







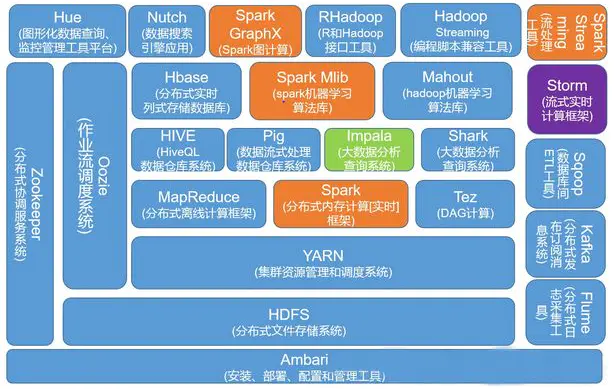
一、hadoop
1.集群搭建
支持平台
●GNU/LINUX是产品开发和运行的平台。
●Win32平台是作为开发平台支持,还不作为生产平台被支持。
所需软件
●Sun公司发行的匹配的java版本。
●ssh必需安装并且保证sshd一直运行,以便于hadoop脚本管理远程hadoop守护进程。
●Window下的附加软件需求:Cygwin提供上述软件之外的shell支持。
安装软件
如果集群尚未安装所需软件,得先安装
linux下:$ sudo apt-get install ssh $sudo apt-get install rsync
在Windows平台上,如果安装cygwin时未安装全部所需软件,则需启动cyqwin安装管理器安装如下软件包:openssh - Net 类
下载和运行hadoop集群准备工作
从Apache镜像服务器上下载hadoop版本
解压下载的hadoop版本。编辑conf/hadoop-env.sh文件,至少需要将JAVA_HOME设置为java安装根路径。尝试如下命令:$ bin/hadoop将会显示hadoop脚本的使用文档。现在可以用以下三种支持模式中的一种启动hadoop集群:
●单机模式
●伪分布式模式
●完全分布式模式
单机模式的操作方法
默认情况下,Hadoop被配置成以非分布式模式运行的一个独立的java进程,这对调试非常有帮助。
下面实例将已解压的conf目录拷贝作为输入查找并显示匹配给定正则表达式的条目,输出写入指定的output目录:
$ mkdir input
$ cp conf/*.xml input
$ bin/hadoop/jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+'
$ cat output/*
伪分布模式的操作方法
hadoop可以在单节点上以所谓的分布式模式运行,此时每一个hadoop守护进程都作为一个独立的java进程运行。使用如下的conf/hadoop-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>localhost:9000</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
●免密码ssh设置:确认能否不输入口令就能用ssh登陆到localhost:$ ssh localhost
如果不输入口令就无法用ssh登陆localhost,执行下面的命令:
$ ssh-keygen -t dsa -p '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
●执行:
格式化一个新的分布式文件系统:$ bin/hadoop namenode -format
启动hadoop守护进程:$ bin/start-all.sh
将输入文件拷贝到分布式文件系统:$ bin/hadoop fs -put conf input
运行发行版提供的示例程序:$ bin/hadoop jar hadoop-*-examples.jar grep input output 'dfs[a-z.]+'
将输出文件从分布式文件系统拷贝到本地文件系统查看:$ bin/hadoop fs -get output output $ cat output/*
在分布式文件系统上查看文件:$ bin/hadoop fs -cat output/*
完成全部操作后,停止守护进程:$ bin/stop-all.sh
完全分布式模式的操作方法
●安装:安装hadoop集群通常要将安装软件解压到集群内所有的机器上。通常,集群内的一台机器被指定为NameNode,另一台不同的机器被指定为JobTracker,这些机器是masters,余下的机器作为DateNode也作为TaskTracker,这些机器是slaves。
用HADOOP_HOME只带安装的根路径,通常,集群里的所有机器的HADOOP_HOME路径相同。
●配置文件:对hadoop的配置通过conf/目录下的两个重要配置文件完成:
1.hadoop-default.xml -只读的默认配置
2.hadoop——site.xml -集群特有的配置
通过设置conf/hadoop-env.sh中的变量为集群特有的值,可以对bin/目录下的hadoop脚本进行控制。
●集群配置:要配置Hadoop集群,你需要设置Hadoop守护进程的运行环境和Hadoop守护进程的运行参数。
Hadoop守护进程指NameNode/DataNode 和JobTracker/TaskTracker。
配置Hadoop守护进程的运行环境
管理员可在conf/hadoop-env.sh脚本内对Hadoop守护进程的运行环境做特别指定。
至少,你得设定JAVA_HOME使之在每一远端节点上都被正确设置。
管理员可以通过配置选项HADOOP_*_OPTS来分别配置各个守护进程。 下表是可以配置的选项。
| 守护进程 | 配置选项 |
|---|---|
| NameNode | HADOOP_NAMENODE_OPTS |
| DataNode | HADOOP_DATANODE_OPTS |
| SecondaryNamenode | HADOOP_SECONDARYNAMENODE_OPTS |
| JobTracker | HADOOP_JOBTRACKER_OPTS |
| TaskTracker | HADOOP_TASKTRACKER_OPTS |
例如,配置Namenode时,为了使其能够并行回收垃圾(parallelGC), 要把下面的代码加入到hadoop-env.sh :
export HADOOP_NAMENODE_OPTS="-XX:+UseParallelGC ${HADOOP_NAMENODE_OPTS}"
其它可定制常用参数还包括:
HADOOP_LOG_DIR - 守护进程日志文件的存放目录,如果不存在会被自动创建。
HADOOP_HEAPSIZE:最大可用的堆大小,单位MB。
这部分涉及Hadoop集群的重要参数,这些参数在conf/hadop-site.xml中指定。
| 参数 | 取值 | 备注 |
|---|---|---|
| fs.default.name | NameNode的URL | hdfs://主机名/ |
| mapred.job.tracker | JobTracker的主机(或者IP)和端口 | 主机:端口。 |
| dfs.name.dir | NameNode持久存储名字空间及事务日志的本地文件系统路径。 | 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。 |
| dfs.data.dir | DataNode存放块数据的本地文件系统路径,逗号分割的列表。 | 当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。 |
| mapred.system.dir | Map/Reduce框架存储系统文件的HDFS路径。比如/hadoop/mapred/system/。 | 这个路径是默认文件系统(HDFS)下的路径, 须从服务器和客户端上均可访问 |
| mapred.local.dir | 本地文件系统下逗号分割的路径列表,Map/Reduce临时数据存放的地方。 | 多路径有助于利用磁盘i/o。 |
| mapred.tasktracker.{map | reduce}.tasks.maximum | 某一TaskTracker上可运行的最大Map/Reduce任务数,这些任务将同时各自运行。 |
| dfs.host/dfs.hosts.exclude | 许可/拒绝DateNode列表。 | 如有必要,用这个文件控制许可的datanode列表。 |
| mapred.hosts/mapred.hosts.exclude | 许可/拒绝TaskTracker列表。 | 如有必要,用这个文件控制许可的TaskTracker列表。 |
●hadoop的机架感知
HDFS和Map/Reduce的组件是能够感知机架的。
NameNode和JobTracker通过调用管理员配置模块中的APIresolve来获取集群里每个slave的机架id。该API将slave的DNS名称(或者IP地址)转换成机架id。使用哪个模块是通过配置项topology.node.switch.mapping.impl来指定的。模块的默认实现会调用topology.script.file.name配置项指定的一个的脚本/命令。 如果topology.script.file.name未被设置,对于所有传入的IP地址,模块会返回/default-rack作为机架id。在Map/Reduce部分还有一个额外的配置项mapred.cache.task.levels,该参数决定cache的级数(在网络拓扑中)。例如,如果默认值是2,会建立两级的cache- 一级针对主机(主机 -> 任务的映射)另一级针对机架(机架 -> 任务的映射)。
●启动hadoop
启动hadoop集群需要启动HDFS集群和map/reduce集群。
格式化一个新的分布式文件系统:$ bin/hadoop namenode -format
在分配的NameNode上,运行下面命令启动HDFS:$ bin/start-dfs.sh该脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DateNode的守护进程。
在分配的JobTracker上,运行下面的命令启动Map/Reduce:$ bin/start-mapred.sh该脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动TaskTracker守护进程。
●停止hadoop
在分配的NameNode上,运行下面命令停止HDFS:$ bin/stop-dfs.sh
该脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DateNode的守护进程。
在分配的JobTracker上,运行下面的命令停止Map/Reduce:$ bin/stop-mapred.sh该脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止TaskTracker守护进程。
hadoop架构
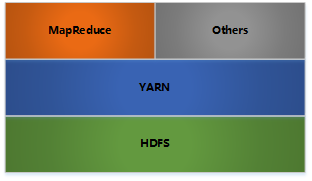
◆HDFS:分布式文件存储
◆YARN:分布式资源管理
◆MapReduce:分布式计算
◆Others:利用YARN的资源管理功能实现其他的数据处理方式。
内部各个节点基本都是Master-Worker架构。
2.HDFS
2.1 分布式文件系统-架构
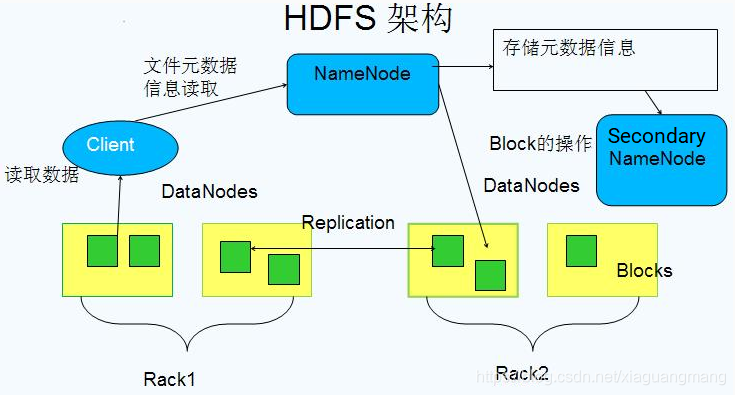
Block数据块
1.基本存储单元,一般大小为64M,配置大的块的主要原因是:①减少搜寻时间,一般磁盘的传输速率比寻道时间要快,大的块可以减少寻道时间;②每个块都需要在NameNode上有对应的记录;③对数据块进行读写,减少建立网络的连接成本。
2.一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,实际占用空间为其文件的大小。
3.基本的读写单位,类似于磁盘的页,每次都是读写一个块。
4.每个块都会被复制到多台机器,默认复制3份。
NameNode
1.存储文件的metadata,运行时所有的数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小。
2.一个Block在NameNode中对应一条记录(一般一个Block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此hadoop建议存储大文件。
3.数据会定时保存到本地磁盘,但不保存Block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
4.NameNode失败则整个HDFS都失效,所以要保证NameNode的可用性。
Secondary NameNode
定时与NameNode进行同步(定期合并文件系统镜像和编辑日志,然后把合并后的传给NameNode,替换器镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机。
DataNode
1.保存具体的block数据
2.负责数据的读写操作和复制操作
3.DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
4.DataNode之间会进行通信,复制数据块,保证数据的冗余性
2.2 HDFS-写文件
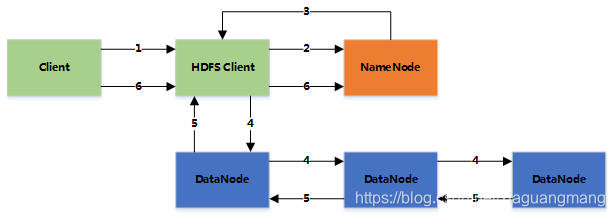
1.客户端将文件写入本地磁盘的HDFS Client文件中
2.当临时文件大小达到一个block大小时,HDFS client通知NameNode,申请写入文件
3.NameNode在HDFS的文件系统中创建一个文件,并把该block id和要写入的DataNode的列表返回给客户端
4.客户端收到这些信息后,将临时文件写入DataNodes
①客户端将文件内容写入第一个DataNode(一般以4kb为单位进行传输)
②第一个DataNode接收后,将数据写入本地磁盘,同时也传输给第二个DataNode
③依此类推到最后一个DataNode,数据在DataNode之间是通过pipeline的方式进行复制的
④后面的DataNode接收完数据后,都会发送一个确认给前一个DataNode,最终第一个DataNode返回确认给客户端
⑤当客户端接收到整个block的确认后,会向NameNode发送一个最终的确认信息
⑥如果写入某个DataNode失败,数据会继续写入其他的DataNode。然后NameNode会找另外一个好的DataNode继续复制,以保证冗余性
⑦每个block都会有一个校验码,并存放到独立的文件中,以便读的时候来验证其完整性
5.文件写完后(客户端关闭),NameNode提交文件(这时文件才可见,如果提交前,NameNode垮掉,那文件也就丢失了。fsync:只保证数据的信息写到NameNode上,但并不保证数据已经被写到DataNode中)
Rack aware(机架感知)
通过配置文件指定机架名和DNS的对应关系。
假设复制参数是3,在写入文件时,会在本地的机架保存一份数据,然后在另外一个机架内保存两份数据(同机架内的传输速度快,从而提高性能)。
整个HDFS的集群,最好是负载平衡的,这样才能尽量利用集群的优势。
2.3 HDFS - 读文件
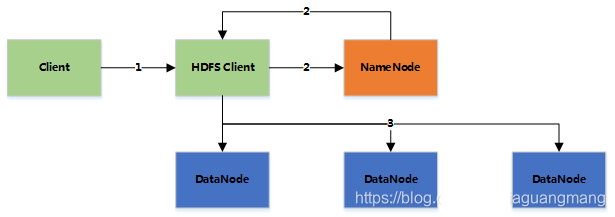
1.客户端向NameNode发送读取请求
2.NameNode返回文件的所有block和这些block所在的DataNodes(包括复制节点)
3.客户端直接从DataNode中读取数据,如果该DataNode读取失败(DataNode失效或校验码不对),则从复制节点中读取(如果读取的数据在本机,则直接读取,否则通过网络读取)
2.4 HDFS - 可靠性
1.DataNode可以失效:DataNode会定时发送心跳到NameNode。如果一段时间内NameNode没有收到DataNode的心跳消息,则认为其失效。此时NameNode就会将该节点的数据(从该节点的复制节点中获取)复制到另外的DataNode中2.数据可以毁坏:无论是写入时还是硬盘本身的问题,只要数据有问题(读取时通过校验码来检测),都可以通过其他的复制节点读取,同时还会再复制一份到健康的节点中
3.NameNode不可靠
2.5.HDFS - 命令工具
fsck : 检查文件的完整性start-balancer.sh : 重新平衡HDFS
hdfs dfs-copyFromLocal : 从本地磁盘复制文件到HDFS
3.YARN
3.1 YARN基本架构和流程
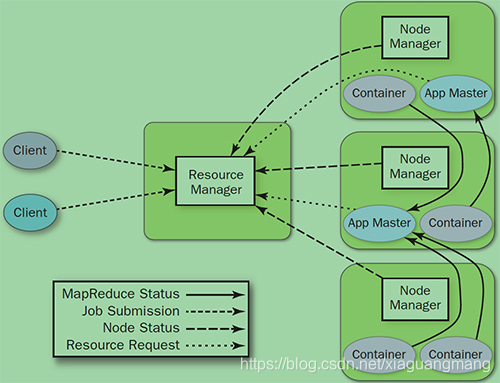
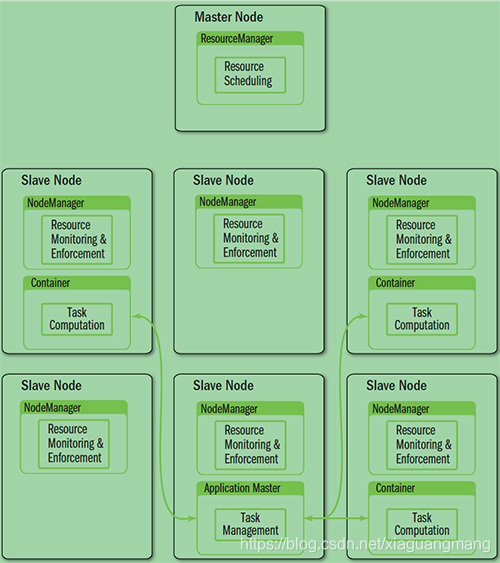
● JobTracker:负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
● TaskTracker:加载或关闭任务,定时报告任务状态
YARN就是将JobTracker的职责进行拆分,将资源管理和任务调度监控拆分成独立的进程:一个全局的资源管理和一个每个作业的管理(ApplicationMaster)ResourceManager和NodeManager提供了计算资源的分配和管理,而ApplicationMaster则完成应用程序的运行
● ResourceManager:全局资源管理和任务调度
● NodeManager:单个节点的资源管理和监控
● ApplicationMaster:单个作业的资源管理和任务监控
● Container:资源申请的单位和任务运行的容器
YARN基本流程
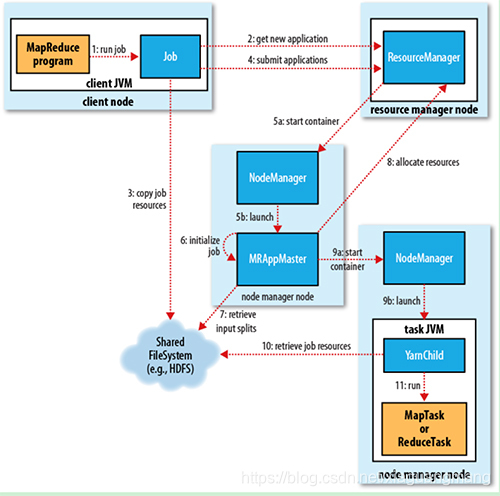
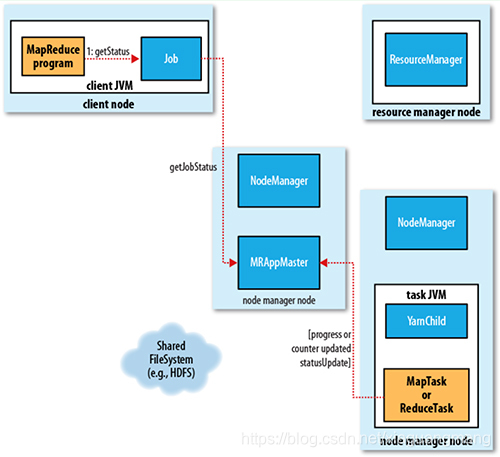
1 、 job submission
从ResourceManager中获取一个Application ID检查作业输出配置,计算输入分片拷贝作业资源(job jar、配置文件、分片信息)到HDFS,以便后面任务执行
2、Job initialization
ResourceManager将作业递交给Scheduler(有很多的调度算法,一般根据优先级)Scheduler为作业分配一个Container,ResourceManager就加载一个application master process并交给NodeManager管理。ApplicationMaster主要是创建一系列的监控进程来跟踪作业的进度,同时获取输入分片,为每一个分片创建一个Map task和相应的reduce task application Master还决定如何运行作业,如果作业很小(可配置),则直接在同一个JVM下运行
3、Task assignment
ApplicationMaster向Resource Manager申请资源(一个个的Container,指定任务分配的资源要求)一般是根据data locality来分配资源
4、Task execution
ApplicationMaster根据ResourceManage的分配情况,在对应的NodeManager中启动Container,读取任务所需的资源(job jar,配置文件等),然后执行该任务
5、Progress and status update
定时将任务的进度和状态报告给ApplicationMaster Client,定时向ApplicationMaster获取整个任务的进度和状态。
6、Job completion
Client定时检查整个作业是否完成,作业完成后会清空临时文件、目录等。
3.2 YARN - ResourceManager
负责全局的资源管理和任务调度,把整个集群当成计算资源池,只关注分配,不管应用,且不负责容错。
资源管理
1、以前资源是每个节点分成一个个的Map slot和Reduce slot,现在是一个个Container,每个Container可以根据需要运行ApplicationMaster、Map、Reduce或者任意的程序
2.、以前的资源分配是静态的,目前是动态的,资源利用率更高
3、Container是资源申请的单位,一个资源申请格式:<resource-name, priority, resource-requirement, number-of-containers>, resource-name:主机名、机架名或*(代表任意机器), resource-requirement:目前只支持CPU和内存
4、用户提交作业到ResourceManager,然后在某个NodeManager上分配一个Container来运行ApplicationMaster,ApplicationMaster再根据自身程序需要向ResourceManager申请资源
5、YARN有一套Container的生命周期管理机制,而ApplicationMaster和Container之间的管理是应用程序自己定义的
任务调度
1、只关注资源的使用情况,根据需求合理分配资源
2、Scheluer可以根据申请的需要,在特定的机器上申请特定的资源(ApplicationMaster负责申请资源是的数据库本地化考虑,ResourceManager将尽量满足其申请需求,在指定的机器上分配Container,从而减少数据移动)
内部结构
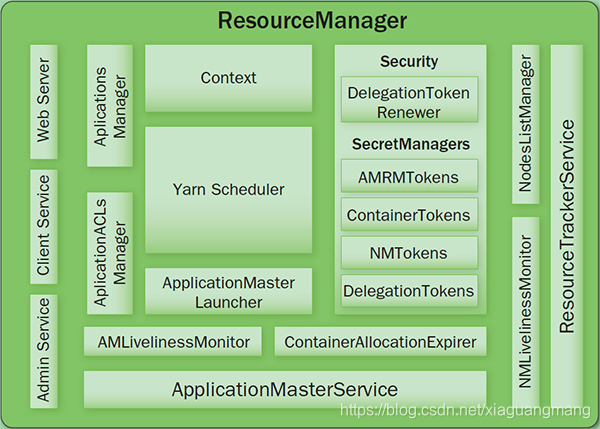
●Client Service:应用提交、终止、输出信息(应用、队列、集群等的状态信息)
●Adaminstration Service:队列、节点、Client权限管理
●ApplicationMasterService:注册、终止ApplicationMaster,获取ApplicationMaster的资源申请或取消的请求,并将其异步地传给Scheduler,单线程处理
●ApplicationMaster Liveliness Monitor: 接收ApplicationMaster的心跳消息,如果某个ApplicationMaster在一定时间内没有发送心跳,则被任务失效,其资源将会被回收,然后ResourceManager会重新分配一个ApplicationMaster运行该应用(默认尝试2次)
●Resource Tracker Service: 注册节点, 接收各注册节点的心跳消息
●NodeManagers Liveliness Monitor: 监控每个节点的心跳消息,如果长时间没有收到心跳消息,则认为该节点无效, 同时所有在该节点上的Container都标记成无效,也不会调度任务到该节点运行
●ApplicationManager: 管理应用程序,记录和管理已完成的应用
●ApplicationMaster Launcher: 一个应用提交后,负责与NodeManager交互,分配Container并加载ApplicationMaster,也负责终止或销毁
●YarnScheduler: 资源调度分配, 有FIFO(with Priority),Fair,Capacity方式
●ContainerAllocationExpirer: 管理已分配但没有启用的Container,超过一定时间则将其回收
3.3 YARN - NodeManager
Node节点下的Container管理:
1、启动时向ResourceManager注册并定时发送心跳消息,等待ResourceManager的指令
2、监控Container的运行,维护Container的生命周期,监控Container的资源使用情况
3、启动或停止Container,管理任务运行时的依赖包(根据ApplicationMaster俄需要,启动Container之前将需要的程序以及依赖包、配置文件等拷贝到本地)
内部结构
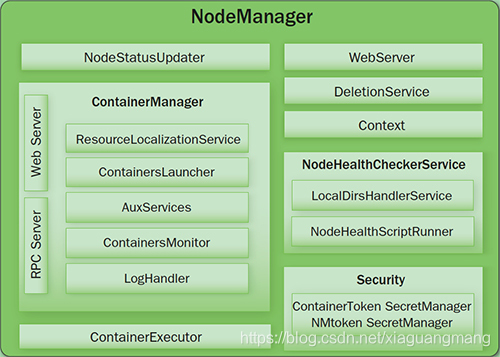
●NodeStatusUpdater:启动向ResourceManager注册,报告该节点的可用资源情况,通信的端口和后续状态的维护
●ContainerManager:接收RPC请求(启动、停止),资源本地化(下载应用需要的资源到本地,根据需要共享这些资源)
PUBLIC:/filecache
PRIVATE:/usercache//filecache
APPLICATION:/usercache//appcache//(在程序完成后会被删除)
●ContainersLauncher:加载或终止Container
●ContainerMonitor:监控Container的运行和资源使用情况
●ContainerExecutor:和底层操作系统交互,加载要运行的程序
impala
1.impala架构
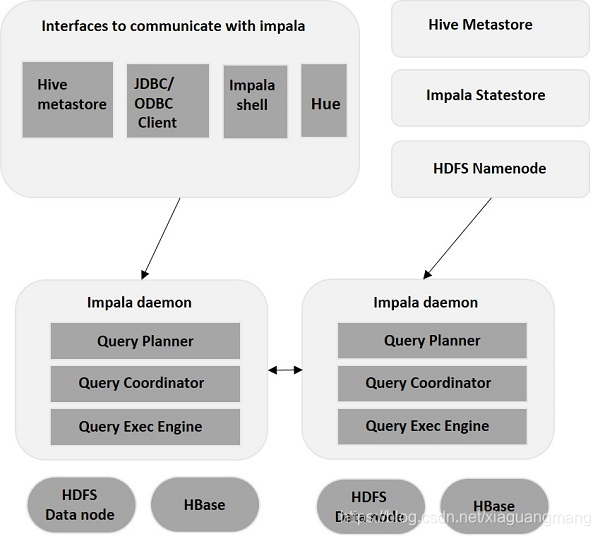
Impala是在Hadoop集群中的许多系统上运行的MPP(大规模并行处理)查询执行引擎。 与传统存储系统不同,impala与其存储引擎解耦。 它有三个主要组件,即Impala daemon(Impalad),Impala Statestore和Impala元数据或metastore。
2.Impala Shell 命令
:'
打开cloudera终端,以超级用户登录 su/cloudera
-- impala中的注释和sql注释相同
'
impala-shell #启动impala sheel
help #提供impala可用命令的列表
version #提供impala当前版本
history #显示在sheel中执行的最后10个命令
quit/exit #从impala sheel中弹出
connect #用于连接到impala给定的实例,如果没有指定任何实例,则连接到默认端口21000
explain sql查询语句 #返回给定查询语句的执行计划
profile #显示有关最近查询的低级信息,用于查询的诊断和性能问题
3.impala 操作数据库
(1)create database [if not exists] database_name #创建新数据库,IF NOT EXISTS是一个可选的子句。 如果我们使用此子句,则只有在没有具有相同名称的现有数据库时,才会创建具有给定名称的数据库
(2)show database #查询Impala中的数据库列表
(3)create database if not exists database_name location hdfs_path #指定创建数据库的位置
(4)drop database [if exists] database_name #删除数据库
(5)drop database [if exists] database_name cascade #删除数据库,使用级联删除(有表存在的情况下)
(6)use database #将当前会话切换到另一数据库
(7)create table IF NOT EXISTS database_name.table_name (
column1 data_type,
column2 data_type,
column3 data_type,
………
columnN data_type
); #建表
(8)show tables #获取表的列表
(9)insert into table_name (column1, column2, column3,...columnN)
values (value1, value2, value3,...valueN); #向表中插入数据
(10)Insert overwrite table_name values (value1, value2, value2); #覆盖插入,覆盖的记录将从表中永久删除
(11)select ... #同sql语句
(12)Describe table_name #用于提供表的描述
(13)ALTER TABLE [old_db_name.]old_table_name RENAME TO [new_db_name.]new_table_name #给表重命名
(14)ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...]) #向表中添加列
(15)ALTER TABLE name DROP [COLUMN] column_name #从表中删除列
(16)ALTER TABLE name CHANGE column_name new_name new_type #更改现有表中的列的名称和类型
(17)DROP table [if exists] database_name.table_name; #删除表
(18)truncate table_name; #截断表
(19)Create View [IF NOT EXISTS] view_name as Select statement; #创建视图
(20)alter view database_name.view_name as select new_statement; #更改视图
(21)drop view database_name.view_name; #删除视图
(22)select * from table_name order by col_name [asc|desc] [nulls first|nulls last] #排序:asc:升序,desc:降序,nulls first:空行排在最前,nulls last:空行排在最后
(23)select sum(salary) from table_name group by age having max(salary)>20000;#group by 结合聚合函数使用,Having子句与group by子句一起使用; 它将条件放置在由GROUP BY子句创建的组上
(24)select * from table_name order by id limit 4 offset 5 #调过前5行取后边的4行
4.日期时间函数
-- 当前时间戳
now();
current_timestamp()
-- 将秒数转换到字符串
from_unixtime(int,'yyyy/MM/dd HH:mm')
-- 将时间戳转换成日期字符串
to_date(timestamp) -- 日期格式为 yyyy-MM-dd
-- 将秒数转换成时间戳
to_timestamp(bigint unixtime)
-- 时间戳取整(impala 2.11之后)
date_trunc('year',now()) -- 年
date_trunc('month',now()) -- 月
date_trunc('week',now()) -- 周
date_trunc('day',now()) -- 天
date_trunc('hour',now()) -- 小时
date_trunc('minute',now()) -- 分钟

















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









