







 本文探讨了列簇在大数据存储中的应用及其实现原理,重点介绍了通过自定义Lucene的codec模块来实现列簇功能的方法。
本文探讨了列簇在大数据存储中的应用及其实现原理,重点介绍了通过自定义Lucene的codec模块来实现列簇功能的方法。
背景
'列簇'功能是一个较典型的存储需求。从名字中也可以看出其作用,就是将一张表中的不同的列的存储隔离开来,具体的说就是不同的列有不同的存储目录。在开源的世界列簇并不少见,常见的支持列簇的存储产品有hbase、RocksDB(columnfamily)等,列簇功能其实也成为了大数据存储组件的一个典型功能。本篇文章就探讨一下相关产品中'列簇'的实现原理。
使用场景
将不同的列分目录存储有以下使用场景:
- 当不同的数据列需要设置不同的生命周期,用于后期的数据的淘汰时;
- 当为了获得较好查询性能并兼顾成本,需要根据表中不同列不同的查询频率,将查询频率较高的列的存储在较好硬件上时;
- 当表中某字段值过大并且查询频率不高的字段可能成为查询和合并性能瓶颈,占用过多cpu和io资源时。
实现原理
近日在参加一场大数据峰会时有幸接触到了一款可实现列簇的产品,引起了笔者的兴趣。由于兴趣使然,笔者便对其进行了深入了解。不同于业内常见的支持列簇的存储产品,该产品是一个以lucene为原型构建的索引引擎。原生的lucene是不支持列簇功能的,那么增加列簇的实现也就需要对lucene的存储层做一些修改。
Lucene是一个扩展性较好的软件包,几乎所有的重要代码模块都支持用户自定义,其中就包括与文件交互的codec模块,codec模块包含lucene各个文件的读写操作,程序开发者可以自定义存储结构,实现针对不同列的不同的存储结构,下面就来看下如何实现自定义codec。
先看一下打开一个lucene索引的步骤:
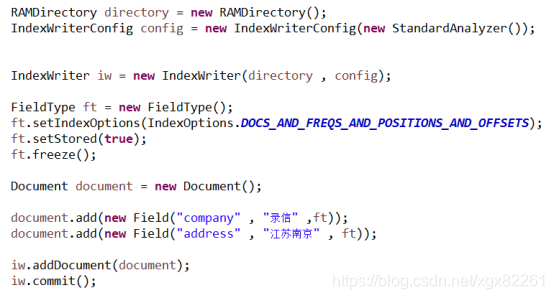
如果用户不指定codec的话使用的是默认的lucene53codec,
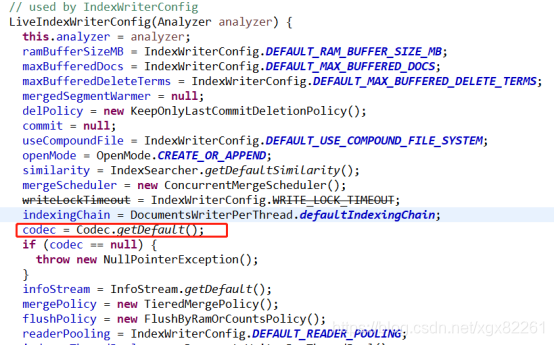

看下lucene53codec里面对各个文件读写的实现,codec下面对应的是好多个format,每个format对应一个文件的读写操作。

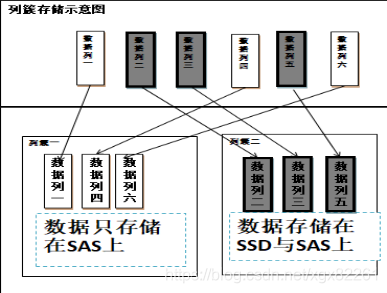
列簇需要对索引文件和数据文件分别列簇对应的分别是storedFieldsFormat、postinsFormat、docValuesFormat,每个format对应的物理文件为:
storedFieldsFormat:.fdt .fdx;
postinsFormat:.tim .tip .doc;
docValuesFormat:.dvm .dvd。
自定义codec的实现
1)编写自定义codec类
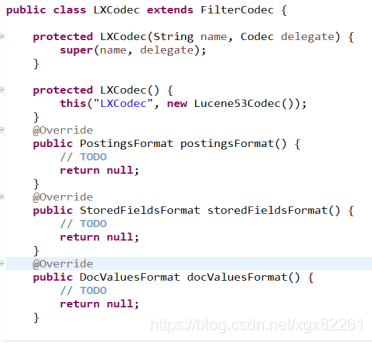
2).重写codec类中各种format的实现;
3)在入口指定自定义codec;
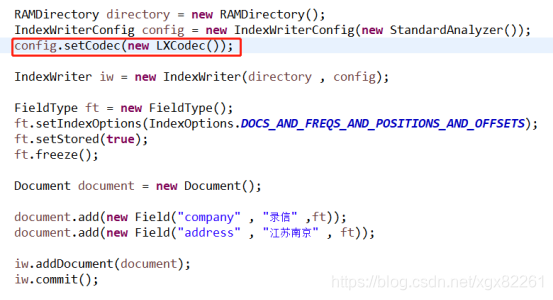
Format是于各种文件打交道的入口,在实现自定义codec后只需要继续实现对应的format就可以了。

















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









