




参考资料:神经网络与深度学习
Batch Size 选择
批量大小越大,随机梯度的方差越小,引入的噪声也越小,训练也越稳定,因此可以设置较大的学习率。而批量大小较小时,需要设置较小的学习率,否则模型会不收敛。学习率通常要随着批量大小的增大而相应地增大。一个简单有效的方法是线性缩放规则(Linear Scaling Rule):当批量大小增加m倍时,学习率也增加m倍。线性缩放规则往往在批量大小比较小时适用,当批量大小非常大时,线性缩放会使得训练不稳定。
周期学习率调整
为使得梯度下降法能够逃离局部最小值或鞍点,一种经验性的方式是在训练过程中周期性地增大学习率。虽增大学习率可能短期内有损网络的收敛稳定性,但从长期来看有助于找到更好的局部最优解。
理由:当一个模型收敛一个平坦(Flat)的局部最小值时,其鲁棒性会更好,即微小的参数变动不会剧烈影响模型能力;而当模型收敛到一个尖锐(Sharp)的局部最小值时,其鲁棒性
也会比较差。具备良好泛化能力的模型通常应该是鲁棒的,因此理想的局部最小值应该是平坦的。周期性学习率调整可以使得梯度下降法在优化过程中跳出尖锐的局部极小值,虽然会短期内会损害优化过程,但最终会收敛到更加理想的局部极小值。(Sharpness-aware Minimization)
基于模型参数梯度二范数平方和自适应调整每轮学习率
Adagrad RMSprop AdaDelta 等
梯度估计修正
在随机(小批量)梯度下降法中,如果每次选取样本数量比较小,损失会呈现震荡的方式下降。也就是说,随机梯度下降方法中每次迭代的梯度估计和整个训练集上的最优梯度并不一致,具有一定的随机性。(即得到的梯度方向与全梯度的夹角余弦小于1)一种有效地缓解梯度估计随机性的方式是通过使用最近一段时间内的平均梯度来代替当前时刻的随机梯度来作为参数更新的方向,从而提高优化速度。
动量法
Δ
θ
t
=
ρ
Δ
θ
t
−
1
−
α
g
t
=
−
α
∑
τ
=
1
t
ρ
t
−
τ
g
τ
\Delta \theta_t=\rho \Delta \theta_{t-1}-\alpha \boldsymbol{g}_t=-\alpha \sum_{\tau=1}^t \rho^{t-\tau} \boldsymbol{g}_\tau
Δθt=ρΔθt−1−αgt=−α∑τ=1tρt−τgτ
一般而言,在迭代初期,梯度方向都比较一致,动量法会起到加速作用,可以更快地到达最优点。在迭代后期,梯度方向会不一致,在收敛值附近震荡,动量法会起到减速作用,增加稳定性。
Nesterov加速梯度
参考文章:On the importance of initialization and momentum in deep learning
相较于动量法,NAG更新方式为
v
t
+
1
=
μ
v
t
−
ε
∇
f
(
θ
t
+
μ
v
t
)
θ
t
+
1
=
θ
t
+
v
t
+
1
\begin{aligned} v_{t+1} & =\mu v_t-\varepsilon \nabla f\left(\theta_t+\mu v_t\right) \\ \theta_{t+1} & =\theta_t+v_{t+1}\end{aligned}
vt+1θt+1=μvt−ε∇f(θt+μvt)=θt+vt+1
梯度截断
数据预处理
一般而言,样本的原始特征中的每一维特征由于来源以及度量单位不同,其特征取值的分布范围往往差异很大。当我们计算不同样本之间的欧氏距离时,取值范围大的特征会起到主导作用。这样,对于基于相似度比较的机器学习方法(比如最近邻分类器),必须先对样本进行预处理,将各个维度的特征归一化到同一个取值区间,并且消除不同特征之间的相关性,才能获得比较理想的结果。
除了参数初始化之外,不同输入特征的取值范围差异比较大时,梯度下降法的效率也会受到影响。
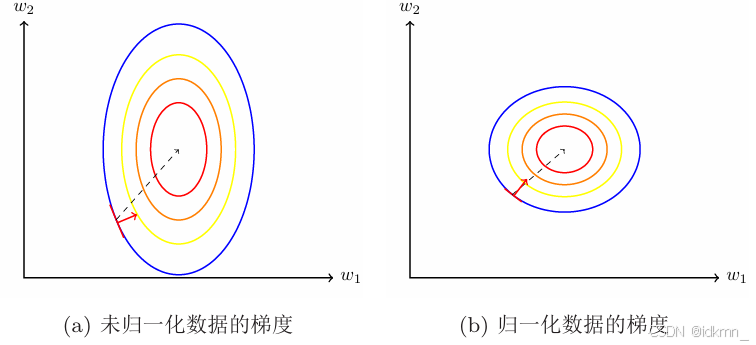
其中,白化是一种重要的预处理方法,用来降低输入数据特征之间的冗余性。输入数据经过白化处理后,特征之间相关性较低,并且所有特征具有相同的方差。
白化的主要实现方式之一是主成分分析:
超参数优化
常见的超参数包括:
- 网络结构,包括神经元之间的连接关系、层数、每层的神经元数量、激活函数类型等。
- 优化参数,包括优化方法、学习率、小批量的样本数量等。
- 正则化系数。


















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











