



从统计到神经网络Embedding技术的第二次演化
在上一篇文章中,我们讲到传统的词向量表示(如 One-Hot、TF-IDF、词袋模型等),虽然能让文字“数字化”,但仍有一个致命缺陷——这些表示是孤立的、无意义的,无法真正捕捉语义关系。
比如在统计模型中,“猫”和“狗”完全没有数学上的相似性,但在人类语义中,它们显然是相近的概念。
于是,研究者开始思考:
能不能让计算机“学会”词语之间的关系,而不是仅仅数次数?
于是——基于浅层神经网络的静态词向量诞生了。
- 核心理念:让模型自己去“感受”语义
====================
与传统统计不同,这一阶段的思想是:
不再依靠人为统计词频,而是让模型通过学习上下文,自动“感知”词的含义。
这就是 Word2Vec、GloVe、FastText 等方法背后的核心逻辑。
二、Word2Vec:词向量革命的起点
2013 年,Google 的 Mikolov 团队提出了 Word2Vec,它让“词向量”第一次真正拥有了语义。
核心思路:用一个简单的神经网络,去预测“一个词的上下文”或“根据上下文预测这个词”。
有两种训练模式:
-
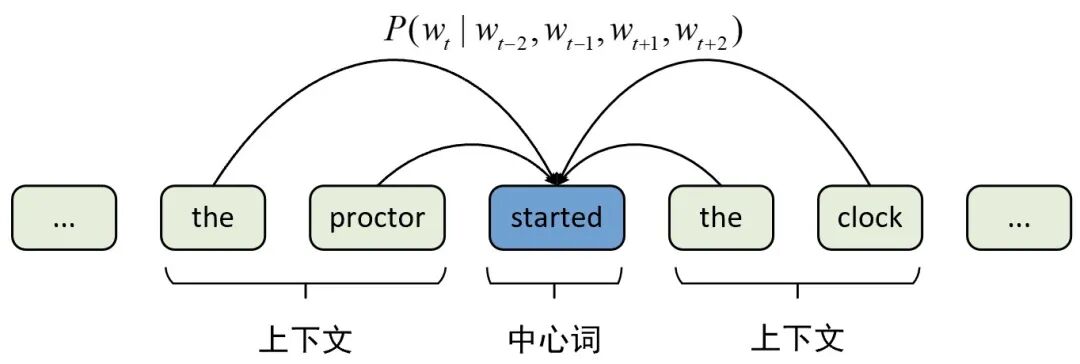
CBOW(Continuous Bag of Words): 根据上下文预测中心词。
-
Skip-Gram: 根据中心词预测周围词。
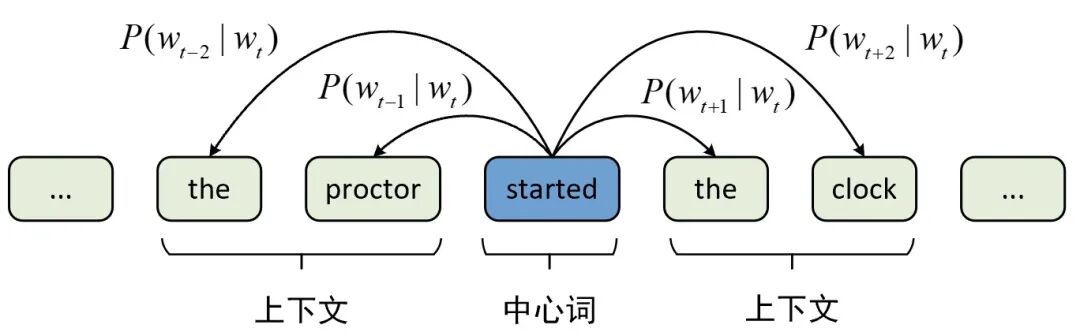
训练完后,我们不要网络输出结果,而是取中间层的权重向量,那就是每个词的词向量。
这个向量包含了词与词之间的语义关系。
Word2Vec 的语义特性可以用简单的向量运算体现:
vector("国王") - vector("男人") + vector("女人") ≈ vector("王后")
计算机第一次“理解”了语言中的逻辑关系!
1.2 GloVe:统计 + 神经网络的混合派
Word2Vec 太火了,但斯坦福团队发现:由CBOW和Skip-gram这两种模型的原理可知,本质上它们都是通过固定窗口中的局部上下文信息来学词的全局向量表示,即没有考虑到词在整个语料中的全局信息对最终词向量的影响。对于一个庞大的语料来说,如果两个词频繁地出现在同一个上下文环境中,那么则说明这两个词具有更强的关联程度,因此模型在训练词向量的过程中就应该需要将这部分信息考虑进去。
于是他们提出了 GloVe(Global Vectors for Word Representation)。
GloVe模型的核心思想是首先通过全局共现矩阵(Co-occurrence Matrix)来统计词与词之间在不同上下文环境中的共现频次,然后再将其作用于原有的条件概率中来调整词向量的关联程度,从而辅以全局的角度来捕捉词与词之间的语义关系。
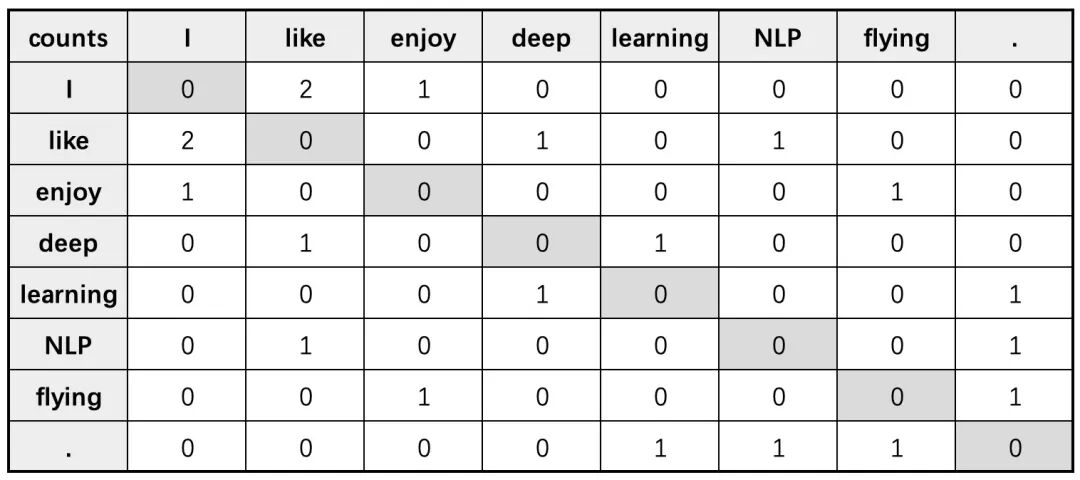
假定现在有如下3条语料:
1 I like deep learning.2 I like NLP.3 I enjoy flying.
根据上述语料可以构造得到词表
1 vocab = ['I','like', 'enjoy', 'deep', 'learning', 'NLP', 'flying', '.']
此时假定窗口长度 ,则最后便可以得到如下共现矩阵
最终,GloVe 在数学层面更稳健,能在小语料上表现更好,也成为许多 NLP 任务的默认选择。
1.3 FastText:字词并重的进化版
尽管同一个词根可以派生得到不同词,但是在Word2Vec和GloVe这两种模型中并没有从形态学的角度来考虑词向量的生成。例如对于interesting 和 interested 这两个词来说,虽然它们都有共同的词根 interest,但是在Word2Vec 和 GloVe中却将这三者看成了完全不同的3个词来对待,而这将导致如果某些词在语料中出现的频次过低,那么模型将难以准确学到这些词对应的词嵌入表示。
基于这样的动机,Facebook 在 2016 年基于跳元模型提出了一种从形态学角度来考虑词向量的子词(Subword)嵌入模型——fastText。fastText模型的核心思想是将一个词以N-gram的形式分割成若干字词部分,然后利用跳元模型的思想为每个子词学习得到一个嵌入式表示,最后将每个词各个子词对应的向量累加起来作为该词的向量化表示。
关键创新:把“词”分解成更细的 子词(subword) 单位,比如字符 n-gram。
举例:单词 "apple"会被拆成 “<ap”, “app”, “ppl”, “ple”, “le>” 等片段
这样做的好处是:
- 能识别词形变化(如 run、running、runs)
- 对未登录词(OOV)也能生成词向量
- 在小语料环境下泛化能力更强
FastText 可以理解为 “Word2Vec + 字符结构”。
- 为什么叫“静态词向量”?
===============
虽然这些方法都用神经网络训练,但生成的词向量是一致的:
一个词永远对应同一个向量,无论它出现在哪个上下文中。
例如:“苹果公司”和“苹果水果”中的“苹果”都是同一个向量。
这意味着模型无法区分多义词。
但在当时,这种“静态语义表示”已经是革命性突破!
- 总结
=====
| 模型 | 核心思路 | 优点 | 局限 |
|---|---|---|---|
| Word2Vec | 通过上下文预测词 | 高效,能捕捉语义关系 | 忽略全局统计信息 |
| GloVe | 结合共现统计与预测模型 | 全局信息更丰富 | 对大语料依赖高 |
| FastText | 使用子词信息 | 对新词、变形词友好 | 模型更大,略慢 |
基于浅层神经网络的静态词向量,让计算机第一次从“统计语言”进化到“理解语言”。
它让语义不再只是数字,而是向量空间中的关系:
- “男人 : 女人 ≈ 国王 : 王后”
- “北京 : 中国 ≈ 东京 : 日本”
这一阶段的创新,也为后来的 BERT、GPT 等上下文动态词向量模型 奠定了基础。
本次内容到此结束,欢迎评论、转发分享!
最近这几年,经济形式下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。大家想学习和了解大模型的,可以**点击这里前往查看**

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









