




 本文档详细记录了一次使用MPI进行矩阵乘法并行计算的实验过程。实验在Windows11环境下,通过C++编程,利用MSMPI库,分别用1、2、4、8个进程完成了2048*2048双精度矩阵的乘法。实验结果显示,随着进程数增加,运行时间减少,加速比提升,但2进程时加速比不明显,因主进程不参与计算。代码中通过扩展矩阵和合理分配计算任务实现了并行计算。
本文档详细记录了一次使用MPI进行矩阵乘法并行计算的实验过程。实验在Windows11环境下,通过C++编程,利用MSMPI库,分别用1、2、4、8个进程完成了2048*2048双精度矩阵的乘法。实验结果显示,随着进程数增加,运行时间减少,加速比提升,但2进程时加速比不明显,因主进程不参与计算。代码中通过扩展矩阵和合理分配计算任务实现了并行计算。
矩阵乘法的MPI并行实验报告
一、实验要求:
(1) 分别用 1,2,4,8 个进程完成矩阵乘法(同一个程序):A * B = C,其中 A,B,C 均为 2048*2048 双精度点方阵,0号进程负责初始化矩阵 A,B 并将结果存入 0 号进程。
(2) 绘制加速比曲线;
二、实验环境:
- 操作系统:Windows11
- 编程语言:C++(使用MPI接口)
- 编译器:VC++
- 核心库:MPI(MSMPI)
- 编程工具:Visual Studio 2022
- CPU:AMD Ryzen 7 6800H with Radeon Graphics 3.20 GHz
- 内存:16GB
三、实验内容:
1. 实现思路
将可用于计算的进程数分解为a*b,然后将全体行划分为a个部分,全体列划分为b个部分,从而将整个矩阵划分为相同的若干个块。每个子进程负责计算最终结果的一块,只需要接收A对应范围的行和B对应范围的列,而不需要把整个矩阵传过去。主进程(0号进程)负责分发和汇总结果。
注意:
(1) 为了保证平均划分,矩阵需要扩展,即扩展至负责计算的进程数的倍数,扩展部分数据置为0,以保证结果准确性。
(2) 通信接口使用Send/Recv,所以进程编号要管理好。另外,主进程只负责初始化矩阵及分发和汇总结果。
2. 实验结果
(1) 设置为单进程,即串行
- 单进程命令行参数设置(如图1)

图 1 单进程时命令行参数设置 - 单进程运行结果,约97.20s(如图2)
 图 2 单进程时运行的时间花销
图 2 单进程时运行的时间花销
(2) 设置为2进程 - 2进程命令行参数设置(如图3)
 图 3 程序2进程运行时命令行参数设置
图 3 程序2进程运行时命令行参数设置 - 2进程运行结果,约75.43s(如图4)
 图 4 程序2进程时运行的时间花销
图 4 程序2进程时运行的时间花销
(3) 设置为4进程 - 4进程命令行参数设置(如图5)
 图 5 程序4进程运行时命令行参数设置
图 5 程序4进程运行时命令行参数设置 - 4进程运行结果,约17.17s(如图6)
 图 6 程序4进程时运行的时间花销
图 6 程序4进程时运行的时间花销
(4) 设置为8进程 - 8进程命令行参数设置(如图7)
 图 7 程序8进程运行时命令行参数设置
图 7 程序8进程运行时命令行参数设置 - 8进程运行结果,约9.05s(如图8)
 图 8 程序4进程时运行的时间花销
图 8 程序4进程时运行的时间花销
由上述运行结果可得表格1
表格 1 程序运行结果分析表
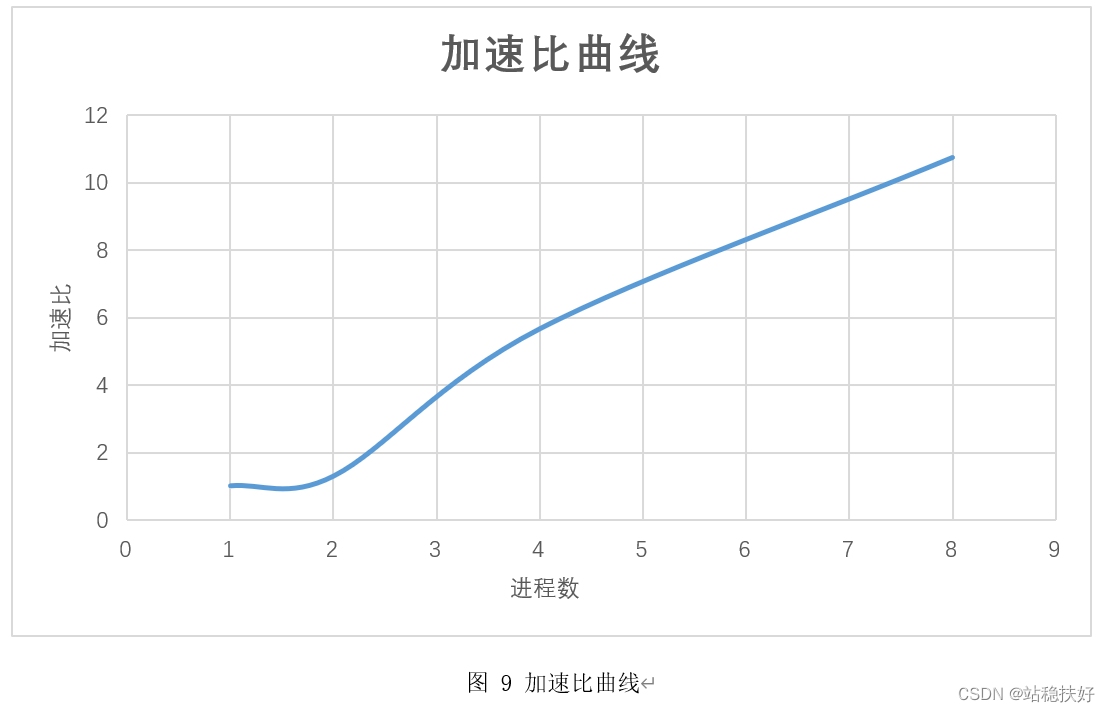
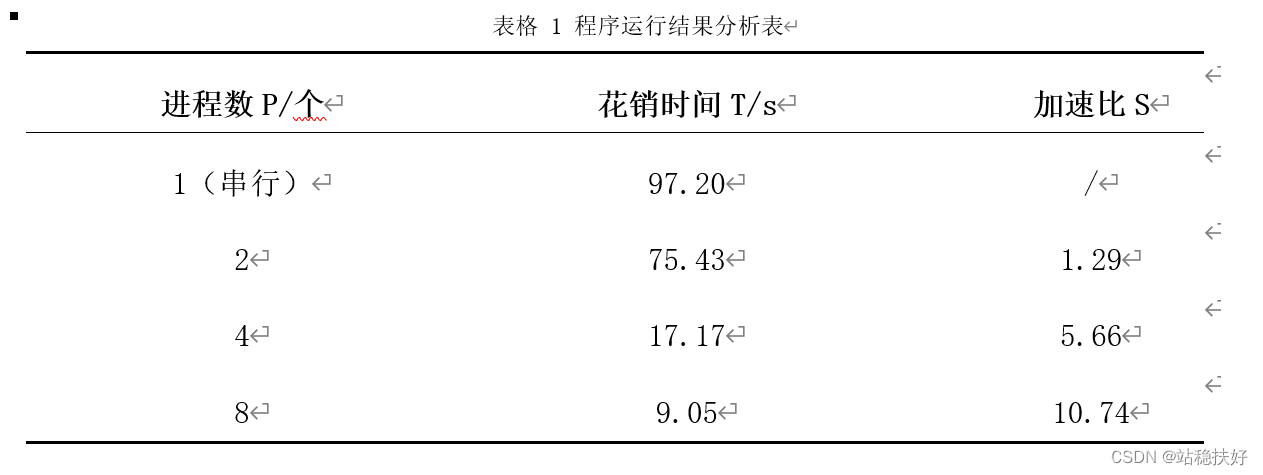 由表格1可知,随着进程数的增加,程序运行时间也随之减少,加速比随之增加。但是,可以注意到,单进程和2进程的时间花销相差并不大,2进程时的加速比仅为1.29,其原因是程序在多进程运行时,由于设计思路是主进程(0号进程)并不参与计算,只负责初始化矩阵和分发汇总结果,故2进程时程序优化并不明显。当增加到4进程及8进程时,程序运行时间大大减少。其加速比曲线如图9。
由表格1可知,随着进程数的增加,程序运行时间也随之减少,加速比随之增加。但是,可以注意到,单进程和2进程的时间花销相差并不大,2进程时的加速比仅为1.29,其原因是程序在多进程运行时,由于设计思路是主进程(0号进程)并不参与计算,只负责初始化矩阵和分发汇总结果,故2进程时程序优化并不明显。当增加到4进程及8进程时,程序运行时间大大减少。其加速比曲线如图9。
由于实验要求的矩阵为2048*2048的双精度浮点方阵,故在代码完成后,先将矩阵维度设置为7,以检验程序结果是否准确,同时对于生成的随机数不设置种子,以保证每次程序运行的数据一致,从而确保实验数据准确,检验结果如图10所示;
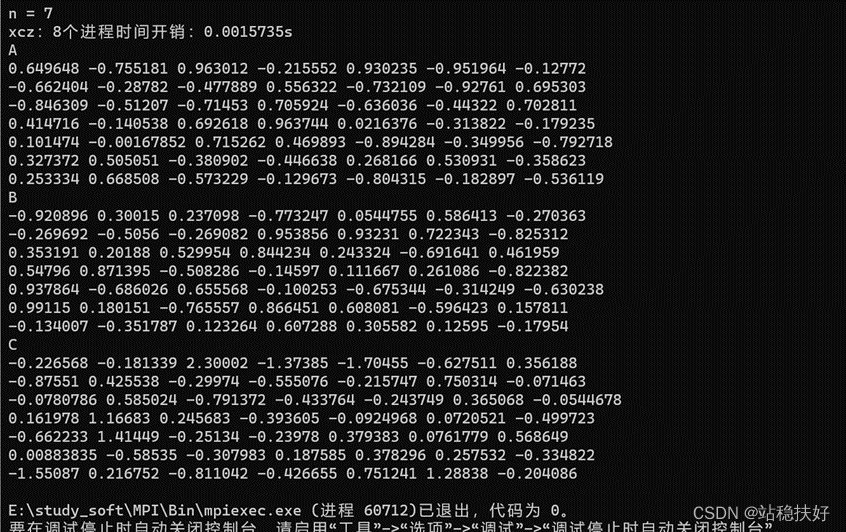 图 10 检验矩阵数据
图 10 检验矩阵数据
四、实验总结:
经过此次实验,
- 熟悉掌握了MPI几个基本函数,知晓Send/Recv通信接口的使用;
- 进一步了解MPI通信的相关原理;
- 掌握基本的MPI编程能力;
五、 附录(代码):
#include <iostream>
#include <cstdlib>
#include <ctime>
#include <cmath>
#include <string>
#include "mpi.h"
#define NUM 2048 //矩阵大小
using namespace std;
//打印数组(测试使用)
void printfArray(double* A, int length) {
for (int i = 0; i < length; i++) {
for (int j = 0; j < length; j++) {
cout << A[i * length + j] << " " ;
}
cout << endl;
}
}
//扩展矩阵并且初始化,多余部分填充0
void matGene(double* A, int size, int actual_size) {
// actual size: 使用的矩阵极可能大于原始大小
for (int i = 0; i < actual_size; i++) {
for (int j = 0; j < actual_size; j++) {
if (i < size && j < size)
//初始化矩阵,随机生成双精度浮点数[-1,1]
A[i * 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









