






一、 实验目的 1. 理解序列化与反序列化; 2. 熟悉 Configuration 类; 3. 学会使用 Configuration 类进行参数传递; 4. 学会在 Map 或 Reduce 阶段引用 Configuration 传来的参数; 5. 理解分布式缓存“加载小表、扫描大表”的处理思想。
二、 实验要求 假定现有一个大为 100G 的大表 big.txt 和一个大小为 1M 的小表 small.txt,请基于 MapReduce 思想编程实现判断小表中单词在大表中出现次数。也即所谓的“扫描大表、 加载小表”。 三、 实验步骤 为解决上述问题,可开启 10 个 Map、这样,每个 Map 只需处理总量的 1/10,将大 大加快处理。而在单独 Map 内,直接用 HashSet 加载“1M 小表”,对于存在硬盘(Map 处理时会将 HDFS 文件拷贝至本地)的 10G 大文件,则逐条扫描,这就是所谓的“扫描 大表、加载小表”,也即分布式缓存。
4:实验步骤
package cn.cstor.mr;
import java.io.IOException;
import java.util.HashSet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.LineReader;
public class BigAndSmallTable {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable( 1 );
private static HashSet<String> smallTable = null;
protected void setup(Context context) throws IOException, InterruptedException {
smallTable = new HashSet<String>();
Path smallTablePath = new Path( context.getConfiguration().get( "smallTableLocation" ) );
FileSystem hdfs = smallTablePath.getFileSystem( context.getConfiguration() );
FSDataInputStream hdfsReader = hdfs.open( smallTablePath );
Text line = new Text();
LineReader lineReader = new LineReader( hdfsReader );
while (lineReader.readLine( line ) > 0) {
String[] values = line.toString().split( " " );
for (int i = 0; i < values.length; i++) {
smallTable.add( values[i] );
System.out.println( values[i] );
}
}
lineReader.close();
hdfsReader.close();
System.out.println( "setup ok *^_^* " );
}
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] values = value.toString().split( " " );
for (int i = 0; i < values.length; i++) {
if (smallTable.contains( values[i] )) {
context.write( new Text( values[i] ), one );
}
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set( sum );
context.write( key, result );
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set( "smallTableLocation", args[1] );
Job job = Job.getInstance( conf, "BigAndSmallTable" );
job.setJarByClass( BigAndSmallTable.class );
job.setMapperClass( TokenizerMapper.class );
job.setReducerClass( IntSumReducer.class );
job.setMapOutputKeyClass( Text.class );
job.setMapOutputValueClass( IntWritable.class );
job.setOutputKeyClass( Text.class );
job.setOutputValueClass( IntWritable.class );
FileInputFormat.addInputPath( job, new Path( args[0] ) );
FileOutputFormat.setOutputPath( job, new Path( args[2] ) );
System.exit( job.waitForCompletion( true ) ? 0 : 1 );
}
}
#导入hadoop文件夹路径下的lib包。
1.点击file>Project Structure>Modules>+号>Library下的java找到你自己的lib文件然后ok。
2.打jar包
点击file>Project Structure>Artifacts>+号>jar找到rm的主类文件。
lib包的导入和jar的打包详情见往期博客;
1:将打好的jar包更名为BigAndSmallTable.jar 上传到hadoop中;
然后start-all.sh启动hadoop
2.创建hadoop fs -mkdir -p /datas/in , hadoop fs -mkdir -p /datas/out

3.编写big.txt和info.txt
big.txt如下:
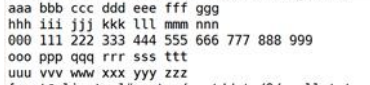
small.txt如下:
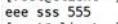
然后用ftp传入hadoop中
5把上传到hadoop中的txt文档用hadoop fs -put big.txt /datas/in hadoop fs -put small.txt /datas/in上传到hdfs中
6.在你hadoop的jar包路径下执行
hadoop jar Mrjoin.jar /datas/in/big.txt /datas/in/small.txt /datas/out
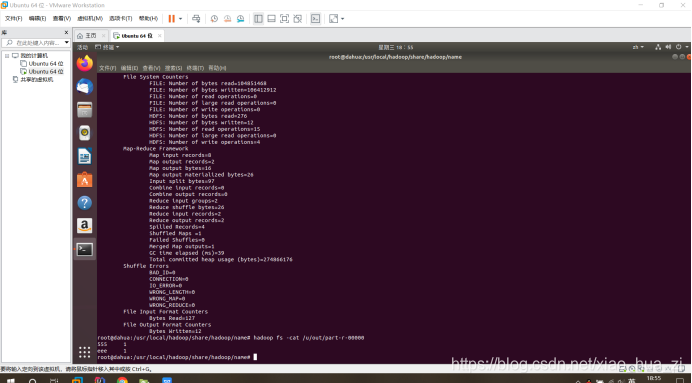
这样就完成了。
然后用hadoop fs -cat /datas/out/part-r-00000查看

最后就成功了。

















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









