






我也来蹭一波热度,尝试本地部署deepseek r1 模型,手上只有一台12代i5的核显笔记本
升级到最新的显卡驱动
去英特尔官方网站下载最新的显卡驱驱动:
https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html
安装并重启
在 Intel GPU 上使用 IPEX-LLM 运行 Ollama
参照下面这个文档即可:
https://github.com/intel/ipex-llm/blob/main/docs/mddocs/Quickstart/ollama_quickstart.zh-CN.md
服务启动后是这个样子
安装 IPEX-LLM、建立文件夹、初始化
conda create -n llm-cpp python=3.11
conda activate llm-cpp
pip install --pre --upgrade ipex-llm[cpp]
init-llama-cpp.bat
#设置环境变量
set SYCL_CACHE_PERSISTENT=1
rem under most circumstances, the following environment variable may improve performance, but sometimes this may also cause performance degradation
set SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
初始化 Ollama
conda activate llm-cpp
init-ollama.bat
运行ollama
set OLLAMA_NUM_GPU=999
set no_proxy=localhost,127.0.0.1
set ZES_ENABLE_SYSMAN=1
set SYCL_CACHE_PERSISTENT=1
rem under most circumstances, the following environment variable may improve performance, but sometimes this may also cause performance degradation
set SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
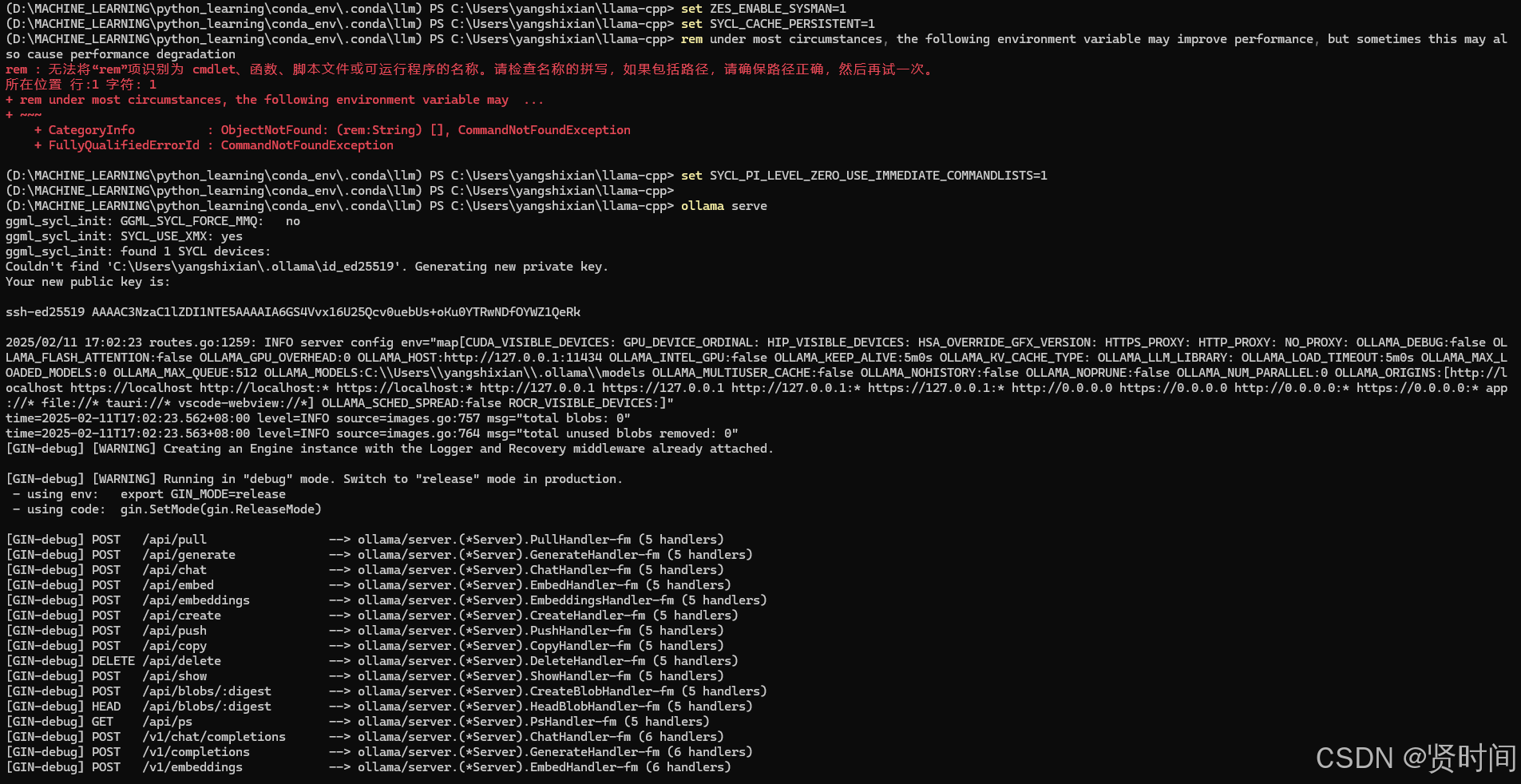
ollama serve
启动后如下:
拉取deepseek r1 模型
之前去ollama官网 即可,排名第一的就是:
此处需要新开个conda窗口,激活环境
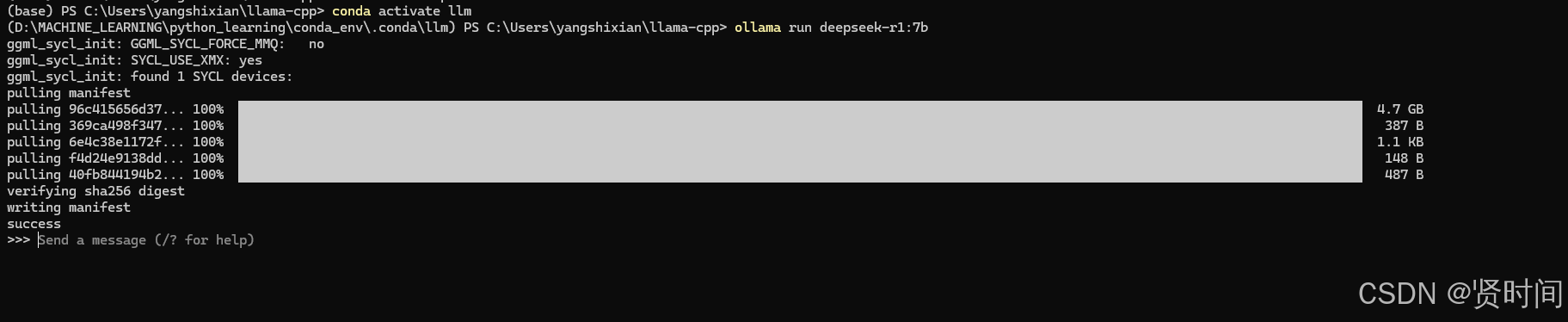
我们拉一个7.5b的试试
conda activate llm
ollama run deepseek-r1:7b
拉取完成后长这样
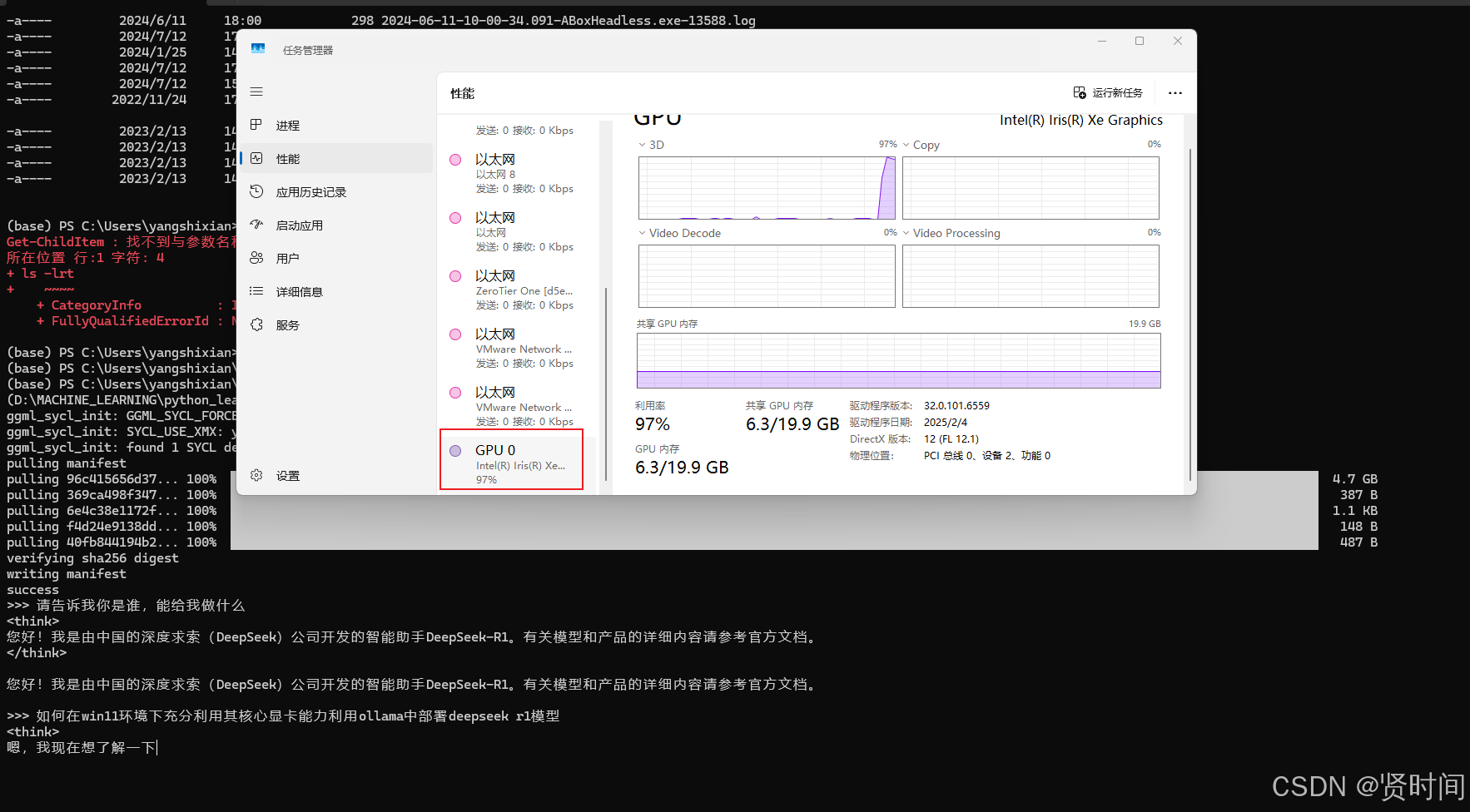
验证deepseek r1模型
直接对对话框中输入文字即可,有木有到GPU直接拉满了
参考资料
https://www.toutiao.com/article/7429939444603470348/?wid=1739259029486
https://github.com/intel/ipex-llm/blob/main/README.zh-CN.md


















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











