【灌水乐园】发言
到【灌水乐园】发言







