 Hive基础概念与常用操作介绍
Hive基础概念与常用操作介绍





目录
一.基础概念
1.概述
数据仓库(Data Warehouse)工具
基于Hadoop的
将 结构化的数据文件 映射成一张表
提供了类SQL的HQL的查询功能
本质:将sql语句转换为MapReduce任务进行运行( 记住 ),本质上就是MapReduce
作用: 对海量的大数据(结构化)数据进行分析和统计。
HQL:HQL是Hibernate Query Language的缩写,提供更加丰富灵活、更为强大的查询能力;
HQL更接近SQL语句查询语法。
数据仓库: 英文名称为Data Warehouse ,存储各种类型的数据,面向主体(分类存储), 存储大量的数据,数据的不可以更新,可以一直追加数据。
2.组成架构
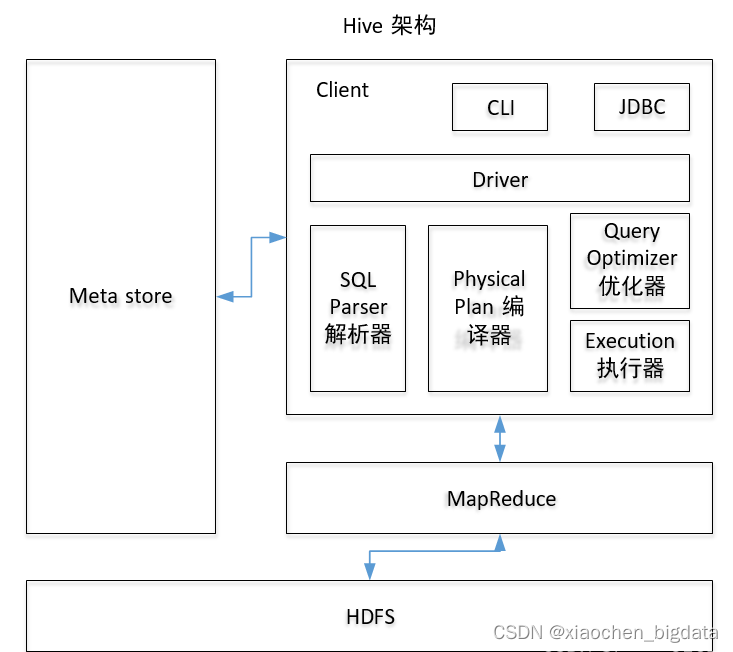
1. 用户使用命令行工具或者JDBC发送HQL
2. 使用Driver驱动结合MetaStore元数据,将指定翻译成MapReduce
3. 首先使用SQL Parser解释器进行HQL的翻译
4. 使用编译器对解释结果进行编译
5. 使用优化器对编译结果进行优化
6. 最后将优化的结果使用执行器进行执行操作(本质上就是在Hadoop集群上使用MapReduce操作)
7. 将处理结果返回给客户端用户
组成:客户端接口、Hive的引擎(驱动)、元数据、Hadoop
说明:
元数据(数据的描述信息:表的名称,数据库的名称,权限,所有者,组成字段等等)
默认情况下存储在hive内部自带的derby数据库中
问题:derby数据库,在同一时刻,只允许一个线程操作
建议:使用MySQL对元数据进行存储
Hive的引擎:
解释器、编译器、优化器、执行器 (顺序)
Hadoop:
执行Hive
Client 接口:用户操作、访问Hive 的方式(jdbc,cli... ...)
3.特点
Hive使用HQL实现对数据的操作,操作方便简单(比MapReduce操作方便)
Hive处理大数据(比MySQL/Oracle强大)
Hive提供的大量的工具
Hive支持自定义函数,使用自定义需求
Hive实现离线数据分析
Hive使用类SQL语句实现功能,处理业务的范围受限(SQL语法所能表达的业务受限)
Hive运行效率较低(延迟高,离线数据分析)
4.hive和传统数据库区别比如mysql
存储位置:Hive数据存储在HDFS上。数据库保存在块设备或本地文件系统 。
数据更新:Hive不建议对数据改写。数据库通常需要经常修改 。
执行引擎:Hive通过MapReduce来实现。数据库用自己的执行引擎 。
执行速度:Hive执行延迟高,但它数据规模远超过数据库处理能力时,Hive的并行计算能力就体现优势了。数据库执行延迟较低。
数据规模:hive大规模的数据计算。数据库能支持的数据规模较小 。
扩展性:Hive建立在Hadoop上,随Hadoop的扩展性。数据库由于A
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3430
3430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









