






 博客主要围绕目标检测相关的网络结构展开,重点介绍了CSPNet。详细阐述了CSPNet中的CBM和Res - unit,如CBM1负责下采样2倍,其他CBM改变通道数;Res - unit由特定卷积层构成。还提及后续的SPP、PAN和head,以及CSP模块与下采样的关系。
博客主要围绕目标检测相关的网络结构展开,重点介绍了CSPNet。详细阐述了CSPNet中的CBM和Res - unit,如CBM1负责下采样2倍,其他CBM改变通道数;Res - unit由特定卷积层构成。还提及后续的SPP、PAN和head,以及CSP模块与下采样的关系。
目录
1 网络结构
参考深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解_江大白*的博客-优快云博客_yolo讲解
1.1 CSPNet
图中CSP1 表示x=1, 即有1个残差组件Resunit
CSP2表示x=2, 即有2个残差组件Resunit
CSP2表示x=8, 即有8个残差组件Resunit
我们先看以CSP1为例:

1.1.1 CBM
假设X= 1
把图中5个CBM编个号,
CBM1 =

CBM1 是负责下采样2倍的,Conv中的k表示卷积核大小是3x3, s表示滑动步长,s=2表示把特征图的宽高缩小2倍,BN是批量归一化,Mish是激活函数
CBM2=

CBM2= 卷积层都是1x1的卷积核,并且步长都为1
而CBM3,CBM4,CBM5和CBM2是一样的,k和s都是1,区别就是卷积层的输出通道数可能有变换,所以每个CSP模块,只有最开始的CBM1是负责下采样2倍,其他的CBM都不会改变特征图的大小,只会改变特征图的通道数。
1.1.2 Res-unit
再看一下Res-unit
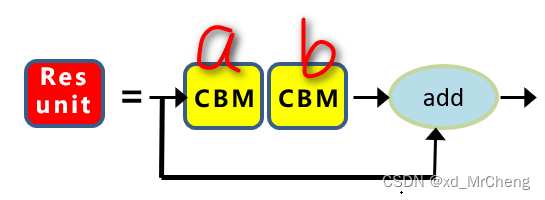
把Resunit中的两个CBM编个号,叫CBM_a, CBM_b
CBM_a =

CBM_b =

CBM_a是卷积核 1x1,且步长为1的卷积层
CBM_b是卷积核 3x3,且步长为1的卷积层
如果是Resunit x 2, 也就是2个残差组件,即CSP2对应的
Resunit x 2 =

类似Resunit x 8 也是一样的,就是8个残差组件
再看后面的SPP和PAN,以及head
先参考一下YOLOv4网络详解_太阳花的小绿豆的博客-优快云博客_yolov4网络结构图
回头自己在重新绘制一下
下图中的5个DownSample就是上面我们说的5个CSP模块
从上到下 分别对应CSP1 CSP2 CSP8 CSP8 CSP4
每经过一个CSP模块, 就会下采样两倍


















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









