





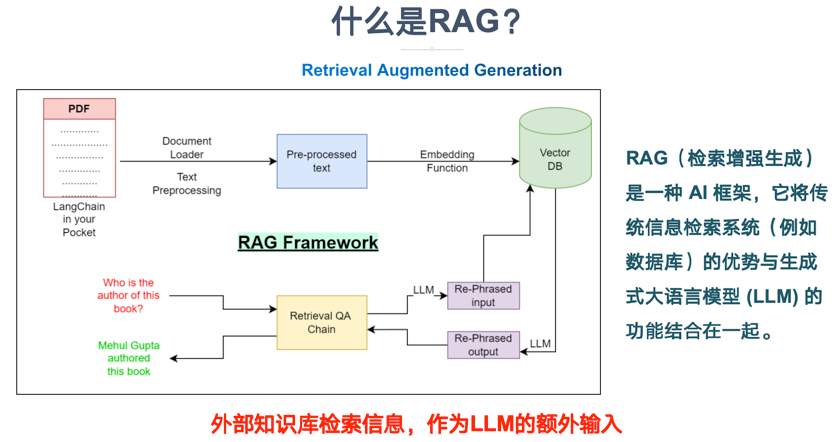
RAG是一种方法论,而不是一项具体的技术——你真的知道什么是RAG吗?
“ RAG的本质是一种方法论,而不是一项具体的技术或框架。”
最近断断续续一直有人问一些关于RAG方面的东西,但是作者发现一件事,就是还有一部分人到现在还不知道RAG到底是什么,还在认为RAG是一项具体的技术或框架。
事实上RAG的本质是一种方法论,目的是为了提升大模型的生成质量,它不是一项具体的技术或开发框架,更多的是一种思想。
RAG是一种方法论
RAG技术是怎么产生的?
随着大模型技术的爆发式发展,一些人在使用的过程中就发现一些问题,那就是大模型有时候会胡说八道或者答非所问。
而产生这个现象的原因主要有三点:
- 大模型幻觉问题:因为大模型的底层是基于概率预测的因此会存在幻觉问题
- 知识不足问题:通用大模型在垂直领域方面的知识不足,除非是经过专家训练的垂直领域模型
- 知识更新速度慢:由于大模型的训练成本问题,因此大模型的知识仅限于其训练语料库的截止内容
由于以上几种原因,就导致了模型偶尔的胡说八道和答非所问;这就像一个人不可能什么都懂,除非他是神,而不是人。
所以,就需要一种方法来解决这个问题,因此RAG就诞生了;当然,解决这个问题不止RAG一种,还有微调,但考虑到成本等问题,还是RAG比较合适
那RAG是怎么解决这些问题的呢?
事实上RAG也并不能完全解决以上三个问题,或者说现在还没办法完全解决模型的幻觉问题;但通过RAG可以解决下面两个问题,并且能够大大降低模型的幻觉问题。
所以RAG的原理是什么?
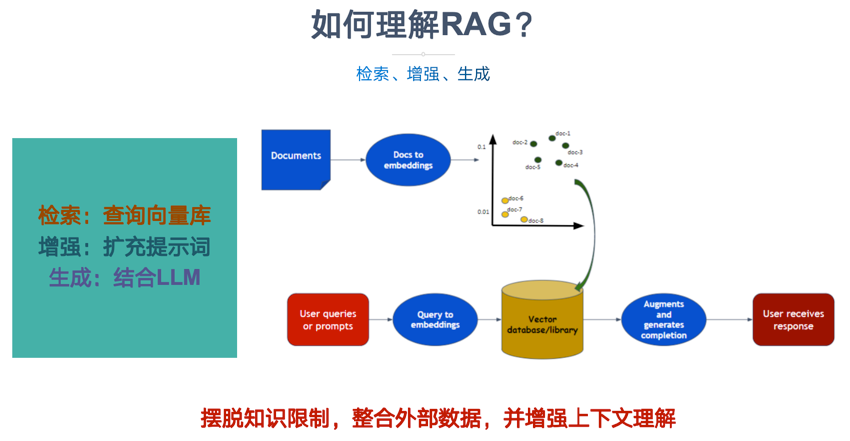
既然模型存在知识更新不及时,知识不足和幻觉问题,那么在模型回答问题之前,先把正确的参考文档给到模型,这样不就可以解决知识不足和更新不及时的问题了。这就类似于学生时代的开卷考试,在回答问题之前先给你参考答案。
因此,RAG需要解决的问题就是,怎么根据问题找到相关的参考答案;其次,怎么把答案和问题丢给模型。
这就是RAG——检索增强生成的真实含义;检索到相关内容,然后增强模型的生成能力。
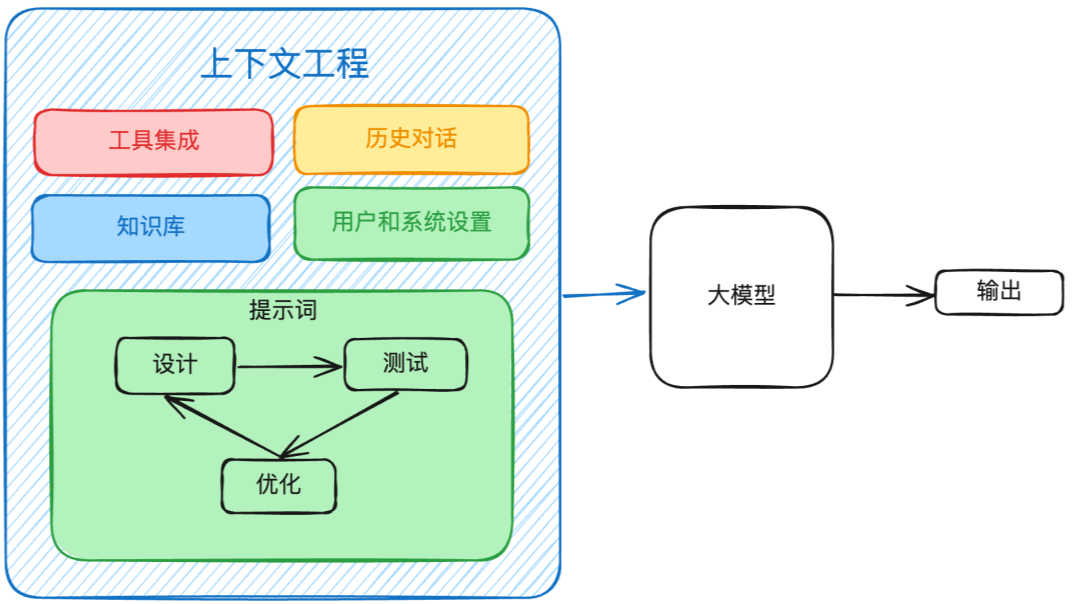
所以,大模型根本不关心你是怎么检索的,大模型关心的是你怎么把检索到的结果给到模型。简单来说其实就是,把问题,参考文档,历史记录等一块拼接到提示词中,然后丢给模型,而这就是模型的上下文管理。
当然,模型的上下文管理是另一个话题,其中涉及到文档格式处理,历史记录,上下文裁剪等等一系列问题。
现在再回到RAG的前半部分——检索;RAG是怎么解决检索问题的呢?
其实关于检索的技术栈有很多,如传统的字符匹配,分词技术,现在的语义(相似度)检索,知识图谱等;甚至包括搜索引擎的搜索技术等等。
如果是用传统的格式化数据做增强,那么就可以使用传统的搜索方式,如数据库搜索;而如果是基于现在的语义相似度检索,那么就需要使用向量数据库等进行相似度匹配。
而由于语义的复杂性,因此又会涉及到知识库的构建,包括文档的切分,向量化(嵌入),元数据处理等等。
因此从理论上来说,模型只关注上下文管理,至于上下文中的参考文档是从哪来的,怎么来的,那都属于检索模块的功能。
最近这几年,经济形式下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。大家想学习和了解大模型的,可以**点击这里前往查看**

















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









