






前言
-
1、本号将持续更新AI4PDEs&AI4CFD相关前沿进展 -
2、本号主推:开源、启发性的文献 -
3、感兴趣可以关注微信公众号:AI4CFD -
4、持续更新中!

单位:四川大学
推文:本文约2万字(代码地址和论文pdf下载在文末)
摘要:深度学习的快速发展对计算流体动力学的进步有重大意义。目前,大多数基于像素网格的深度学习方法在预测边界层流动时准确度显著降低,并且对几何形状的适应性较差。虽然基于非结构化网格的图神经网络模型在不稳定流动预测中有更好的几何形状适应性,但这些模型在长期不稳定流动预测中存在误差累积问题。更重要的是,完全数据驱动的模型通常需要大量的训练时间,这极大地限制了面对更复杂的不稳定流动时深度学习模型的快速更新和迭代速度。因此,本文旨在通过将基于有限体积法的物理约束整合到图神经网络的损失函数中,平衡训练开销和预测准确度的需求。此外,它融合了一个受扩展模板方法启发的双重消息聚合机制,以提高图神经网络模型在非结构化网格上的不稳定流动预测准确度和几何形状泛化能力。我们特别关注模型在边界层内的预测准确度。与完全数据驱动的方法相比,我们的模型在较短的训练时间内实现了更好的预测准确度和几何形状泛化能力。
关键词:图神经网络 有限体积法 物理信息深度学习 计算流体动力学

I 引言
计算流体动力学(CFD)已成为分析流动现象和预测机械性质的重要工具。传统的CFD方法通过迭代解决一组离散化的偏微分方程来预测流场。对于实际工程问题,这需要大量的计算资源。特别是对于非稳定粘性流问题,为了更准确地捕捉边界层的流动特性,相比解决稳态问题,对计算资源的需求更大。随着深度学习的快速发展,CFD社区也获益匪浅;特别是,在使用基于像素的均匀网格的神经网络模型进行流场预测方面,已经取得了显著的效率改进。然而,它仍然面临着巨大的挑战:未能满足实际工程应用和缺乏物理解释性。为了应对缺乏物理解释性的问题,在许多基于深度神经网络的方法中,不需要网格离散化的物理信息神经网络(PINNs)在解决偏微分方程(PDEs),包括纳维-斯托克斯方程的能力上显示出了相当的潜力。PINNs将物理定律集成到深度学习框架内的神经网络中,使用自动微分技术,并且即使在缺乏或不存在可观测数据的情况下也能表现良好。然而,基于自动微分的PINNs在通过链式规则进行反向传播时会生成许多大型张量,导致处理大规模问题时训练开销过大。
为了进一步减少过高的训练开销,物理信息神经网络(PINNs)可以从CFD的数值离散化方法中获得灵感,使其不完全依赖于自动微分工具来获取物理场的导数。采用数值微分相比自动微分可以显著降低解决物理场导数的计算开销。根据使用的空间离散化网格类型,数值方法可以分为基于结构化网格的有限差分方法(FDM),以及适用于非结构化网格的有限体积方法(FVM)和有限元方法(FEM)。对于复杂的实际工程问题,非结构化网格提供了更好的几何灵活性。有限体积法(FVM)是非结构化网格最常用的数值离散化方法之一,将其集成到神经网络中正日益受到关注。然而,大多数上述研究工作仅限于验证在均匀像素网格上的有效性,这通常不能适应复杂的几何形状并降低粘性流问题边界层附近的预测精度。这偏离了FVM适应任意形状网格单元的原始意图。因此,为了增强神经网络模型的工程应用能力,急需扩展其对非均匀、非结构化网格的处理能力。
众所周知,与基于卷积神经网络(CNNs)的方法相比,图神经网络(GNNs)对非结构化网格有着天然的适应性。GNNs以由节点和边组成的图结构为输入,并通过消息传递机制学习节点和边的特征表示。凭借其适应性和可扩展性,GNNs在各个领域被广泛应用,包括社交网络分析、推荐系统和知识图谱等,显示出巨大的潜力。因此,基于图神经网络的偏微分方程(PDE)求解方法已成为当前流行的研究方向之一。此外,众多学者开发了基于图神经网络的纯数据驱动方法。然而,这些纯数据驱动的研究往往需要在精度和训练开销之间找到平衡。特别是在预测不稳定流场时,通常需要长时间的训练才能达到可靠的预测精度。此外,随着网格数量或训练案例的增加,总训练开销可能会急剧增加。同时,由于纯数据驱动方法几乎不引入任何物理归纳偏差,它们在大多数模型中导致了较弱的几何泛化能力。这些问题显著阻碍了图神经网络模型在复杂和多变的实际工程问题中的应用。
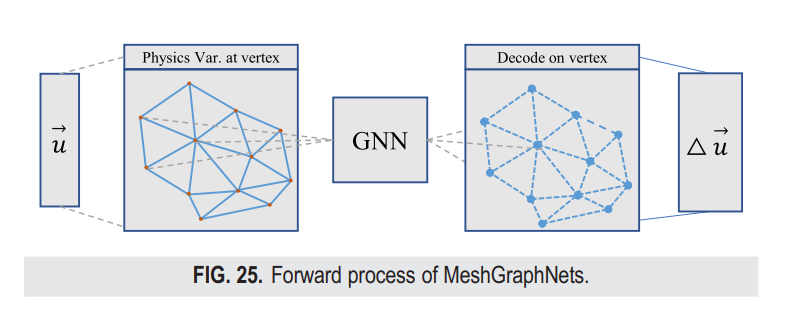
通过减小模型隐藏空间的大小或使用更少的训练轮次来降低图神经网络(GNN)模型的训练开销是相当直接的方法[见图1(a)]。以MeshGraphNets(MGN)为例,这是一个能够预测不稳定流场的纯数据驱动图神经网络模型,它通过铺设多个GN(即“图网络”)块构建,并将非结构化网格编码为一个多图[无向图,如图1(a)所示],其中物理场相关变量放置在图的顶点上,网格边的邻接关系转化为图的邻接关系,无向图满足置换不变性。为了降低训练成本,可以将MeshGraphNets中的双向边属性转换为单向边属性,换句话说,将无向图转换为有向图。同时,在训练过程中随机交换图中每条边的方向可以保持置换不变性。这可以显著减小边特征的大小,从而提高训练效率,如**图1(b)**和第四节所示。特别是,对于一个隐藏空间大小设为128的标准MeshGraphNets模型,边属性的实际隐藏空间大小为256。单向边的方法仍然可以保持边属性的隐藏空间大小为128。然而,显然直接减小模型的隐藏空间大小将不可避免地导致模型最终预测准确度的下降(见表VII)。
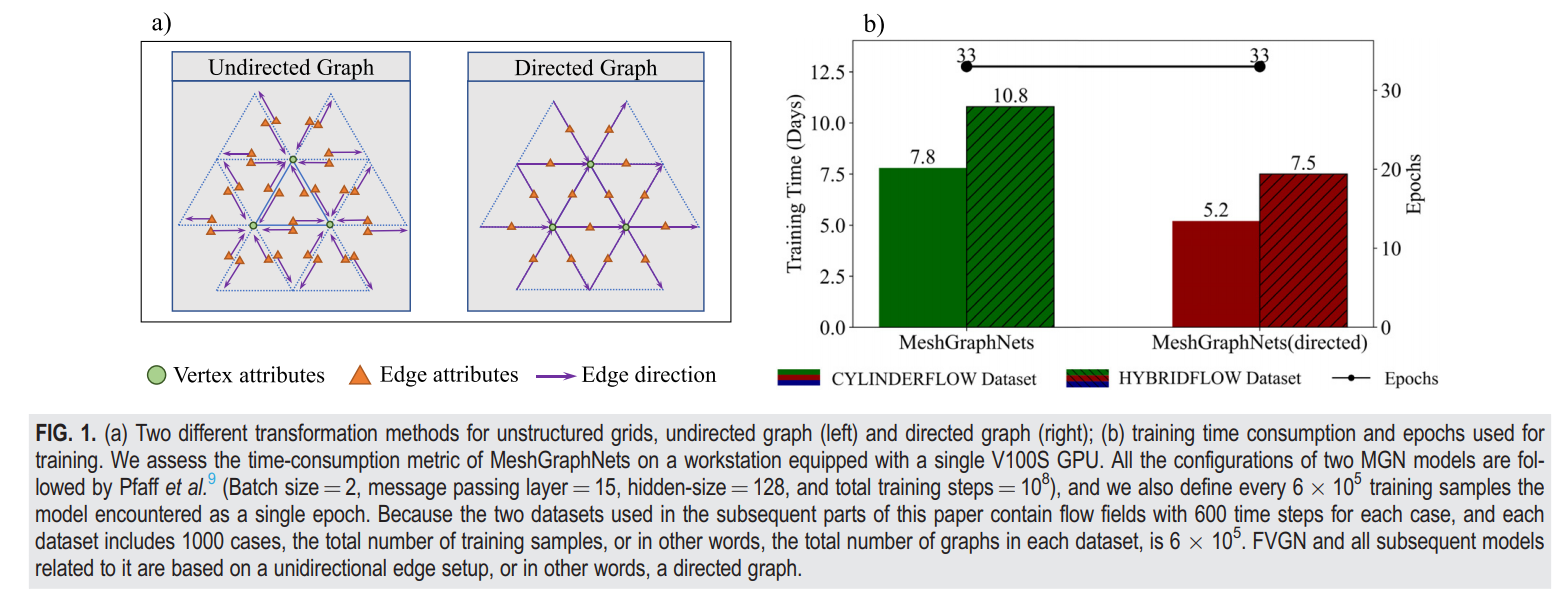
图1。**(a)** 针对非结构化网格的两种不同变换方法,无向图(左)和有向图(右);**(b)** 训练所需的时间消耗和周期。我们在配备单个V100S GPU的工作站上评估了MeshGraphNets的时间消耗度量。两种MGN模型的所有配置都遵循Pfaff等人的方法(批大小= ,消息传递层= ,隐藏大小= ,总训练步骤= ),我们也定义了每 训练样本为模型遇到的一个单独的周期。由于本文后续部分使用的两个数据集包含每个案例 个时间步长的流场,并且每个数据集包括 个案例,因此每个数据集的总训练样本数,换句话说,每个数据集中图的总数是 。FVGN以及所有后续与之相关的模型都是基于单向边的设置,换句话说,一个有向图。
总之,就物理解释性问题而言,结合PINNs和数值离散化损失函数的方法在准确度和计算成本之间取得了良好的平衡。然而,对于工程应用能力,目前阶段使用的均匀网格具有相当大的限制。为非结构化网格适配的数据驱动GNN具有更高的计算成本和较差的物理解释性。仅通过减小隐藏空间的大小来降低计算成本会导致显著的精度损失,这是不可接受的。因此,为了在降低计算成本和训练难度的同时提高物理解释性并满足复杂工程应用的要求,本研究尝试引入一种基于有限体积法的物理约束方法到具有有向边的MeshGraphNets中,并通过受扩展模板方法启发的双重消息聚合机制来增强有向MeshGraphNets的性能。特别是,在MeshGraphNets的消息传递层中,节点MLP(多层感知器,即全连接网络)结构非常类似于卷积神经网络中的卷积核,两者都具有共享参数。与MeshGraphNets相比,我们的有限体积图网络(FVGN)将边特征聚合到邻近顶点,然后再到消息传递层中的单元中心,允许FVGN中的单元MLP的感受野以二次方的方式增加(见第四节),从而显著提高模型的最终性能。
上述设计不仅弥补了由于减小隐藏空间大小和训练周期导致的精度下降,还保持了高训练效率。本研究大致分为四个部分:第二节A至E介绍如何基于FVM构建损失函数以及FVGN的整体前向过程、训练细节和相关信息。第二节D详细介绍了双重消息聚合方法,并将其与MeshGraphNets的消息聚合过程进行了比较。第三节介绍了本研究用于验证方法的两个数据集。最终的流场预测结果可以在第四节A和B中找到。此外,FVGN的泛化能力在第四
II 问题设置和方法论
在这一节中,我们将简要概述不稳定不可压缩的纳维-斯托克斯(N-S)方程。我们首先描述如何使用有限体积方法将这些微分方程转换成它们的积分形式。这一转换是制定受约束损失函数的核心,而受约束损失函数是我们方法中的一个关键组成部分。我们详细讨论了有限体积图网络(FVGN)方法论中的一个关键步骤,动量方程的整合。此外,我们解释了如何使用图来基于非结构化网格表示不稳定的流场。在本节的最后,我们介绍了物理约束损失函数,这是FVGN的一个新颖方面,也是我们研究的一个重要贡献。
A. 控制方程和图表示
在这项工作中,我们专注于二维(2D)不可压缩纳维-斯托克斯(NS)方程,其表达式为
其中 是时间, 是 -方向和 -方向的速度, 是压力, 是密度,而 是动力粘性。 和 分别代表流体域和边界。 是以特征长度 定义的雷诺数, 是参考速度,而 是运动粘性。
有限体积法(FVM)适用于守恒形式的方程。可以通过发散定理,将体积分形式 ( ) 转换为单个单元格面上的表面积分,从而证明这一点。因此,我们可以利用守恒定律以控制方程的积分形式构成。通过对方程(1)和(2)进行体积积分,我们可以将其转换为控制方程的积分形式。通过对方程(1)和(2)进行体积积分,然后应用散度定理将它们转换为面积分,可以得到以下公式:
方程 (3) 代表连续性方程,方程 (4) 和 (5) 分别代表在 和 方向上的动量方程。更具体地说,我们定义通量 , ,而 。同时,在上述积分中,通过更广义的散度定理得出压力项的形式,从而将压力梯度转换为控制体积表面的积分形式。
传统数值求解器生成的原始网格可以视为图 ,其中 对应于网格节点, 对应于网格边 [图 2(a)]。这被称为基于单元中心的转换。另外,我们也可以使用基于顶点中心的图 来表示网格,其中 是网格元素,而 是边属性,两个相邻单元的下标指示 [图 2(b)]。两种变量放置方法通常在传统有限体积方法中使用。计算精度可能会随着单元中心或顶点中心网格的选择而变化。然而,在本工作中,我们可以同时利用两种网格类型来提高图神经网络在消息传递过程中的效率。在我们的模型中,我们做了一个假设,即 和 具有相同的边属性。因此,在后面的部分,我们仅使用 作为 和 的边属性。更多详细内容,请参考第四节。
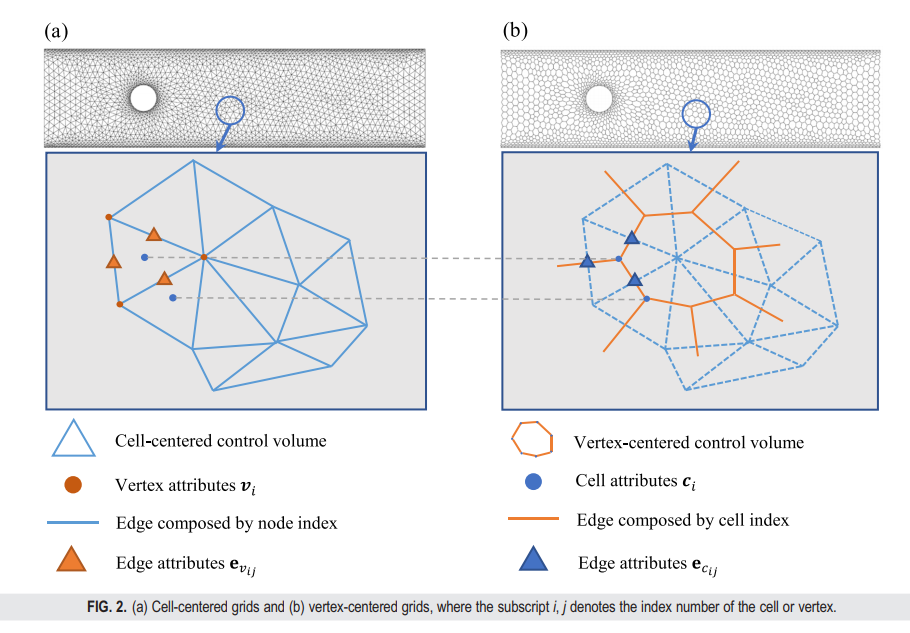
B. 物理约束损失
正如之前在公式(3)中描述的,我们定义了连续性方程的通量 。同样在公式(4)和(5)中,对流通量 也被定义。对于瞬态项,我们使用了一阶时间差分方法 来离散化。扩散通量被定义为 ,这意味着 , 在公式(4)和(5)中。最后压力通量 也被涉及。
如果存在数值解,这些解有时间步的范围,我们可以使用 作为公式(4)和(5)右侧的监督学习,在每个训练时间步骤;最终,在简单移动项的几步之后,以下方程被构成:
公式(8)表示了一个完整的动量残差形式的损失函数。 是单元格区域, 是指向单元格外部的法向量, 是面积或边长在2D情况下。实际上,我们拥有瞬态项 的目标值,以及对于 , ,和 在 边缘的目标值。例如, 是直接从单元格中心通过插值得到的求解器解, 和 也是如此。值得注意的是,我们将扩散项转换为更加简洁的形式,表示为 ,这改变了公式(8)的含义,使模型学习一个符合动量方程扩散项的补偿项。因此,我们不再必要地使用格林-高斯方法或最小二乘法来获得单元格的梯度。为了确保元素面上对流项通量和压力项通量的准确计算,我们还引入了额外的监督项, 和 ,分别对控制体积面上的 , ,和 变量。上述插值过程可以通过一个简单的几何平均方法来实现,该方法在单元格顶点或单元格中心和面中心之间进行插值。尽管这不可避免地引入了额外的误差, 可以是一个高精度变量。因此,公式(8)可以确保补偿项正确满足动量方程。
在我们的实践中,与直接预测 或 相比,这种形式的损失函数可以使用物理方程的残差来约束模型的搜索空间,这减少了单个预测步骤中的预测误差,从而减轻了长期预测过程中误差累积的问题。因此,为了准确预测控制体积面上的通量,我们引入了以下两个额外的监督项:
结合上述损失项,我们得到以下损失函数:
其中 和 是超参数,用来加权不同损失项的贡献。请注意,在损失函数公式(11)中的加权系数在训练过程中扮演了至关重要的角色。然而,选择公式(11)中适当的权重通常是非常繁琐的。一方面, 和 的最优值依赖于问题,并且我们不能为不同的流动固定它们。因为我们只在两个数据集中进行了训练,我们冻结了所有训练案例的超参数;更多细节可以在第II.E节中找到。
C. 有限体积图网络
我们将任务描述为一个自回归过程,这意味着学习到的模型将当前的单元中心状态 映射到下一个状态 ,其中图节点特征 ,图边特征 。我们的目标是训练一个能够提取当前网格状态变化趋势的学习模型,也就是对流项通量 、补偿项通量 、压力项通量 在下一时间步的每个边缘被描绘在图3中,并且整合起来以获得下一个时间的网格状态。因此,我们提出了有限体积图网络(FVGN),这是一个具有编码-处理-解码架构的图神经网络模型,后续是空间积分层(简称SIL)。图3展示了FVGN架构的视觉方案。此外,我们在第II C 2节中提供了整个前向过程的伪代码。
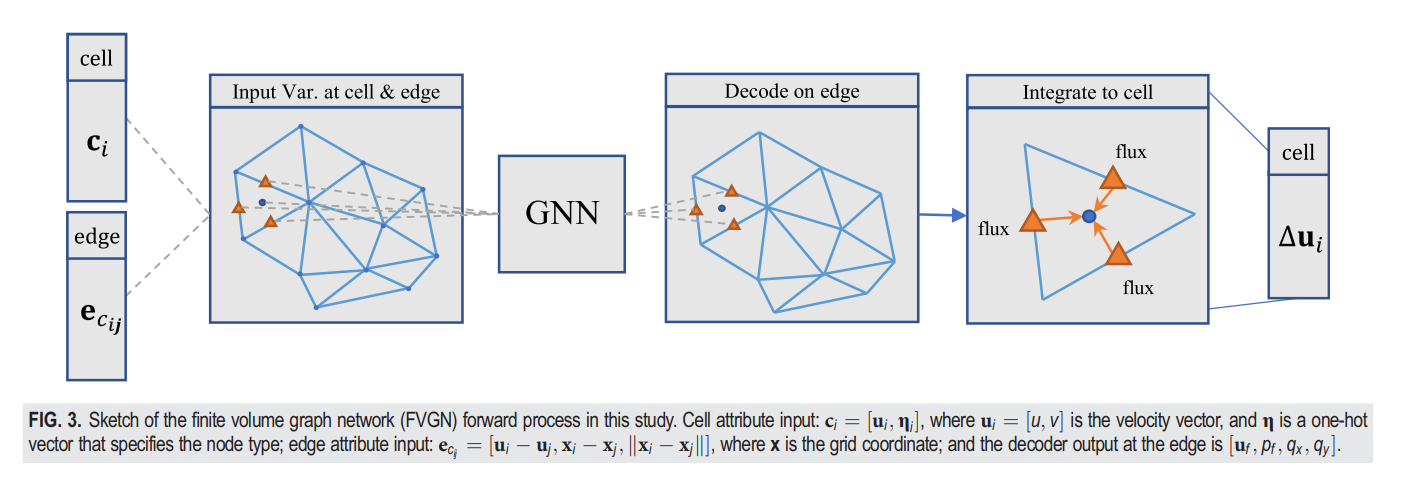
1. 编码器
编码器有两部分,单元属性编码器 和边属性编码器 。编码器仅编码当前顶点中心的网格状态 至一个指向图 ,这在第II节被提及。然后每个单元中心都有隐藏特征 ,它们的大小是128。同样,边的输入是与单元中心维度相同的。此外, 的输入是速度场 在 x 方向和 y 方向在时间步 的,并且是一个独热向量,指定了节点类型(边界节点或内部节点)。 的输入是每个相邻单元格之间的边的差异,边的长度,以及构成每条边的顶点的相对坐标之差,可以表示为 。 和 都采用了包含ReLU和SILU激活函数的MLP,并以LayerNorm输出。鉴于我们采用了一个有向图,每个边都有一个单一方向,要么是 或是 ,这意味着 的计算可能在训练和测试期间产生不同的结果。这种差异可能会对模型的泛化能力产生不利影响,换句话说,这种方法不满足置换不变性。为了解决确定正确减法顺序的问题,我们采用了一个直接的方法:随机洗牌连接方向在训练期间,有效地意味着索引 和 在训练期间被随机交换,同时保持任意连接方向的随机选择。这种方法的后续实验表明,它显著降低了模型的计算成本,同时大大减少了MeshGraphNets的计算成本。
2. 处理器
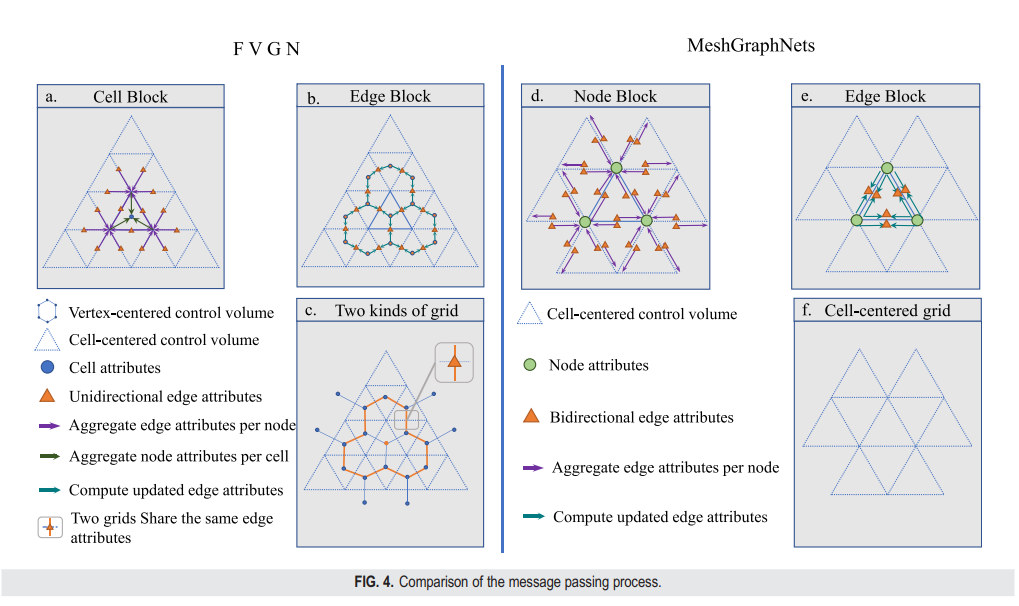
处理器由M个相同的消息传递层组成,这些层推广了GraphNetwork块,此后简称为GN块。每个GN块由一个单元块和一个边块组成,在图4中描绘。每个GN块包含一个单元块和一个边块。每个块包含一组独立的网络参数,并按顺序应用于前一个块的输出,更新编码后的边特征 和单元特征 ,分别为:
在公式(12)中, 是与同一个顶点共享的边的数量。
我们的模型在消息聚合过程中的单元块内与MeshGraphNets有显著的差异,即我们的模型采用纯边特征聚合(如图4或公式(12)所示),然后将信息传递给单元中心(如图4或公式(12)中的 所示),并通过 Cell-MLP(类似于多层感知机,相当于完全连接网络) 更新当前单元属性。模型进一步将两个相邻单元属性与边属性串联起来,并传递给 Edge-MLP 以更新边特征。设计这一过程的原因是,如果我们将 Cell-MLP 比喻为CNN中的卷积核,那么对于MeshGraphNets的单元中心图 ,Cell-MLP 可以被视为增加了感知场(图4右侧)。采用我们的方法后,图内的每个单元中心 Cell-MLP 都能够获取到比 Node-MLP 中更远距离的特征,这可以被视为感知场的平方增加,这无疑也提高了消息传递的效率。我们的方法的细节和优化在第II.D节进行了描述。
为了更具体地阐明这一过程的工作方式,我们首先将我们的方法命名为“两次消息聚合”和MeshGraphNets的“一步消息聚合”。如图4所示,编码后的图 进入第一个消息传递层,该层处理所有共享相同顶点的边特征。第一个过程将使用存储在 (见图2(a))中的邻接关系(由节点索引组成)。输出,表示为 ,将进入第二个消息聚合过程,该过程将单个单元的顶点信息传递到单元中心,第二过程使用存储在 (见图2(b))中的邻接关系。
在单元块处理的最后,聚合后的特征将与 连接,并通过一个Cell-MLP处理;我们将其表示为 以更新单元属性。最后,在剩下的EdgeBlock内,两个相邻单元的特征将与当前边的特征连接,并通过另一个MLP处理;我们将其表示为Edge-MLP或 ,输出 。
3. 解码器和空间积分层
FVGN中的解码器主要由两个隐藏层组成,隐藏层的大小为128,并使用SiLU激活函数的MLP 。此外, 没有使用LayerNormalization (LN) 层配合,这些层是与MLP一起解码信息的。解码器任务是在消息传递层后将潜在的边特征解码成边上的真实通量。这与传统的数值求解器相当相似,后者找到更高阶的导数以逼近每个控制体积面上的特定通量值,因此这些导数被求和以逼近一个特定的通量值。所以,解码器将潜在的导数解码成物理域的通量,A、Q和p,分别代表对流通量项、补偿通量项和压力通量项,这些都是每个控制体积面上的。
下一步是根据公式(8)将这些通量整合并求和到控制体积的中心;我们发现,传统的有限体积方法在通量计算中成本很高。因此,边缘上的通量近似值通过神经网络肯定会实现相比传统的FVM基础求解器的加速效果。我们使用这样一个图神经网络模型来加速传统的有限体积方法求解器的通量计算。我们使用这样一个图神经网络来近似物理变量,这意味着解码器的输出是控制体积面上物理变量的近似值。然后,如第II C节开头所述,动量方程的右侧项可以通过在每个控制体积面上将物理量或梯度与相应的表面向量相乘并随后求和得到。我们将这一操作称为空间积分层(SIL),因为这样的积分操作发生在我们提出的神经网络模型的前向过程中。近似物理模型的右侧项后,我们使用了一个简单的一阶差分映射方法来驱动服务端变量,即 。通过对初始时间步长的速度场进行差分,FVGN在训练/推理期间提取每个边/面的通量,将它们整合到单元中心,并得到 ,可表示为:
根据传统的CFD方法,我们的方法类似于显式方案,该方案受CFL数的严格约束。但是,如从方程(9)和(10)可以看出,我们可以将稳定性和可用性考虑到模型构建中,并使用时间 作为约束。当使用隐式方案结合子步迭代方法获取数据集时,我们的模型可以在不考虑稳定性条件的情况下保持稳定性和准确性。传统CFD的稳定性分析似乎不适用于我们的模型。此外,我们模型的稳定性和准确性表现,对于长期预测也通过后续数值结果的验证。
D. 方法比较
总结来说,如图4所示,在单元块内,FVGN执行了两个消息聚合操作。第一个操作包括将边特征聚合到两个邻接端点之间,而第二个操作涉及将操作后的边特征聚合到单元中心。这一过程发生在以单元为中心的图 (G_c) 上,利用边集 (E_c) 和从单元中心图 (G_c) 派生的顶点集 (V_c)。我们假设这些边与相邻单元的特征相结合,然后通过边块的MLP传递,以计算边上当前的特征。这个过程发生在以顶点为中心的图 (G_v) 内,边集 (E_c) 包含了当前边的两个邻接单元的索引。我们也假设单元中心和顶点中心图共享相同的边特征。
相比之下,对于MeshGraphNets,消息传递只发生在以单元为中心的图 (G_c) 和边块之间,并且Node Block只聚合邻近实体的特征。可以认为Node Block的“感受野”是线性增加的。然而,对于FVGN,单元块的感受野被认为是以平方的方式增加的。如图4(c)所示,仅在单个图形演示中可以观察到这一点。如果只是MeshGraphNets那样仅利用 (G_c),它能够在单元块内或FVGN中的Cell Block执行操作(例如,执行**图4(a)或公式(12)中的方程)。然而,它无法执行FVGN的边块操作。这是因为 (G_c) 仅存储单元之间的邻接关系,而不存储单元间的关系。因此,FVGN通过同时利用 (G_c) 和 (G_v),使得图4(c)**中用橙色圈出的单元能够自动聚合远离自己超过两跳的特征。因此,我们的方法可以被视为一种聚合高阶邻居消息的方法,从而提高了模型内消息传递的效率。
E. 训练策略及稳定化训练方法
我们在Next-Step模式下训练了我们的模型,并且还使用了MeshGraphNets提供的CYLINDERFLOW数据集。FVGN的下一步预测过程可以表示为 (如图5左所示)。我们的模型可以直接输出下一个时间步的流场是相当直接的。然而,我们也遵循了Ref. 38中的方法,即在某一时间步,物理场包含了显示物理场将如何进化的趋势。对于神经网络来说,提取这样的趋势并将这些趋势送入显式的物理方程(如方程(1))以接收输入场的下一个时间状态比直接预测下一个时间状态的方法要容易得多。因此,我们的方法可以被认为与隐式格式非常相似,因为方程(1)的右侧由方程(9)和(10)所示的变量在 时刻组成。这反映在我们使用 时刻的值来重建流量值时,也就是在控制体积面上。最后,我们也使用了噪声注入方法来稳定推进过程。噪声尺度在后面章节可以在第VI A 2节找到。
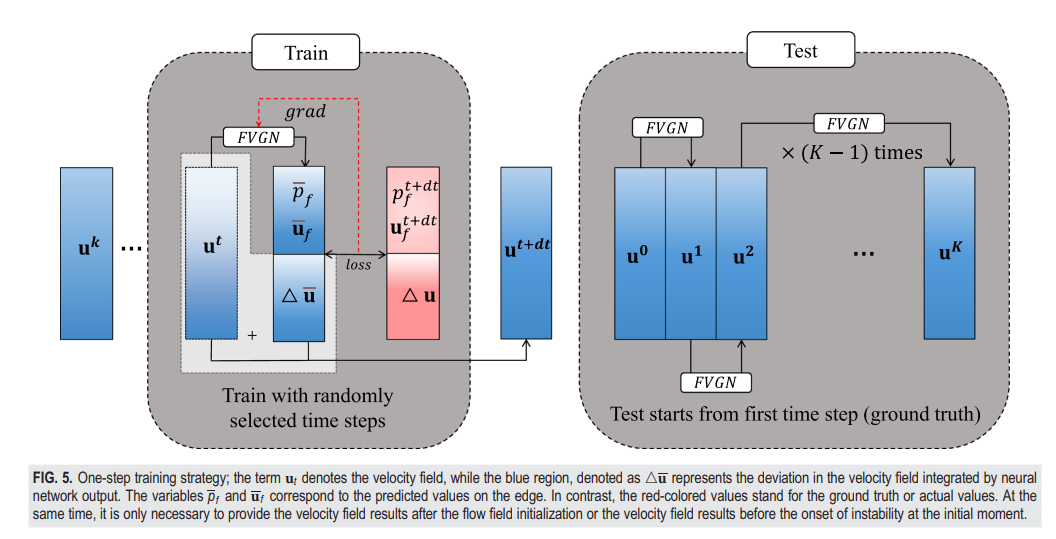
图5. 一步训练策略;术语 ( \mathbf{u} ) 表示速度场,而蓝色区域,表示为 ( \Delta \mathbf{u} ),代表由神经网络输出的速度场中的偏差。变量 ( \mathbf{p}_f ) 和 ( \mathbf{u}_f ) 对应于边缘上的预测值。相比之下,红色区域的值代表真实值或实际值。在流场初始化后或在初始时刻不稳定性开始之前,只需要提供速度场结果。
1. 学习率和超参数
方程(11)中每个损失的权重特别重要。我们选择超参数 、 、 ,和 对于本文中使用的所有数据集,初始学习率为 ,并且总共训练了14K轮。我们定义以下内容:对于每个累积的1000轮训练样本,我们将完成模型训练过程中的一轮。应该注意的是,它的定义与一个epoch不同,其中一个epoch是指当模型看到整个训练集一次时。每个周期定义为模型遇到的每600个时间步样本。此外,当训练轮次达到3000轮时(即,第3000轮),学习率下降到 ,然后以50%的衰减率指数下降,直到学习率达到最小学习率 。我们这样确定参数是因为在一个完全数据驱动的方法中,流的参数数值需要不可压缩,所以我们可以直接将 设置为0以用于连续性方程,因为动量方程在自回归预测过程中起着最重要的作用,所以我们选择动量方程的权重非常大,并且在每个控制体积面上的损失是对应于该面确定的速度-压力场的直接预测值。在第VI节中,我们将讨论设置参数 的合理性。除非另有说明,我们采用了上述超参数来配置和训练FVGN模型。
III. 数据集与数据预处理
在本研究中,我们使用了两个数据集来训练和评估FVGN模型的性能。第一个数据集是参考文献9中的CYLINDERFLOW数据集。这个数据集包含了1000个案例,每个案例包含600个时间步的求解器结果。数据集的特征涵盖了一系列几何类型——圆柱尺寸,圆柱位置和雷诺数。训练集的雷诺数范围在10到230之间。因此,测试集和训练集的案例比例大约是3.2:1。数据集的初始时刻在 时没有流动场。更多细节可以在表I的第一行找到。

此外,我们还引入了另一个HYRBRIDFLOW数据集。和第一个数据集一样,HYRBRIDFLOW数据集也由1000个案例组成,每个案例包含600个求解器结果的时间步。在创建此数据集时,我们从使用求解器的时间步[15, 614]中导出了结果以形成数据集。本质上,在第15个时间步的HYBRIDFLOW数据集案例处于流动变得不稳定之前的关键状态。HYRBRIDFLOW数据集不仅包括圆柱形几何体,还包括机翼和矩形几何体,大约比例为8:1:1。机翼案例也具有不同的攻击角度,范围定义为从 到 且只有NACA0012的形状。
HYRBRIDFLOW数据集的雷诺数范围是200到1000,平均单元数在(6000, 8000)之间。与之前的圆柱流动数据集相比,这个数据集有一个显著更广的雷诺数范围和增加的网格密度,因此为模型提出了更大的学习挑战。我们期望FVGN在HYRBRIDFLOW数据集上取得更好的表现,同时保持与MeshGraphNets相同的可学习参数总数。关于HYRBRIDFLOW数据集的具体细节可以在表I的第二行找到。表I列出了两个不同数据集的几个重要指标。CYLINDERFLOW数据集(标示在表的第一行),独家包括涉及圆柱障碍物的案例,没有包括任何其他的几何形状。然而,圆柱计算域的位置、大小和入流速度(即雷诺数)在一定范围内随机变化。另一方面,HYBRIDFLOW数据集(标示在表I的第二行)涵盖了三种不同几何形状作为障碍物的案例,即圆柱、NACA0012机翼和矩形柱。同时,这个数据集也包含了位置、大小和雷诺数参数的各种组合,类似于CYLINDERFLOW数据集。此外,对于机翼案例,攻击角在一定范围内变化,增加了另一层复杂性。
A. 数据预处理
在FVGN的整个训练过程中,我们使用了许多与网格属性相关的参数,比如单元区域、单元边的长度、控制体积面的单位法向量等。所有这些对于有限体积方法计算而言必要的数值都是在数据集生成过程中预先计算的。因此,FVGN的数据预处理大致可以分为两步。第一步是从原始的单元中心图 (本研究只涉及三角形网格)计算出每个单元的区域、边长和单位法向量。然后,顶点中心图 被用来计算并生成顶点中心图 中邻近单元间的邻接关系,以及边长(面积)、单元区域和单位法向量,这些都会在训练前写入数据集中。第二步涉及在训练过程中对神经网络输入的 中顶点和边的特征进行实时的统计分析,以获取平均值和方差。然后,这些获取到的平均值和方差被用于归一化输入特征。同样,在每一个训练步骤中,输入特征的平均值和方差会被累积,并通过规范化步骤来处理。引入这种物理信息化的规范化步骤可以显著提高模型的预测精度。最终,流场的规范化处理可以表示为 ,其中 表示速度场的方差, 表示速度场的平均值, ,其中 表示压力场的方差,而 代表压力场的平均值。
IV. 结果
我们使用相对均方误差(RMSE)来比较结果,公式如下:
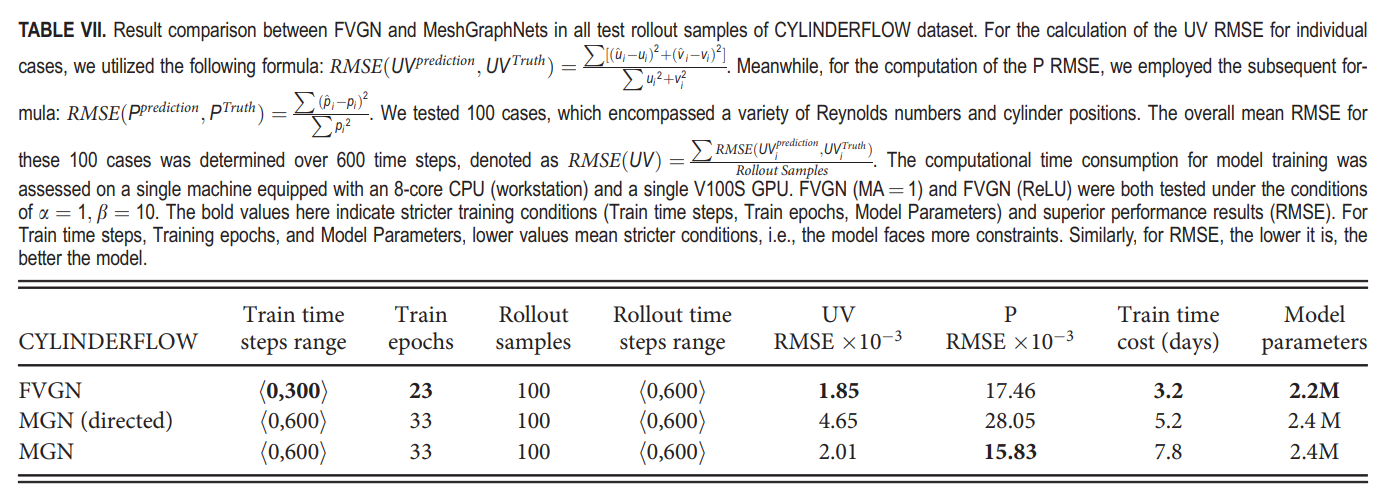
表VII和表VIII展示了FVGN在有限训练数据和仅编码单向边特征的测试结果。在训练时间消耗的列中,我们还展示了MeshGraphNets在两个训练集上的训练时间开销。实现代码是从DeepMind的GitHub仓库派生的,我们保持了与MeshGraphNets相同的超参数设置,如15层消息传递、128大小的潜在向量,以及(10^6)的训练步骤。我们基于原始代码修改了MeshGraphNets的输出,使其可以预测压力场的值(原始代码只能用来预测速度场)。修改后的MeshGraphNets代码可以在此GitHub仓库找到。
A. 稳态流模拟
在本节中,我们主要展示FVGN在不稳定过程下预测稳态流场的应用。此外,以下两个例子是从模型训练和测试中得到的,都是基于CYLINDERFLOW数据集进行的。值得注意的是,在这个数据集上,FVGN只使用了前300个时间步的数据,而MGN和有向的MGN(directed)则使用了全部600个时间步进行训练。
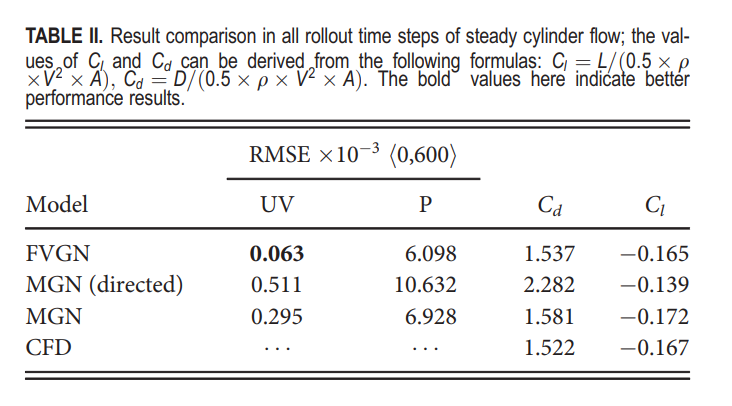
在这个案例研究中,雷诺数为41,网格单元数为3732。如图6所示,对于一个稳态流场,它有一个更简单的流场结构,因此FVGN的压力预测误差主要集中在边界层附近。此外,如图7所示,在这种稳定流动情况下,FVGN能够在较长时间内保持非常稳定的预测结果。同时,正如表II所示,与MGN和有向MGN(directed)相比,它有更低的RMSE和更精确的升力与阻力系数预测。但值得注意的是,尽管FVGN的压力场预测误差主要集中在圆柱表面,这在一定程度上影响了升力和阻力系数预测的准确性,但这并不影响模型整体长期预测误差。换句话说,边界层的误差并不影响通过消息传递的全局预测准确度。总体而言,对于稳定的情况,上述模型都能够取得良好的结果。然而,考虑到即使在CYLINDERFLOW数据集上,平均网格单元数也只有大约3500,并且FVGN与MGN在参数数量上没有显著差异,FVGN仍然实现了更高的预测精度。
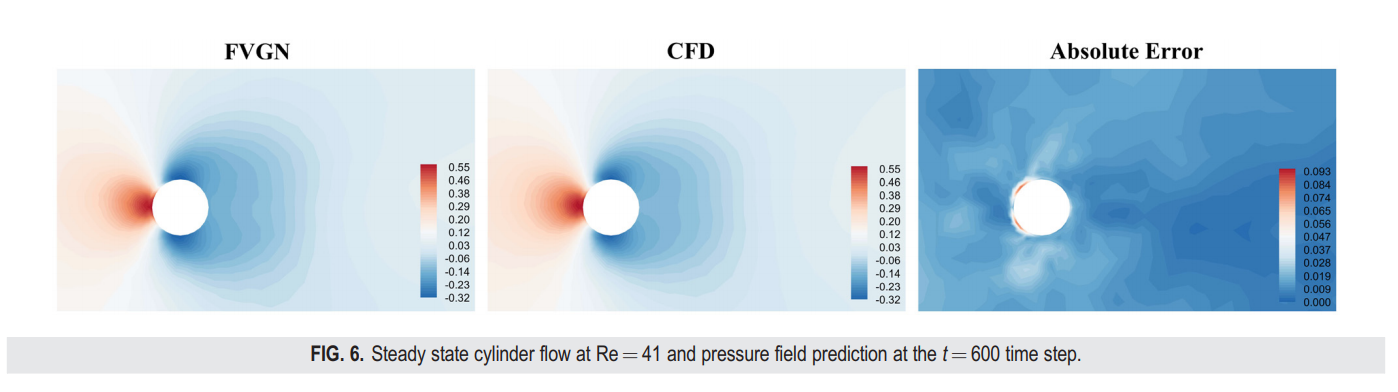
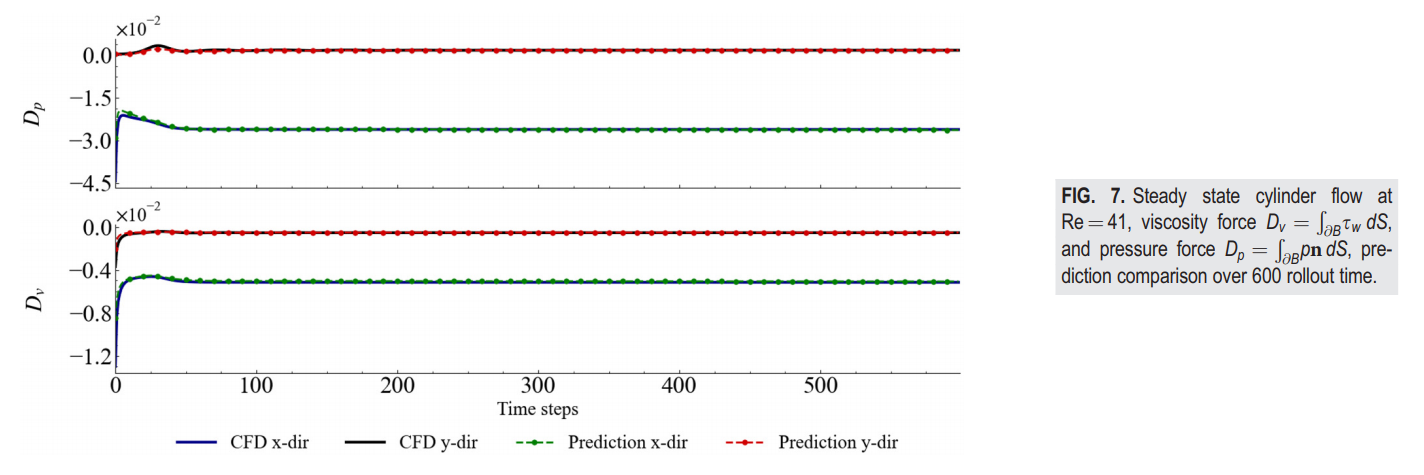
图 7. 雷诺数为 41 的稳态圆柱流动,粘性力 ,压力力 ,600次推演时间的预测比较。
B. 非稳态流动的模拟
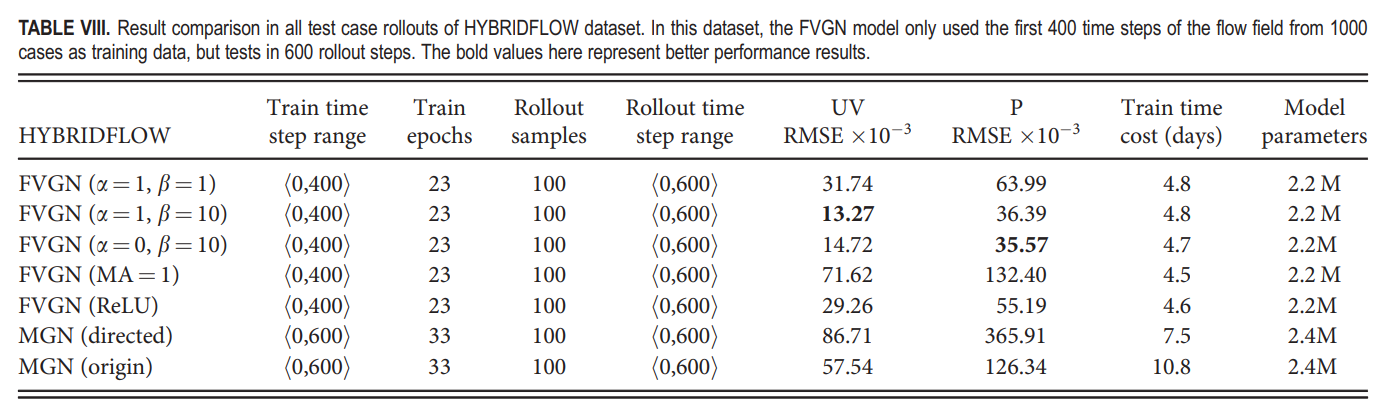
在这一部分中,我们展示了使用HYBRIDFLOW数据集对FVGN和MeshGraphNets进行训练的三个测试结果。与MeshGraphNets相比,FVGN在该数据集上的训练时间消耗和最终测试预测结果的准确性都有很大改善。该数据集相比CYLINDERFLOW数据集包含更广泛的雷诺数范围、更多种类的障碍物几何形状以及更密集的网格。最重要的是,后面部分的三个测试案例都是使用仅在前400个时间步上进行训练的FVGN模型状态进行测试的。
1. 二维圆柱流动
以下测试案例具有雷诺数( )和圆柱位置组合,在训练集中不存在。实际上,在HYBRIDFLOW数据集中,80%的训练样本都是圆柱案例,因此我们主要专注于在这个测试案例中测试模型在类似训练集的条件下的性能。我们不仅提供了两种模型的相对均方误差(RMSE),还比较了FVGN和MGN在升力和阻力系数方面的预测准确性。升力系数 和阻力系数 可以从以下公式中推导出: ,阻力系数 可以通过以下公式推导得出: ,其中垂直升力 和水平阻力 可以通过对圆柱表面的压力和表面摩擦力进行积分得到,参数 代表圆柱的直径,作为一个参考长度。
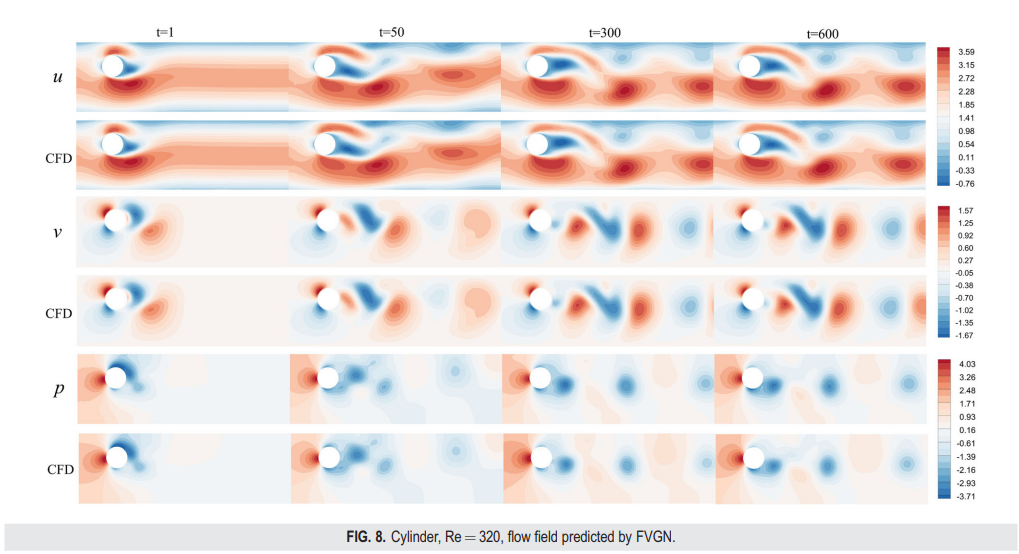
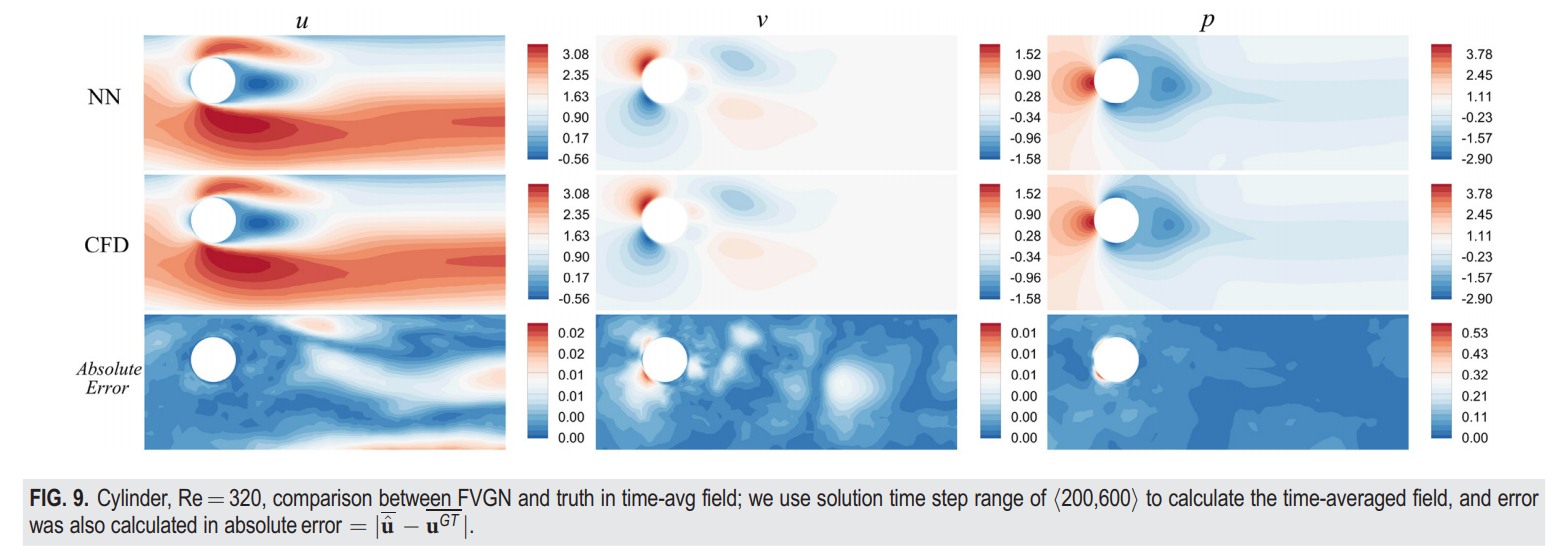
我们不仅比较了各个时刻的瞬态轮廓图(图8),还计算了最后400个时间步长的时间平均场(图9)。从表III可以看出,在前[200,400]个时间步长内,FVGN在速度场(UV)和压力场预测上具有更低的RMSE,展现了其在捕捉绕圆柱体复杂非定常分离流动方面的准确性。值得注意的是,当将展开时间步长延长至600,MeshGraphNets在压力预测方面表现出了最高的精度,其达到了 12.497 × 10^-3。此外,其误差并没有在前400步相比有显著增加,这使得MeshGraphNets对升力和阻力系数的预测几乎与CFD结果完全一致。正如图10所示,FVGN更准确地捕捉到了非定常流动下的涡脱相位,而由MGN预测的相位并没有与CFD结果对齐,这解释了表III中展示的MeshGraphNets(有向)的大相对均方误差。这个误差不仅包括预测的物理场的振幅误差,而且还包括涡脱的相位误差。在图11中,我们可以看到FVGN在400时刻的压力分布预测的准确性比在600时刻的要低。此外,从图12中的阻力曲线变化来看,似乎随着预测时间步长的增加,模型变得更加精确。然而,正如从升力曲线中看到的,从第500个时间步长开始,模型预测结果的频率发生了变化,这导致了精度提高的假象。这一现象表明,在用深度学习模型模拟非定常流动时,不应仅依赖于均方根误差(RMSE)和轮廓图进行性能比较。确定模型误差是由振幅预测不准确,还是由于特定时间步长的物理场差异导致的脱落频率或相位预测不准确,这是一个挑战。升力和阻力曲线提供了一个更清晰的判断,指出了深度学习模型误差出现的方面。
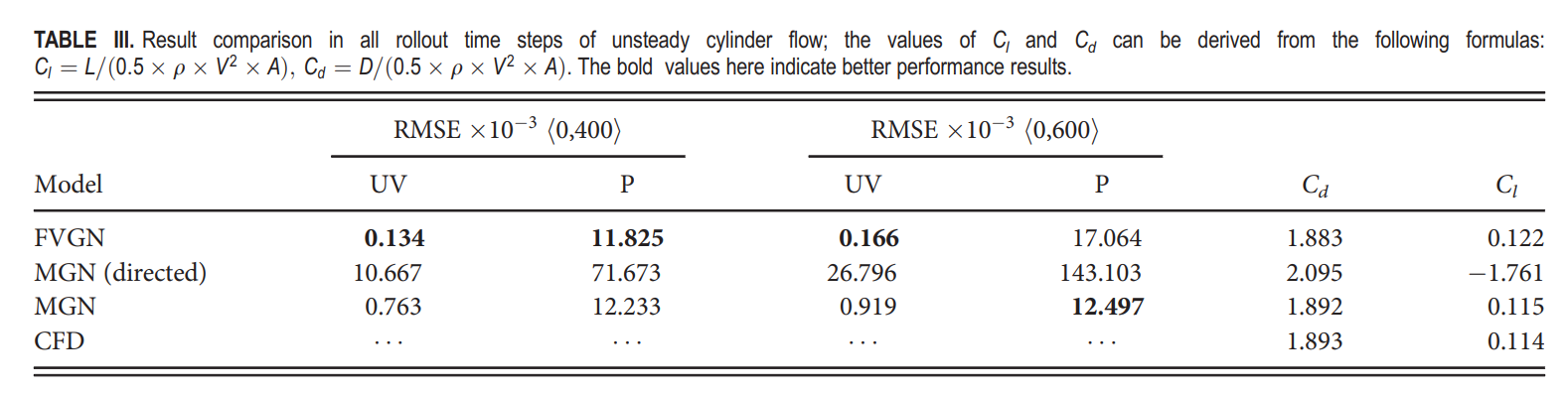
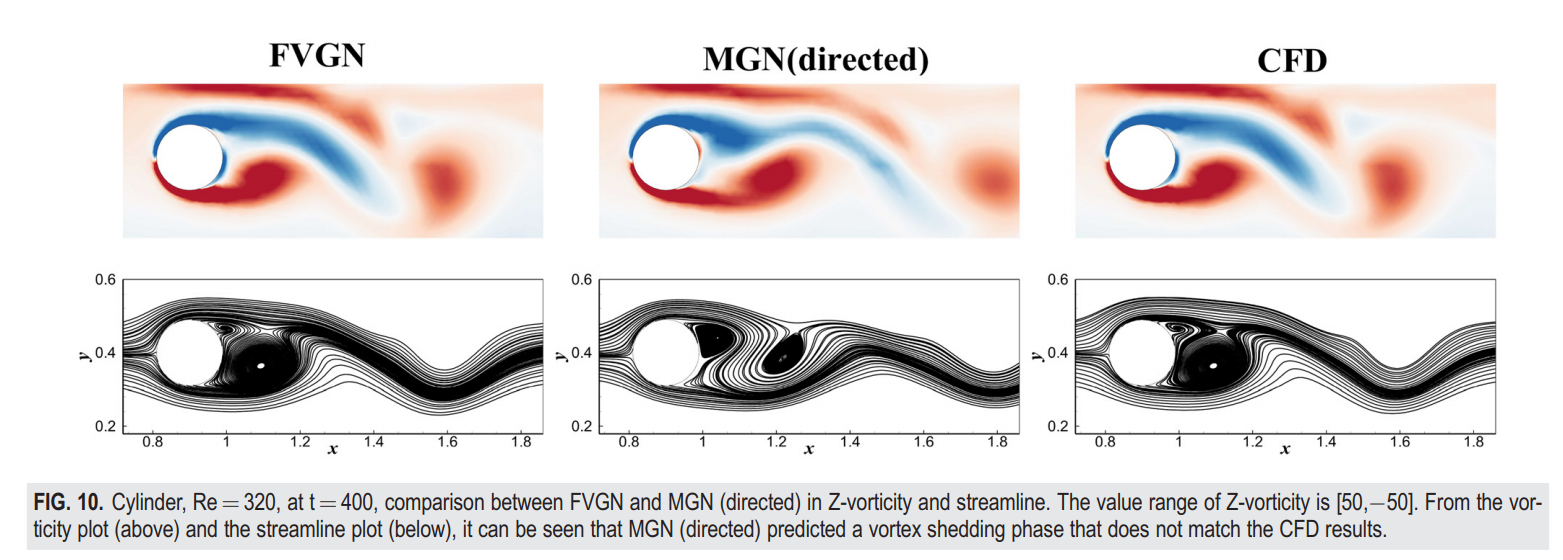
图 10. 圆柱体,雷诺数为320,在 t=400 时刻,FVGN 与有向 MGN 在 Z-涡度和流线图上的比较。Z-涡度的值域为 [50, -50]。从涡度图(上)和流线图(下)可以看出,有向 MGN 预测的涡脱相位与CFD结果不符。
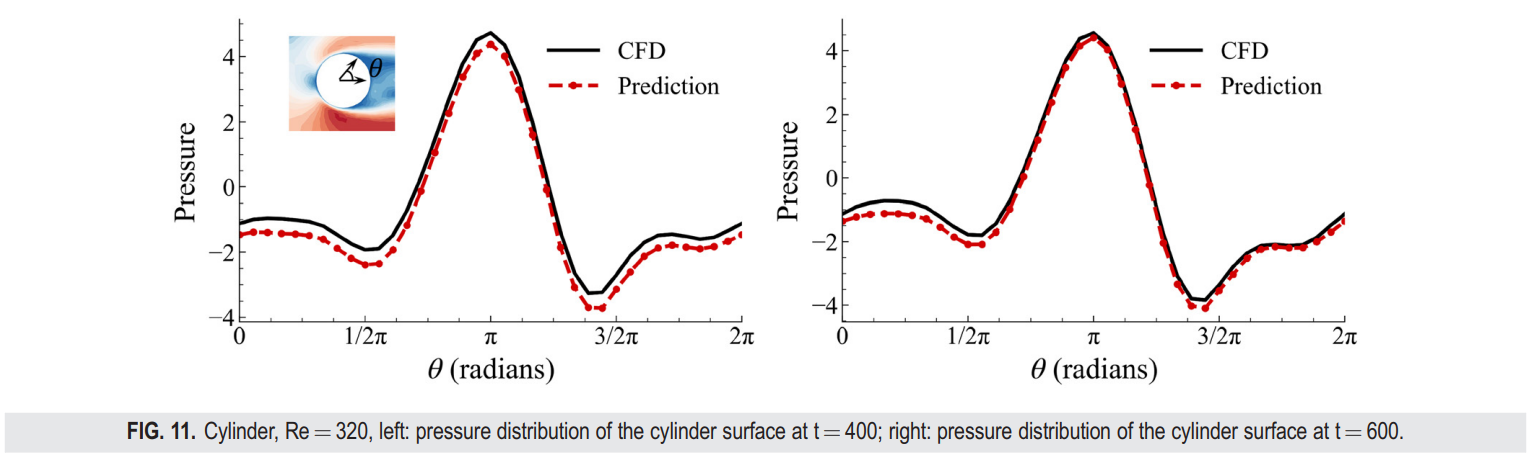
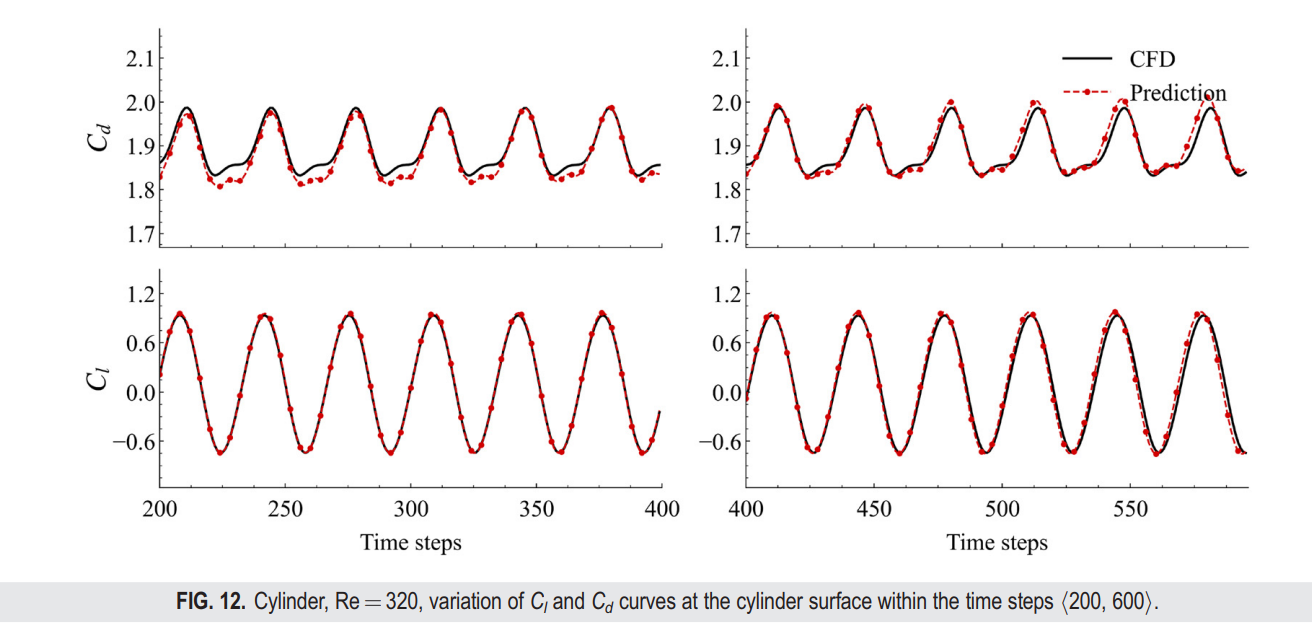
2. NACA0012 翼型
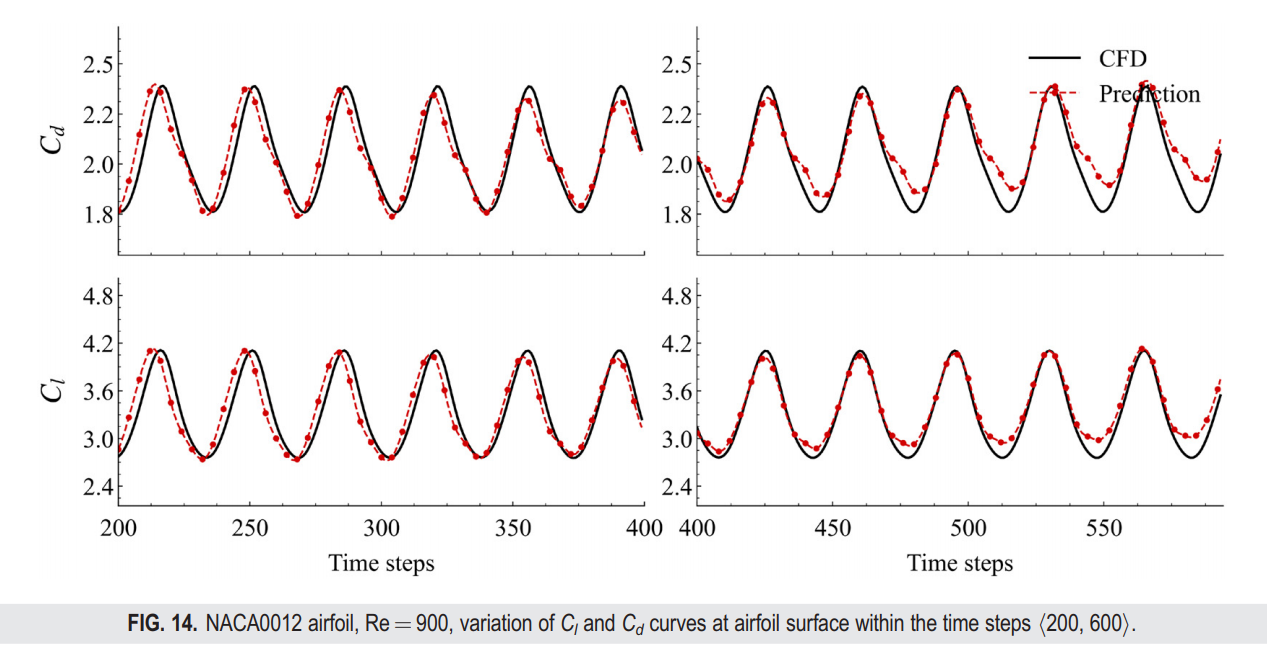
在本节中,我们展示了一个使用NACA0012翼型在HYBRIDFLOW数据集上的测试案例。构成此测试案例的雷诺数(Re=900)和攻角参数的组合,在训练集中从未出现过。因此,我们想要验证,在仅有少数翼型案例(占训练案例总数的10%)出现在训练集中的条件下,FVGN是否也能展现出良好的性能。入口流动条件简要描述如下:雷诺数为900,攻角为30°。我们选择这个攻角主要是为了评估FVGN面对更复杂的非定常流动时的性能,这对模型的泛化能力提出了非常高的要求。与此同时,FVGN仅使用训练集中的前400步数据进行训练,而MeshGraphNets和有向MeshGraphNets则使用完整的600步数据进行训练。这也使得该案例成为FVGN时间维度泛化能力的一个测试,所有这些都对FVGN提出了极高的要求。
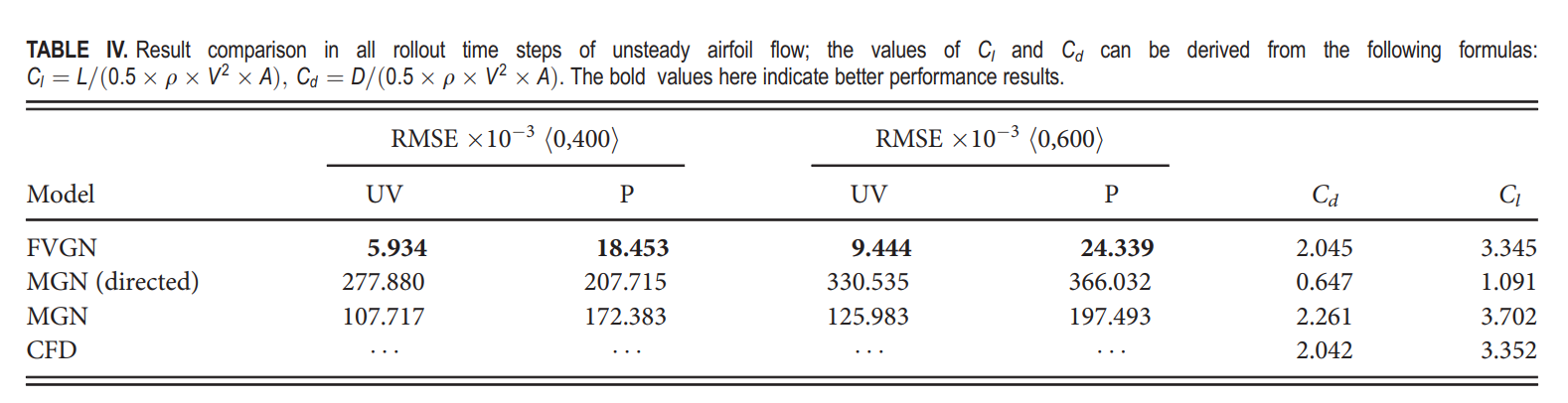
从x方向的速度场轮廓图(图13)中可以看出,在最后时刻,FVGN预测的x方向速度场与真实情况之间有一个相对明显的差异。这一差异集中在涡脱区域。同时,从表IV中可以看出,FVGN性能显著优于MeshGraphNets,有效验证了FVGN在几乎每一步的预测准确性都高于MeshGraphNets,确保其在第600步的预测准确性显著高于MeshGraphNets。无论是其有向形式还是无向形式,都凸显了FVGN的优势。特别值得注意的是表IV中升力和阻力系数的比较,FVGN显示出与CFD结果更为接近的近似度。图14中的升阻曲线也表明,FVGN在边界层附近可以表现出良好的性能。这不仅证明了模型在模拟翼型尾迹非定常分离流动方面的准确性,而且还展示了它在预测边界层附近的流动特性以及翼型的整体空气动力学特性方面的卓越性能,这在非定常流动分析中是一个非常关键的方面。
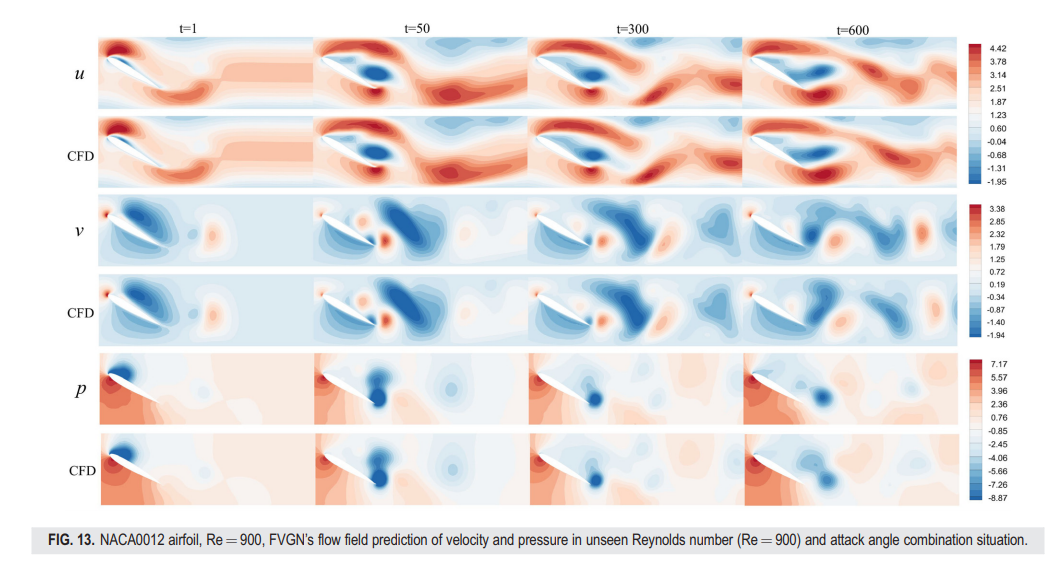
然而,我们仍然可以从图14中观察到,FVNG在之前圆柱流动案例中展示出了类似的情况。在第400个时间步之后,模型在升力和阻力系数的预测上产生了较大的误差。尽管我们从图15中可以看到,在第600个时间步的压力分布仍然相对准确,但模型实际上在升阻曲线的波谷处产生了振幅误差,同时在其他时间保持了相对较高的准确性。我们对这一现象的解释如下:模型在每个时间步都会在物理场产生误差,这些误差倾向于集中在尾迹区域(如图16所示),因此在每次消息传递过程中,尾迹区域产生的误差会影响到翼型附近的预测准确性。观察最终的时间平均场结果,FVGN在表IV中提供的升阻预测仍然非常接近CFD,这意味着本研究提出的模型仍然可以为机翼上的实际力情况提供准确的预测。
3. 矩形柱
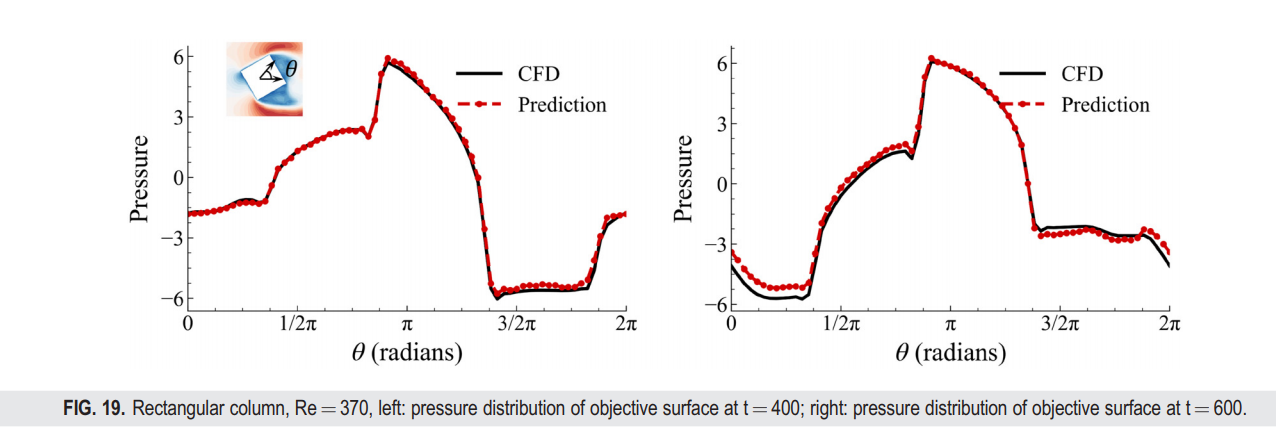
在HYBRIDFLOW数据集中的矩形柱测试案例里,FVGN的性能与MeshGraphNets在涉及有尖角边界障碍物的场景中进行了紧密的比较。在这个数据集的训练集中,矩形柱的例子仍然只占总训练例子数的10%。测试案例的雷诺数为370,旋转角度为25°,这组条件在训练集中也没有出现。FVGN仅使用训练集中的前400步数据,而MeshGraphNets和有向MeshGraphNets则依旧使用完整的600个时间步的训练数据。上述测试条件为两个模型提供了一个充满挑战的环境。
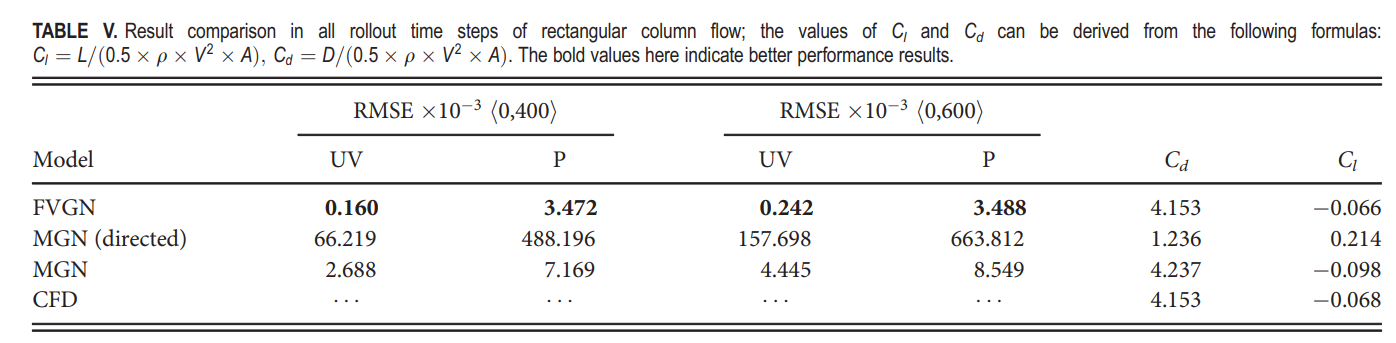
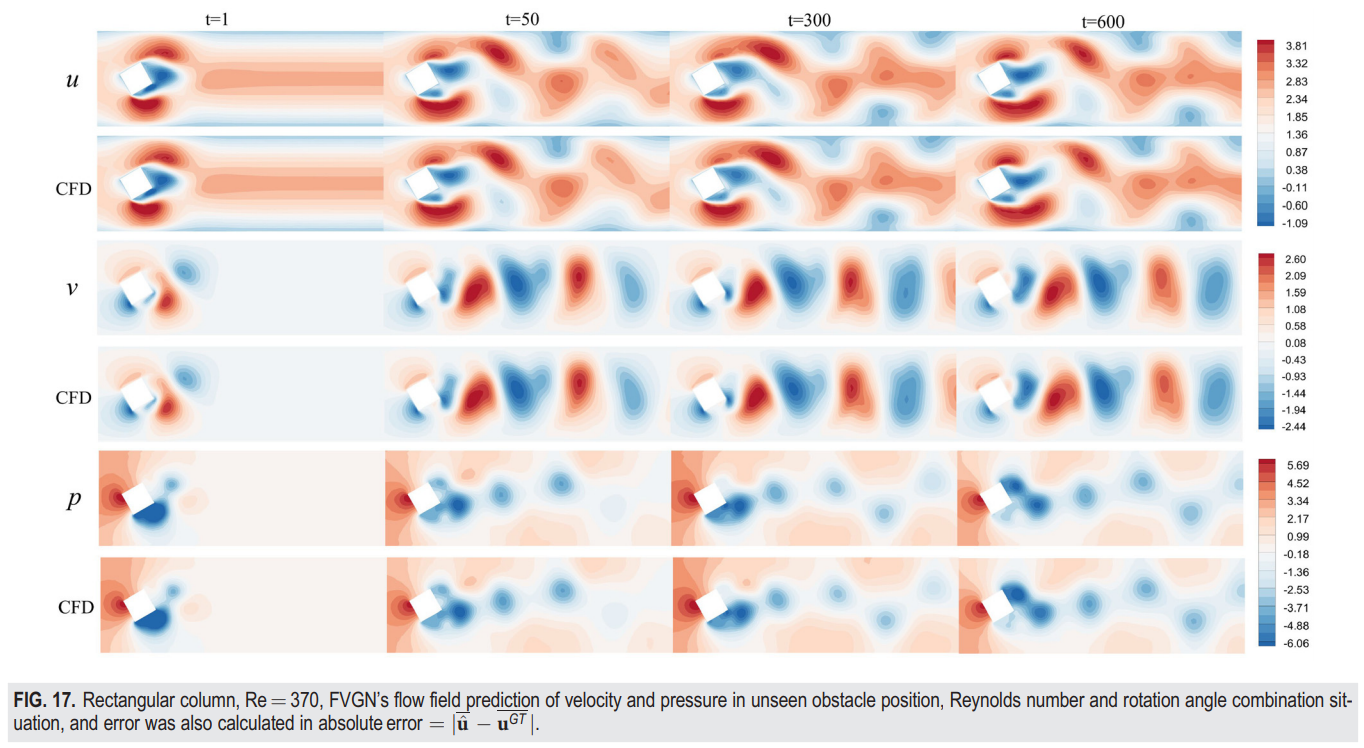
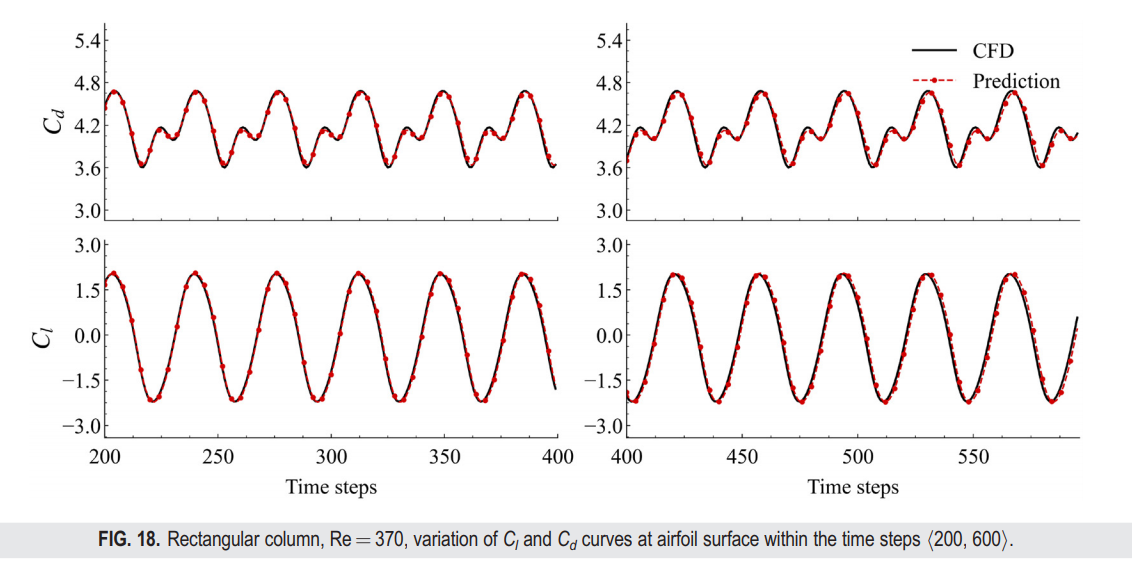
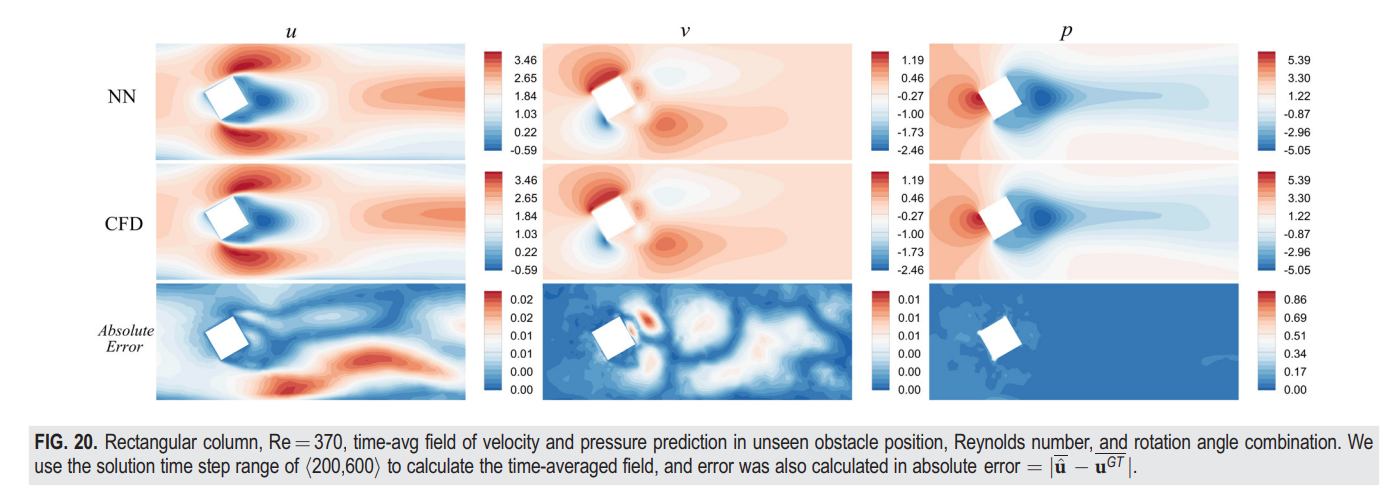
从瞬时时刻轮廓图的比较(图17)可以看出,FVGN很好地捕捉了流场中的涡脱现象,而如表V所示,FVGN在准确预测速度场和压力场方面均优于MeshGraphNets。此外,在前述的训练条件下,有向MeshGraphNets在预测升力和阻力系数(C_l);(C_d)方面表现出了相当大的不准确性。这一观察再次表明,减少模型隐藏空间的大小不仅会影响对训练集中主要案例的预测准确性(如第IV B 1节中提到的),而且还会显著降低模型的泛化能力。此外,FVGN和MeshGraphNets在预测空气动力参数方面都有更高的准确性。从图18可以看出,随着预测时间步数的增加,FVGN的预测逐渐与CFD结果出现相位偏移。这也可以从图19中看出,FVGN在最后时刻对表面压力分布的预测有一些误差。这一趋势也与第IV B 1节和IV B 2节一致,我们认为原因与NACA0012案例相同。如图20所示,速度场误差的主要集中区域在尾流区。由于图神经网络的消息传递机制,尾流中的误差不可避免地会传播到整个场域。总体来说,FVGN和MeshGraphNets都为空气动力参数提供了相对准确的结果,但考虑到最终的训练时间成本,FVGN的工程应用潜力仍然大于MeshGraphNets。
C. 几何泛化能力
多亏了图网络(GN)的组合泛化能力,基于GN的网络通常具有一定程度的泛化能力。第IV B 1节至IV B 3节主要展示了模型在测试案例中的性能,这些测试案例中使用了在训练集中未遇到的雷诺数-物体位置或雷诺数-攻角的组合。本节介绍了在HYBRIDFLOW数据集上,使用在未见过的椭圆形状和翼型类型上,保持所有超参数与前文提到的一致性条件下的模型训练结果。我们测试了NACA2412翼和一个主副轴比为1.33的椭圆。这三个测试案例的领域宽高比与训练集中的案例一致(即,3.6:0.6),它们的平均单元数量维持在(7000 - 8000)范围内。翼型测试案例是在30°的攻角和一个雷诺数800,而椭圆是在30°的旋转角度和320的雷诺数条件下进行测试的。
1. 椭圆
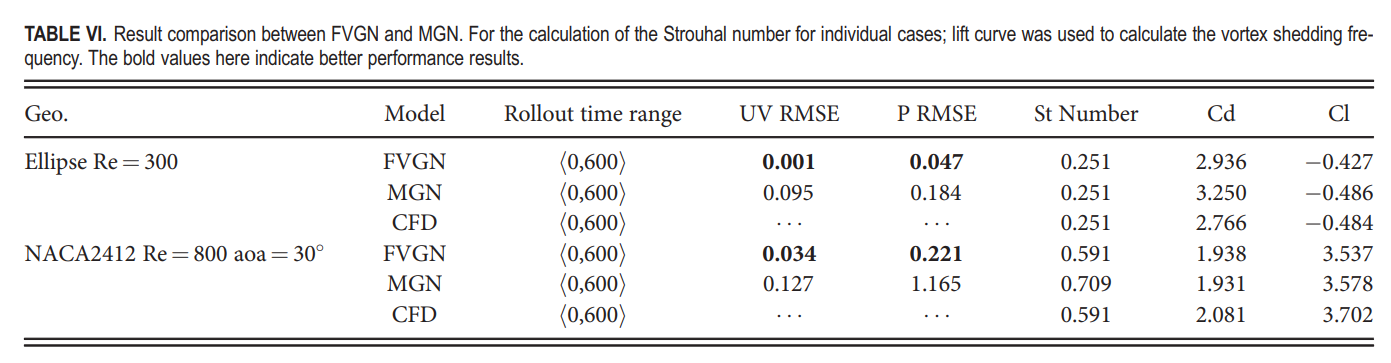
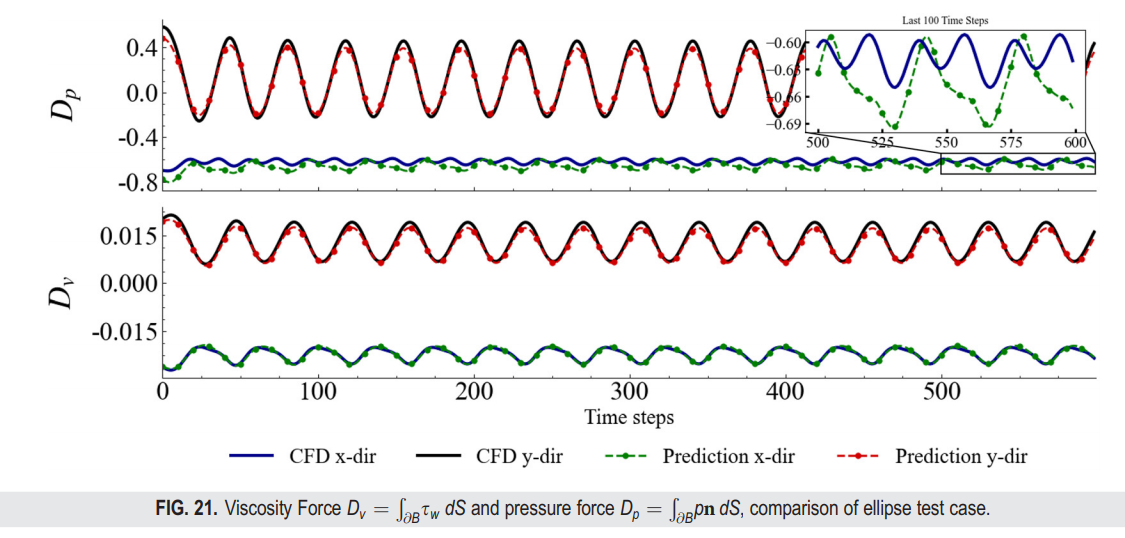
表VI显示了FVGN和MeshGraphNets在这两个测试案例中的性能。我们主要比较了瞬时压力场、斯特劳哈尔数以及升力和阻力系数。其中,我们使用升力系数来计算斯特劳哈尔数的频率。此外,对于不可压缩流体,预测压力场是最具挑战性的,因此压力场预测的准确性几乎直接决定了模型的最终性能。这有效地验证了我们的模型与直接数据驱动的模型相比,在几何形状上拥有优越的泛化优势。实际上,在HYBRIDFLOW数据集中,大多数案例都是关于绕圆柱的流动,因此从理论上讲,FVGN应该对椭圆形状有更强的泛化能力。表VI也证实了这一点;然而,如果我们深入分析椭圆表面的空气动力分析,我们可以看到FVGN在与求解器结果的( )预测中未能保持初始相位的一致性,特别是在图21中。特别是,在X方向的压力力预测中存在显著误差,这直接导致预测的阻力系数与CFD结果之间最高达到6%的偏差。
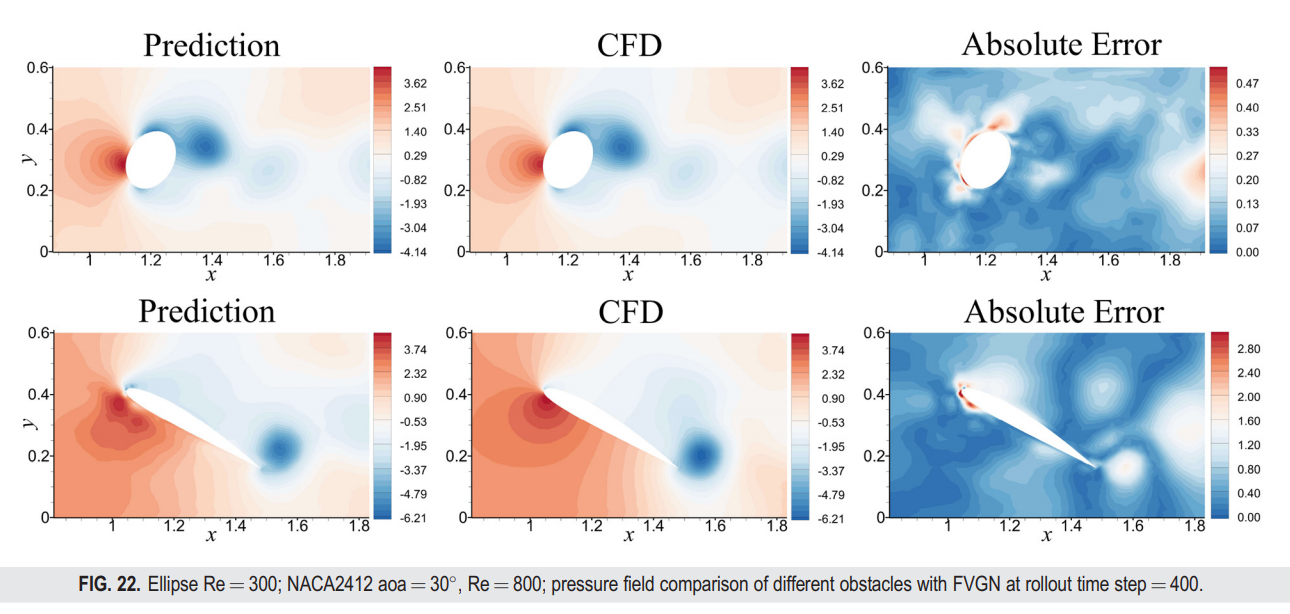
2. NACA2412
从图22可以看出,FVGN在预测NACA2412翼型的压力场时产生了显著的误差,尤其是在机鼻部分,FVGN错误预测了压力场的整体结构。然而,如表VI所示,FVGN实际上成功捕捉到了NACA2412翼型的涡脱频率,并且对机翼表面的升力和阻力系数的预测也相对准确。从上述案例的测试结果来看,仅仅依赖均方根误差(RMSE)或使用轮廓图来评估模型的性能是不够的。根据我们的实践经验,基于图神经网络的模型在面对未见过的几何形状时通常不会“发散”,而是从流场轮廓图的角度提供看似合理的结果,尽管与实际流动有显著差异。因此,增强FVGN的几何形状泛化能力将是未来工作的重点。
V. 方法有效性验证
我们在CYLINDERFLOW数据集和HYBRIDFLOW数据集上测试了FVGN和MeshGraphNets的性能,表VII和表VIII主要呈现了一些关键性能参数的比较。在HYBRIDFLOW数据集比较中,可以观察到随着单元/节点的平均数量增加,两种模型的训练时间和测试错误都有所增加。然而,FVGN的训练时间消耗仅增加了大约1天,而MeshGraphNets的增加了近4天。这主要是因为MeshGraphNets编码了双向边的特性,而FVGN仅编码了单向边的特性。随着单元数量的增加,显然MeshGraphNets将引入更大的计算成本。同时,从测试错误准确性比较的角度看,两个模型在这个数据集上的性能都不如在CYLINDERFLOW数据集上。主要原因是HYBRIDFLOW数据集的雷诺数分布范围更广。在HYBRIDFLOW数据集中,圆柱案例的特征尺度取为圆柱的直径,翼型案例取为翼弦长度,矩形柱案例取为对角线长度。因为翼弦长度明显大于圆柱的直径,这个数据集的主要误差集中在高雷诺数翼型案例上。前文提到的NACA0012测试案例也证明了这一点。
在本文中,我们主要提出了两种改进算法,用于在非结构化网格上使用图网络(GNs)进行非定常流场预测。第一个改进是引入物理约束损失,以试图减少每个展开步骤的误差,从而减轻模型在长时间展开中的累积误差现象。第二个改进是在整合有限体积方法时,将基于单元中心的图转换为基于顶点中心的图,使图网络能够在这两种网格类型的边集之间进行消息传递。这提高了消息传递的效率,并将MeshGraphNets中的双向边特性减少为单向边特性。因此,本节主要展示了应用上述方法中的任何一个或同时应用两种方法与现有技术相比所取得的性能改进。
A. 物理约束
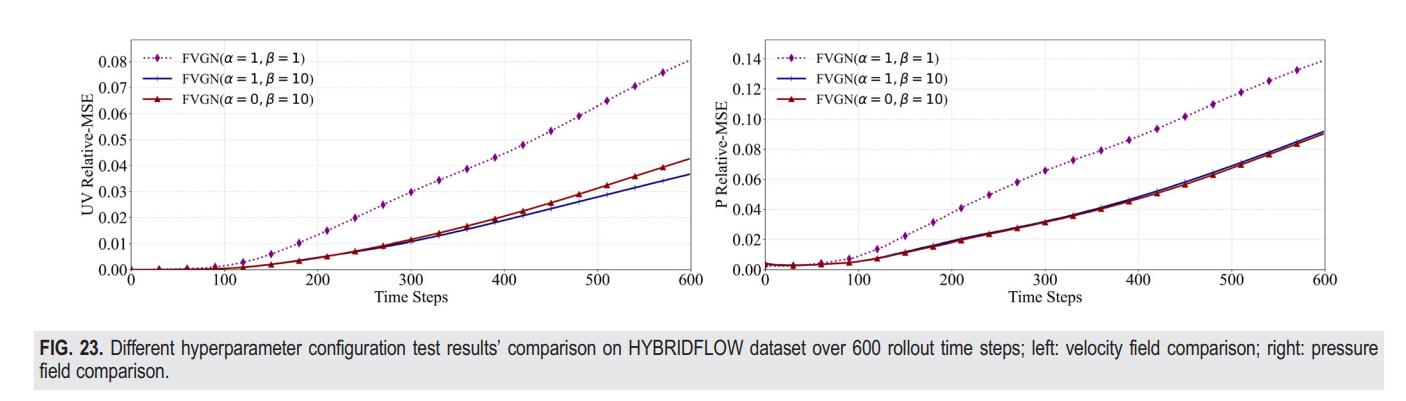
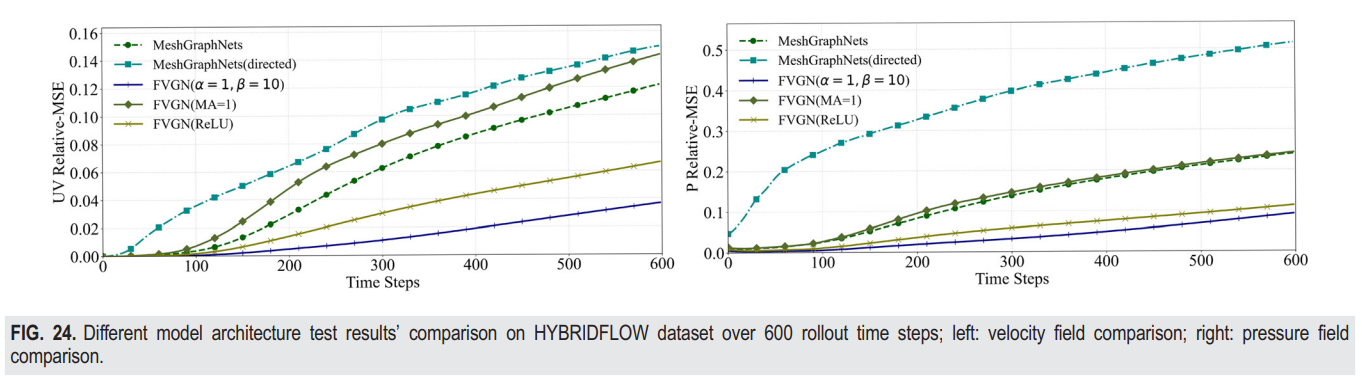
基于有限体积法在MeshGraphNets(有向)中引入物理约束是必要的,而且测试结果(见表VII和VIII)的200个案例从两个数据集显示,这是准确性提升的基本原因。同时,FVGN的物理约束实际上可以分为两类:是否引入连续性方程的约束(见图23和表VIII)。当移除连续性方程约束(即,将α设置为0在方程(11)中)时,可以看出FVGN(没有约束方程)在预测速度场时会表现出更严重的误差累积趋势,而这几乎不影响压力场的预测。这一现象的原因是可以理解的。我们之前用求解器计算高精度数值解来满足速度场,并将它们设置为动量方程(8)右侧的约束,这肯定满足了连续性方程。然而,这些数值解是储存在网格点或单元中心的,我们需要使用几何插值方法将它们插值到控制体的表面。这种插值算法将不可避免地引入额外的误差,因此降低了FVGN对方程(9)的预测准确性,从而影响了对流项表达式的预测准确性。总的来说,从表VIII中可以看出,引入连续性方程作为附加约束几乎不增加计算开销。因此,一个完整的FVGN应该包括基于动量方程和连续性方程的约束。
同时,我们也展示了所有超参数设置为1的实验结果,如图23和表VIII所示。可以看出,无论是速度场还是压力场都显示出了显著的误差累积趋势。原因是我们的模型仅使用速度场作为每轮预测的输入,而动量方程的低权重导致了补偿项Q预测结果的大偏差,最终导致了Δu的低预测准确度,使得模型的累积误差随时间增加。总结我们的实践结果,动量方程的权重必须高于其他监督项,引入连续性方程的约束可以提高模型的预测准确度,而不会显著增加计算成本。
B. 双重消息聚合机制
在整个FVGN的前向过程中,仅编码定向边显著降低了梯度计算成本,这是在反向传播过程中减少可学习参数相比MeshGraphNets的双向边编码方法。这正是FVGN改进训练效率的关键。然而,简单地用定向边替换双向边必然会影响图神经网络消息传递层的效率,导致最终预测精度降低。如图4所示,我们首先尝试在允许单元块的FVGN只进行一次消息聚合的同时,保持定向边编码方法。也就是说,在图4中展示的单元块处理中,我们直接将所有边特征 ( ) 聚合成一个单元,然后将这个单元的原始特征进行拼接。并输入到Cell-MLP ( ) 中进行特征更新。这个操作与MeshGraphNets在节点块中如何聚合共享边特征到顶点并在进入Node-MLP进行特征更新前拼接顶点的原始特征的方式非常相似,如图4(d)所示。从FVGN(MA=1)的误差累积曲线图24和性能结果表VIII可以看出,与使用双重消息聚合机制的FVGN相比,性能明显较差。同时,表VIII中FVGN(MA=1)只在训练效率上有轻微的改进,与准确度的显著损失相比可以忽略不计。因此,在消息传递层引入双重消息聚合机制是必要的。
C. 计算效率比较
在这一节中,我们主要比较了FVGN和MeshGraphNets在前向过程中消息传递方法的效率差异,并主要展示了本研究提出的双重消息聚合过程的细节。
如图3所示,FVGN加入了一个额外的操作“集成到中心”,与MeshGraphNets(见图25)相比。我们将这一过程称为空间集成层(简称SIL)。SIL的引入显著提升了模型的性能,并且我们在第六部分进行了消融实验来验证其有效性。此外,SIL的包含不可避免地增加了模型的时间复杂度;然而,当在GPU上实施时,这种增加是可接受的。在CPU上实现的SIL的时间复杂度可以表示为O(2N + 3N),接近O(n)。然而,在GPU上,这一时间复杂度在理想情况下变为O(1),因为SIL只涉及将每个面的通量乘以当前表面向量并求和结果。对于每个控制体积中的每个面,计算是在GPU上同时执行的。因此,与MeshGraphNets相比,我们模型的前向时间消耗几乎线性增加。
表IX具体展示了FVGN在引入空间集成层后,单次前向传播过程中GPU的时间消耗。从表中的数据可以看到,与MeshGraphNets相比,FVGN的前向过程并没有显示出显著的时间增加。此外,这里展示的所有GPU数据都是在单个V100S GPU上获得的。对于MeshGraphNets在CYLINDERFLOW数据集上的GPU/CPU时间消耗,我们直接采用了参考文献9中的数据。值得注意的是,输入到MeshGraphNets的只是单个网格Gv,所以解码目标对MeshGraphNets来说仅限于顶点。在三角网格中,顶点数通常少于单元数,对于同一网格,其比率大约是1:2,而顶点与边的比率是1:3(见表X)。因此,FVGN消耗更多的解码时间是合理的。然而,表IX还展示了在CPU上测试我们模型时消耗的时间。这里我们只是展示了一个时间消耗的趋势,这可能并不准确反映实际应用中消耗的时间,因为大多数数值求解器都基于CPU计算。最后,从表中可以看出,我们的方法和MeshGraphNets在时间消耗上比传统数值求解器在计算流体力学(CFD)领域大约有五倍的优势。

VI. 结论
在本研究中,通过整合有限体积方法中的集成概念,我们基于图神经网络提出了一种新颖的空间集成层(SIL),以实现物理约束。这显著提高了图神经网络在非定常流动预测场景中的预测准确性。同时,我们利用有限体积方法中的扩展模板方法,在图神经网络的消息传递层构建了一个双重消息聚合过程。这极大地增强了单向边情况下消息传递的效率,从而补偿了由于单向边带来的性能损失。我们可以将本研究的所有改进总结如下:训练效率的提升是由于我们将带有双向边的无向图转换为带有单向边的有向图,从而在训练过程中减少了计算开销。预测准确性的提升主要是由于基于有限体积方法引入的物理约束和双重消息聚合过程的引入。在此基础上,由于更高的消息传递效率,我们仅使用了CYLINDERFLOW训练集前50%的时间步长数据和HYBRIDFLOW训练集前66%的时间步长数据,以及在FVGN的训练过程中较少的训练轮次,进一步显著减少了训练开销。最终,这些改进使得本研究提出的模型在准确性和效率方面都取得了显著进展。
为了验证上述改进的有效性,本研究在两个数据集上测试了FVGN的性能,包括2000个具有不同雷诺数和几何形状的案例,并将其与基于完全数据驱动方法的MeshGraphNets进行了比较。结果显示,当使用有限数量的时间步长数据进行训练时,FVGN在训练时间开销和最终预测准确性方面都优于MeshGraphNets。在HYBRIDFLOW测试结果中,FVGN在速度场预测的准确性上相比MeshGraphNets提高了77%,训练时间开销减少了多达56%。本研究还从HYBRIDFLOW测试集中选取了三个代表性测试案例,对比分析了表面压力分布和升阻系数曲线。从这些结果来看,FVGN在大多数案例中都优于MeshGraphNets。
最后,本研究还对几何形状的泛化能力进行了测试,以验证结合物理归纳偏见的模型相比于完全数据驱动的模型具有更好的泛化能力。从最终结果来看,FVGN在捕捉涡脱频率方面比MeshGraphNets更为准确,但在预测升阻系数方面仍存在显著误差。尤其是在椭圆案例中,FVGN在压力场的大预测误差导致了x方向上压差阻力的糟糕预测,这直接影响了最终的阻力系数,与CFD结果相差近6%。然而,这一结果仍然比MeshGraphNets的18%阻力系数预测误差显著更好。
当我们对几何形状进行泛化性测试时,我们控制了测试案例的网格密度和时间步长长度,以确保与训练集中的基本一致。这是因为,根据我们的实践经验,如果测试中使用的网格单元数量与训练集的平均网格密度偏差过大,或者采取不同的时间步长,则测试结果往往会较差。因此,这也将是我们未来工作的一个重点。
从上述结果来看,尽管与现有工作相比,FVGN在准确性和效率方面取得了进步,但在实际应用中仍然面临两大挑战。首先,由于潜在空间大小的减少以及本文中使用的训练条件,在面对更复杂的HYRBRIDFLOW数据集时,如果使用流场初始化的初始时刻的速度场作为时间 ( ) 的输入,FVGN在生成非定常状态的关键时刻预测的流场可能会与CFD结果不同,从而导致相位差异。相位差异的存在使得RMSE的计算不够理想。因此,在构建HYRBRIDFLOW数据集时,我们实际上使用了物理时间步长的<15 614>流场作为训练数据,即我们允许FVGN从生成非定常现象的关键时刻开始预测,而不是从物理时间步长 ( t = 0 ) 开始训练和预测FVGN。尽管选择更大的潜在空间大小并延长训练步数可能会缓解这个问题,但这必然会导致更大的时间和空间复杂度,从而偏离本文的目标——“在模型性能与计算成本之间找到平衡”。
其次,FVGN和大多数数据驱动模型在预测非定常流场任务中共享一个核心问题:获取高精度数据集。特别是,在非结构化网格离散化下生成高精度非定常数据集非常耗时。这个挑战不仅影响了模型训练的有效性,而且可能也限制了它在更广泛的场景中的适用性。因此,在未来的研究中,我们计划尝试将有限体积方法在非结构化网格上的完整离散化过程引入图神经网络,以实现完全无监督的训练和预测。从而实现真正摆脱对高精度数据集依赖的目标,同时提高FVGN在任何初始时刻预测非定常流场的能力,覆盖更广范围的雷诺数。
结语
-
持续分享更新AI4PDEs&AI4CFD前沿进展 -
开源代码、启发性文献 -
感兴趣请关注微信公众号:AI4CFD
本文由 mdnice 多平台发布

















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









