 Titanic生存分析:数据清洗与特征工程
Titanic生存分析:数据清洗与特征工程





 本文详述了对Titanic数据集进行数据分析的过程,包括理解数据、数据清洗(处理缺失值)、特征提取(数值型、分类数据、字符串类型)和特征选择。通过相关系数法筛选关键特征,并构建机器学习模型进行训练和评估。
本文详述了对Titanic数据集进行数据分析的过程,包括理解数据、数据清洗(处理缺失值)、特征提取(数值型、分类数据、字符串类型)和特征选择。通过相关系数法筛选关键特征,并构建机器学习模型进行训练和评估。
1.提出问题:符合哪些特征的人在Titanic遇难时获救的可能性更高
2.理解数据
2.1 导入数据
import numpy as np
import pandas as pd
train = pd.read_csv('data/Train.csv')
test = pd.read_csv('data/Test.csv')
print('训练数据集:',train.shape)
print('测试训练集:',test.shape)
训练数据集: (891, 12)
测试训练集: (418, 11)
2.2 合并数据,进行清洗
full = train.append(test,ignore_index=Ture)
print ('合并后的数据集:',full.shape)
合并后的数据集: (1309, 12)
2.3 查看数据集信息
full.info()

我们发现数据总共有1309行。
其中数据类型列:年龄(Age)、船舱号(Cabin)里面有缺失数据:
1)年龄(Age)里面数据总数是1046条,缺失了1309-1046=263,缺失率263/1309=20%
2)船票价格(Fare)里面数据总数是1308条,缺失了1条数据
字符串列:
1)登船港口(Embarked)里面数据总数是1307,只缺失了2条数据,缺失比较少
2)船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大
3.数据清洗
3.1 数据预处理
缺失值处理:
在机器学习算法中,许多训练模型算法不能有空值
常用的补全缺失值方法有:
(1)数值型数据,可以使用平均数,众数进行补全
(2)如果是分类数据,用最常见的类别取代
(3)若处理的数值比较重要,则用模型预测缺失值补全
处理数值型缺失值:
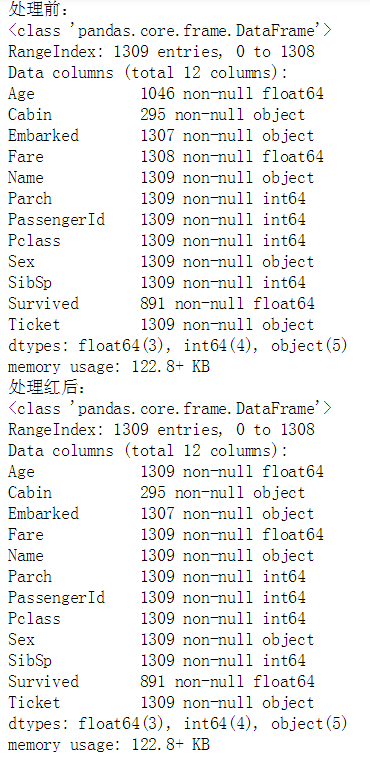
print('处理前:')
full.info()
#年龄(Age)
full['Age']=full['Age'].fillna( full['Age'].mean() )
#船票价格(Fare)
full['Fare'] = full['Fare'].fillna( full['Fare'].mean() )
print('处理红后:')
full.info()
#检查数据处理是否正常
full.head()
处理字符型缺失值:
字符串列:
(1) 登船港口(Embarked)里面数据总数是1307,只缺失了2条数据,缺失比较少
(2) 船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大
登船港口(Embarked):
出发地点:S=英国南安普顿Southampton
途径地点1:C=法国 瑟堡市Cherbourg
途径地点2:Q=爱尔兰 昆士敦Queenstown
查看数据样式,进行补全:
full['Embarked'].value_counts()
对’Embarked’特征,其中’S’是比例最大的值,按照S进行填充
full['Embarked'] = full['Embarked'].fillna( 'S' )
对’Cabin’特征,缺失值比较多,将缺失值用特征‘U’代替
full['Cabin'] = full['Cabin'].fillna( 'U' )
检查数据是否正常
full.head()

数据处理后,要对数据进行检查,确保没有丢失数据和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1782
1782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









