



 本文详细介绍了Kafka的两种消费者API:高阶和简单模式。高阶API提供消费组语义,适合多线程应用,但消息顺序不保证;简单API则允许对分区有更多控制,适用于需要精细操作的场景。Kafka的消费方式为拉取模式,消费者根据自身消费能力控制速度。此外,讨论了消费者保证、重平衡和交付保证的概念,强调了在不同设置下如何实现数据一致性和处理效率。
本文详细介绍了Kafka的两种消费者API:高阶和简单模式。高阶API提供消费组语义,适合多线程应用,但消息顺序不保证;简单API则允许对分区有更多控制,适用于需要精细操作的场景。Kafka的消费方式为拉取模式,消费者根据自身消费能力控制速度。此外,讨论了消费者保证、重平衡和交付保证的概念,强调了在不同设置下如何实现数据一致性和处理效率。
LD is tigger forever,CG are not brothers forever, throw the pot and shine forever.
Modesty is not false, solid is not naive, treacherous but not deceitful, stay with good people, and stay away from poor people.
talk is cheap, show others the code and KPI, Keep progress,make a better result.
Survive during the day and develop at night。
目录
概 述
kafka 提供了两套 consumer API:
-
The high-level Consumer API
-
The SimpleConsumer API
其中 high-level consumer API 提供了一个从 kafka 消费数据的高层抽象,而 SimpleConsumer API 则需要开发人员更多地关注细节。
1.1 The high-level consumer API
high-level consumer API 提供了 consumer group 的语义,一个消息只能被 group 内的一个
consumer 所消费,且 consumer 消费消息时不关注 offset,最后一个 offset 由 zookeeper 保存。
使用 high-level consumer API 可以是多线程的应用,应当注意:
3. 如果消费线程大于 patition 数量,则有些线程将收不到消息
-
如果 patition 数量大于线程数,则有些线程多收到多个 patition 的消息
-
如果一个线程消费多个 patition,则无法保证你收到的消息的顺序,而一个 patition 内的消息是有序的
1.2 The SimpleConsumer API
如果你想要对 patition 有更多的控制权,那就应该使用 SimpleConsumer API,比如:
-
多次读取一个消息
-
只消费一个 patition 中的部分消息
-
使用事务来保证一个消息仅被消费一次
但是使用此 API 时,partition、offset、broker、leader 等对你不再透明,需要自己去管理。你需要做大量的额外工作:
-
必须在应用程序中跟踪 offset,从而确定下一条应该消费哪条消息
-
应用程序需要通过程序获知每个 Partition 的 leader 是谁
-
需要处理 leader 的变更
-
查找到一个“活着”的 broker,并且找出每个 partition 的 leader
-
找出每个 partition 的 follower
如果你想要对 patition 有更多的控制权,那就应该使用 SimpleConsumer API,比如:
使用 SimpleConsumer API 的一般流程如下: -
查找到一个“活着”的 broker,并且找出每个 partition 的 leader
-
找出每个 partition 的 follower
-
定义好请求,该请求应该能描述应用程序需要哪些数据
-
fetch 数据
-
识别 leader 的变化,并对之作出必要的响应
2、 consumer group
如 2.2 节所说, kafka 的分配单位是 patition。每个 consumer 都属于一个 group,一个 partition 只能被同一个 group 内的一个 consumer 所消费(也就保障了一个消息只能被 group 内的一个 consuemr 所消费),但是多个 group 可以同时消费这个 partition。
如 2.2 节所说, kafka 的分配单位是 patition。每个 consumer 都属于一个 group,一个 partition 只能被同一个 group 内的一个 consumer 所消费(也就保障了一个消息只能被 group 内的一个 consuemr 所消费),但是多个 group 可以同时消费这个 partition。
kafka 的设计目标之一就是同时实现离线处理和实时处理,根据这一特性,可以使用 spark/Storm 这些实时处理系统对消息在线处理,同时使用 Hadoop 批处理系统进行离线处理,还可以将数据备份到另一个数据中心,只需要保证这三者属于不同的 consumer group。如下图所示:
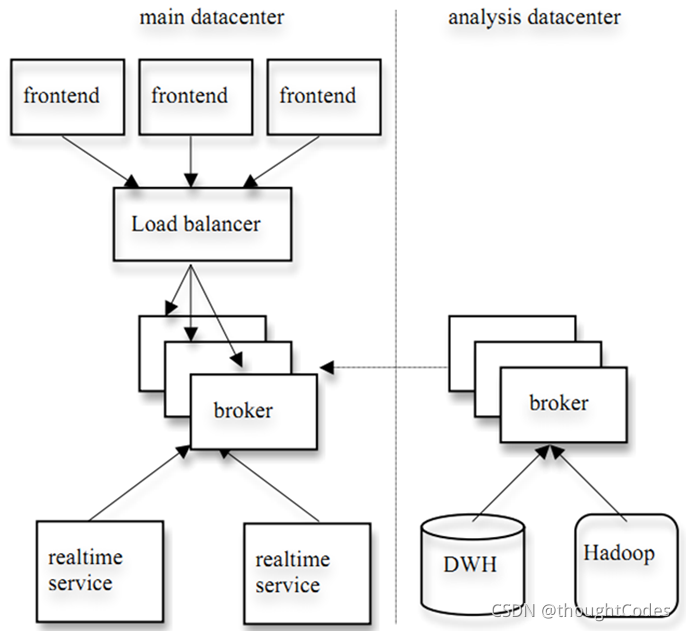
3、 消费方式
consumer 采用 pull 模式从 broker 中读取数据。
push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
对于 Kafka 而言,pull 模式更合适,它可简化 broker 的设计,consumer 可自主控制消费消息的速率,同时 consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
4 、consumer delivery guarantee
如果将 consumer 设置为 autocommit,consumer 一旦读到数据立即自动 commit。如果只讨论这一读取消息的过程,那 Kafka 确保了 Exactly once。
但实际使用中应用程序并非在 consumer 读取完数据就结束了,而是要进行进一步处理,而数据处理与 commit 的顺序在很大程度上决定了consumer delivery guarantee1.读完消息先 commit 再处理消息。 这种模式下,如果 consumer 在 commit 后还没来得及处理消息就 crash 了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于 At most once
总之,Kafka 默认保证 At least once,并且允许通过设置 producer 异步提交来实现 At most once(见文章《kafka consumer防止数据丢失》)。而 Exactly once 要求与外部存储系统协作,幸运的是 kafka 提供的 offset 可以非常直接非常容易得使用这种方式。
5 、consumer rebalance
当有 consumer 加入或退出、以及 partition 的改变(如 broker 加入或退出)时会触发 rebalance。consumer rebalance算法如下:
- 将目标 topic 下的所有 partirtion 排序,存于PT
- 对某 consumer group 下所有 consumer 排序,存于 CG,第 i 个consumer 记为 Ci
- N=size(PT)/size(CG),向上取整
- 解除 Ci 对原来分配的 partition 的消费权(i从0开始)
- 将第i*N到(i+1)*N-1个 partition 分配给 Ci
小结
参考资料和推荐阅读
1.链接: 参考资料.


















 3279
3279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











