









| 相关文章 | 链接 |
| 知识点1-分布式与中间件 | https://blog.youkuaiyun.com/x526967803/article/details/109101719 |
| 知识点2-大数据与高并发 | https://blog.youkuaiyun.com/x526967803/article/details/114852680 |
| 知识点3-设计模式与实践 | https://blog.youkuaiyun.com/x526967803/article/details/114852718 |
| 知识点4-数据结构与算法 | https://blog.youkuaiyun.com/x526967803/article/details/109101968 |
目录
一、OOP五大原则SOLID
S.O.L.I.D是面向对象设计和编程(OOD&OOP)中几个重要编码原则(Programming Priciple)的首字母缩写。
| SRP | 单一责任原则 | |
| OCP | The Open Closed Principle | 开放封闭原则 |
| LSP | The Liskov Substitution Principle | 里氏替换原则 |
| DIP | The Dependency Inversion Principle | 依赖倒置原则 |
| ISP | The Interface Segregation Principle | 接口分离原则 |
单一责任原则
当需要修改某个类的时候原因有且只有一个(THERE SHOULD NEVER BE MORE THAN ONE REASON FOR A CLASS TO CHANGE)。换句话说就是让一个类只做一种类型责任,当这个类需要承当其他类型的责任的时候,就需要分解这个类。

开放封闭原则
开闭原则的意思是:对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。简言之,是为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类,后面的具体设计中我们会提到这点。

里氏替换原则
里氏代换原则是面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。LSP 是继承复用的基石,只有当派生类可以替换掉基类,且软件单位的功能不受到影响时,基类才能真正被复用,而派生类也能够在基类的基础上增加新的行为。里氏代换原则是对开闭原则的补充。实现开闭原则的关键步骤就是抽象化,而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
依赖倒置原则
-
高层模块不应该依赖于低层模块,二者都应该依赖于抽象
-
抽象不应该依赖于细节,细节应该依赖于抽象

接口分离原则
这个原则的意思是:使用多个隔离的接口,比使用单个接口要好。它还有另外一个意思是:降低类之间的耦合度。由此可见,其实设计模式就是从大型软件架构出发、便于升级和维护的软件设计思想,它强调降低依赖,降低耦合。

这几条原则是非常基础而且重要的面向对象设计原则。正是由于这些原则的基础性,理解、融汇贯通这些原则需要不少的经验和知识的积累。上述的图片很好的注释了这几条原则。
二、设计模式
设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。
设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了重用代码、让代码更容易被他人理解、保证代码可靠性。 毫无疑问,设计模式于己于他人于系统都是多赢的,设计模式使代码编制真正工程化,设计模式是软件工程的基石,如同大厦的一块块砖石一样。项目中合理地运用设计模式可以完美地解决很多问题,每种模式在现实中都有相应的原理来与之对应,每种模式都描述了一个在我们周围不断重复发生的问题,以及该问题的核心解决方案,这也是设计模式能被广泛应用的原因。
| 序号 | 模式 & 描述 | 包括 |
| 1 | 创建型模式这些设计模式提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象。这使得程序在判断针对某个给定实例需要创建哪些对象时更加灵活。 | 工厂模式(Factory Pattern)抽象工厂模式(Abstract Factory Pattern)单例模式(Singleton Pattern)建造者模式(Builder Pattern)原型模式(Prototype Pattern) |
| 2 | 结构型模式这些设计模式关注类和对象的组合。继承的概念被用来组合接口和定义组合对象获得新功能的方式。 | 适配器模式(Adapter Pattern)桥接模式(Bridge Pattern)过滤器模式(Filter、Criteria Pattern)组合模式(Composite Pattern)装饰器模式(Decorator Pattern)外观模式(Facade Pattern)享元模式(Flyweight Pattern)代理模式(Proxy Pattern) |
| 3 | 行为型模式这些设计模式特别关注对象之间的通信。 | 责任链模式(Chain of Responsibility Pattern)命令模式(Command Pattern)解释器模式(Interpreter Pattern)迭代器模式(Iterator Pattern)中介者模式(Mediator Pattern)备忘录模式(Memento Pattern)观察者模式(Observer Pattern)状态模式(State Pattern)空对象模式(Null Object Pattern)策略模式(Strategy Pattern)模板模式(Template Pattern)访问者模式(Visitor Pattern) |
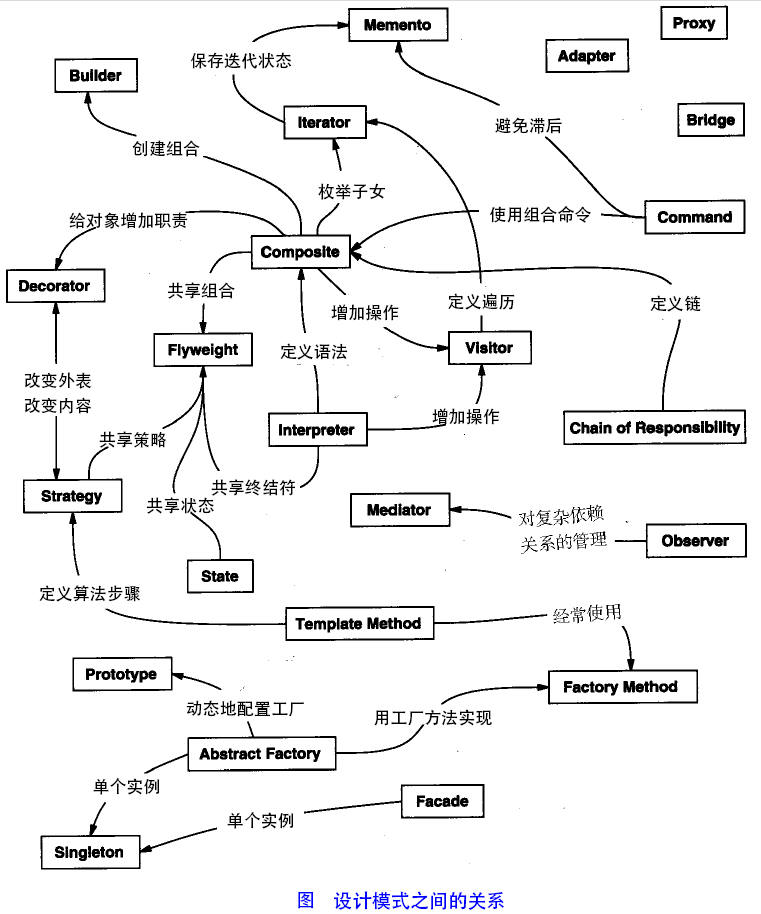
下面用一个图片来整体描述一下设计模式之间的关系:
三、代理模式
定义与举例
为其他对象提供一种代理以控制对这个对象的访问。
1,其他对象:目标对象,想要访问的对象,常被称为被委托对象或被代理对象。
2,提供一种代理:这里"一种"两个字比较重要,为什么不是提供一个呢?一种代表了某一类,即代理类和被
代理类必须实现同一接口,这个接口下的所有实现类都能被代理访问到,其实只是单纯的为了
实现代理访问功能,代理类不实现任何接口也能完成,不过针对于面向接口的编程,这种方式
更易于维护和扩展,代理类实现接口,不管目标对象怎么改或改成谁,代理类不需要任何修改
,而且任何目标对象能使用的地方都能用代理去替换。
3,通过代理访问目标对象:代理类需要持有目标对象的引用,这样用户可以通过代理类访问目标对象,实现
了用户与目标对象的解耦。
4,访问:访问二字说明代理对象的目的是访问被代理类,业务逻辑的具体执行与其无关,由被代理对象完成。
5,为什么要通过代理来访问:设计模式都是为了解决某一类的问题,可能目标对象不想让该用户访问或者是
该用户无法访问到目标对象,这样就需要一个第三者来建立他们的联系,如代理服务器情景,
被访问的服务器设置防火墙过滤掉某些地址的访问,这时用户就可以通过一个代理服务器来访
问目标,使得目标服务器不用对外暴露细节,用户也能访问到想访问的数据。
5,代理类功能增强:代理对象能直接访问到目标对象,这样它就能在调用目标对象的某个方法之前做一个预
处理,在调用方法之后进行一些结尾工作,这样就对目标对象的方法进行了增强。但是我们不
能说代理模式提供对象功能的增强,它的设计初衷是对代理对象施加控制,只是这种设计思路
能达到功能增强的目的。

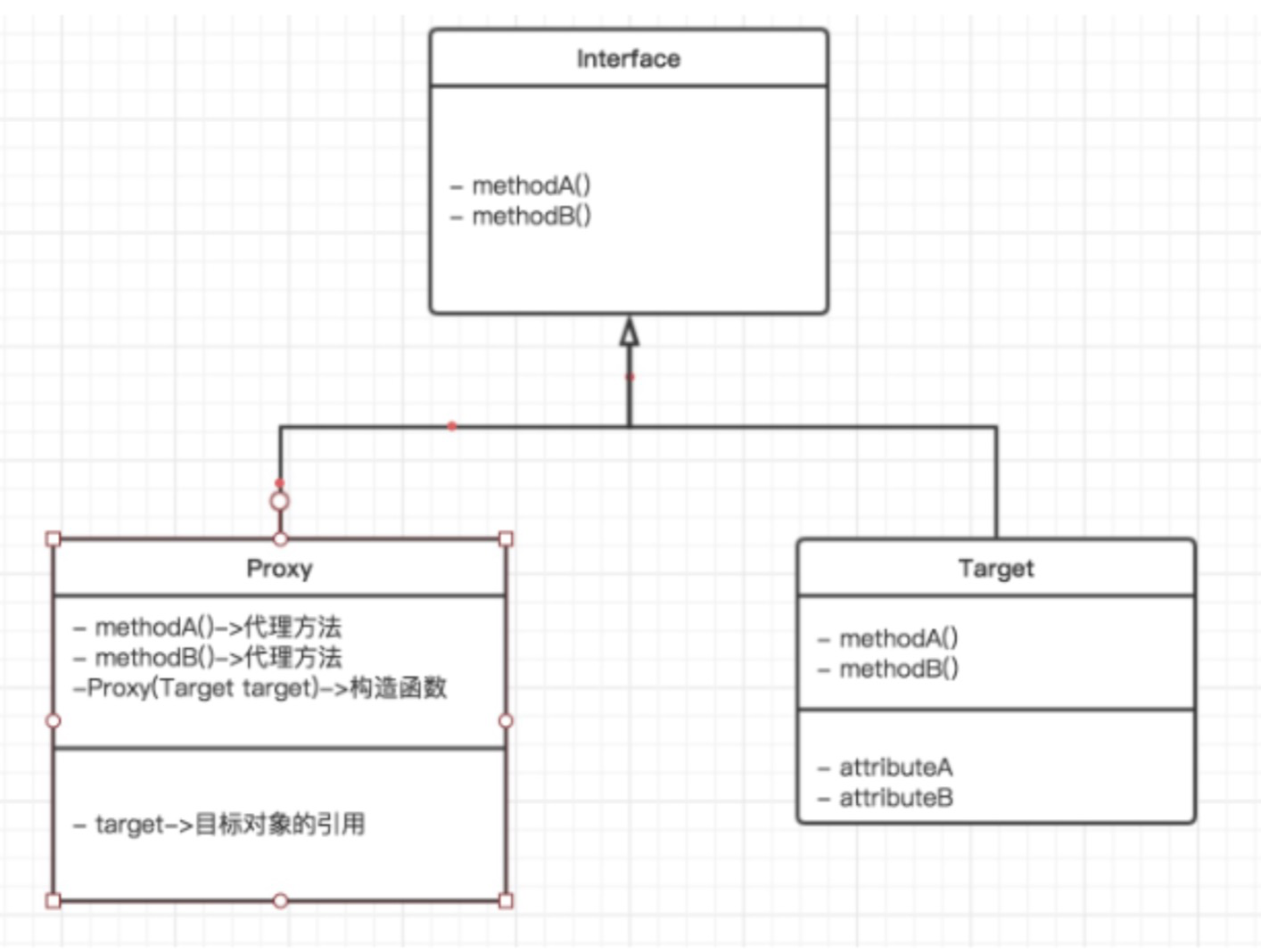
静态代理
静态代理模式就是如下图所示,构造三个类实现他们的关系。
静态代理由程序员创建或特定工具自动生成源代码,也就是在编译时就已经将接口,被代理类,代理类等确定下来。在程序运行之前,代理类的.class文件就已经生成。
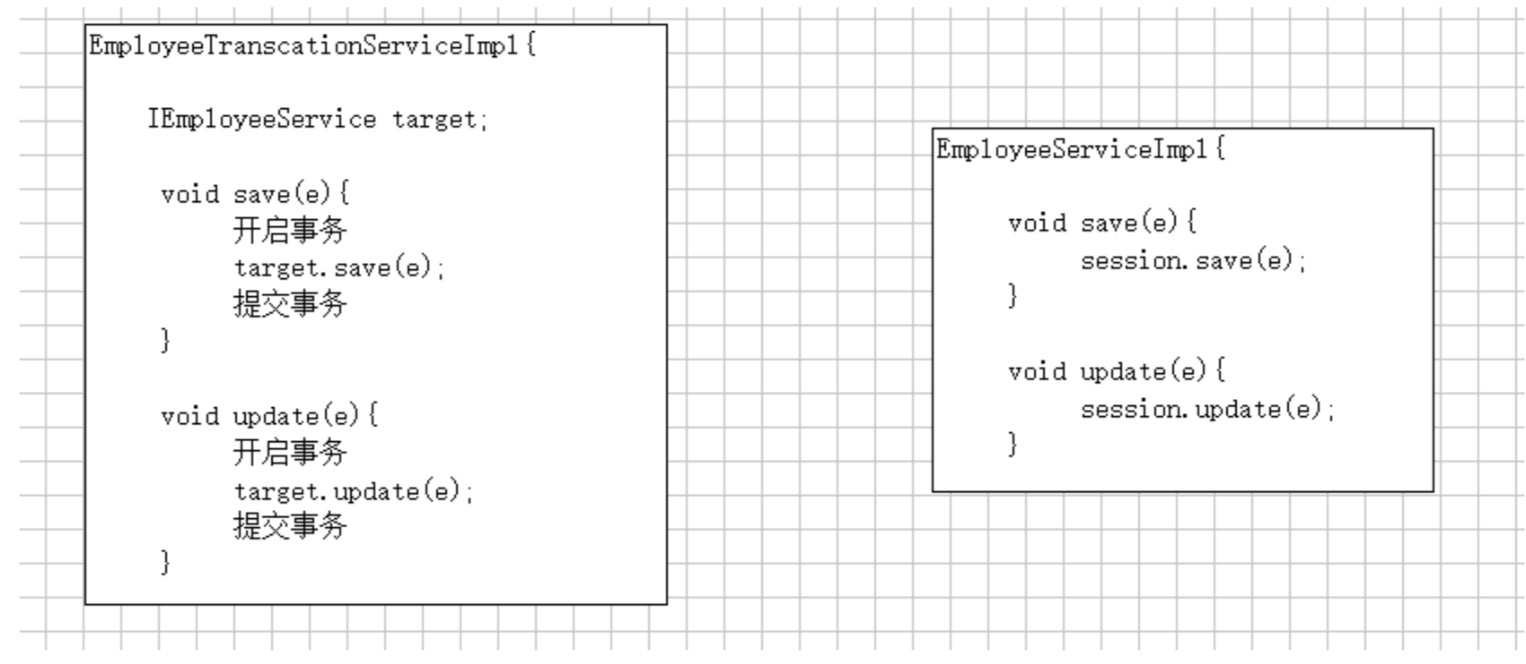
静态代理举例,事务要开在service层上
静态代理分析:静态代理确实处理了代码污染的问题;
问题:
1,重复的代码仍然分散在了各个方法中;
2,需要为每一个真实对象写一个代理对象;
动态代理
代理类在程序运行时创建的代理方式被成为动态代理。 我们上面静态代理的例子中,代理类(studentProxy)是自己定义好的,在程序运行之前就已经编译完成。然而动态代理,代理类并不是在Java代码中定义的,而是在运行时根据我们在Java代码中的“指示”动态生成的。相比于静态代理, 动态代理的优势在于可以很方便的对代理类的函数进行统一的处理,而不用修改每个代理类中的方法。
也就是说,有了动态代理,我们只需要编写一份开始事务,提交事务的代码,然后再指明哪些方法需要事务就可以了,程序会自动地帮我们生成代理类
JDK动态代理
基于java的反射,适用于有接口的类
CGLIB动态代理
基于ASM字节码操纵技术,适用于没有接口的类
四、面向切面编程(AOP)
基本思想
AOP 即 Aspect Oriental Program 面向切面编程
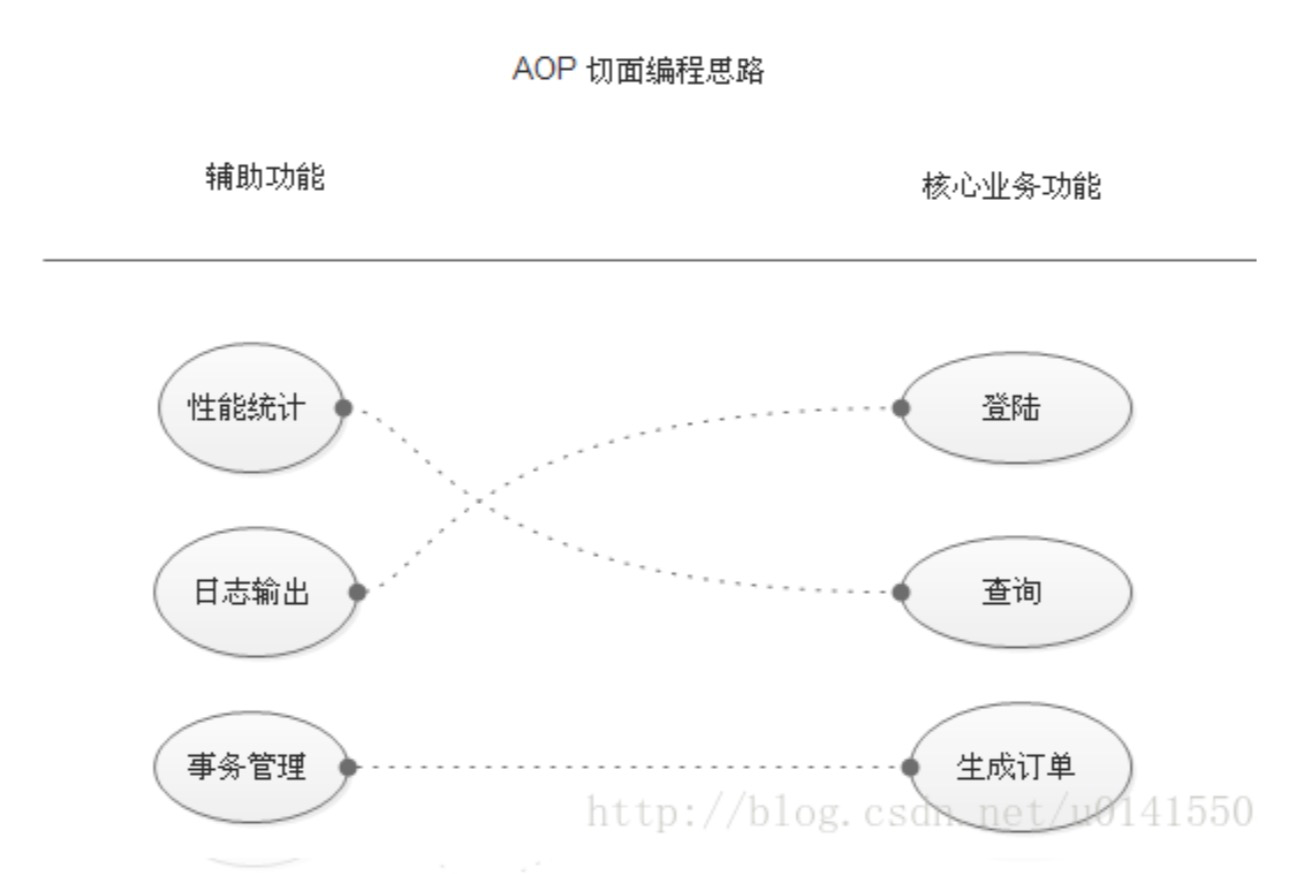
首先,在面向切面编程的思想里面,把功能分为核心业务功能,和周边功能。
所谓的核心业务,比如登陆,增加数据,删除数据都叫核心业务
所谓的周边功能,比如性能统计,日志,事务管理等等
周边功能在Spring的面向切面编程AOP思想里,即被定义为切面
在面向切面编程AOP的思想里面,核心业务功能和切面功能分别独立进行开发
然后把切面功能和核心业务功能 “编织” 在一起,这就叫AOP
登录验证
将登录验证的代码写成一个方法,做成切面,织入到相关对象中,这样,访问资源之前会先验证是否登录,相关的代码我们只需要编写一份
基于RBAC的权限管理
类似于登录验证,AOP还可以做权限验证,思路与上述相同
角色访问控制(RBAC)
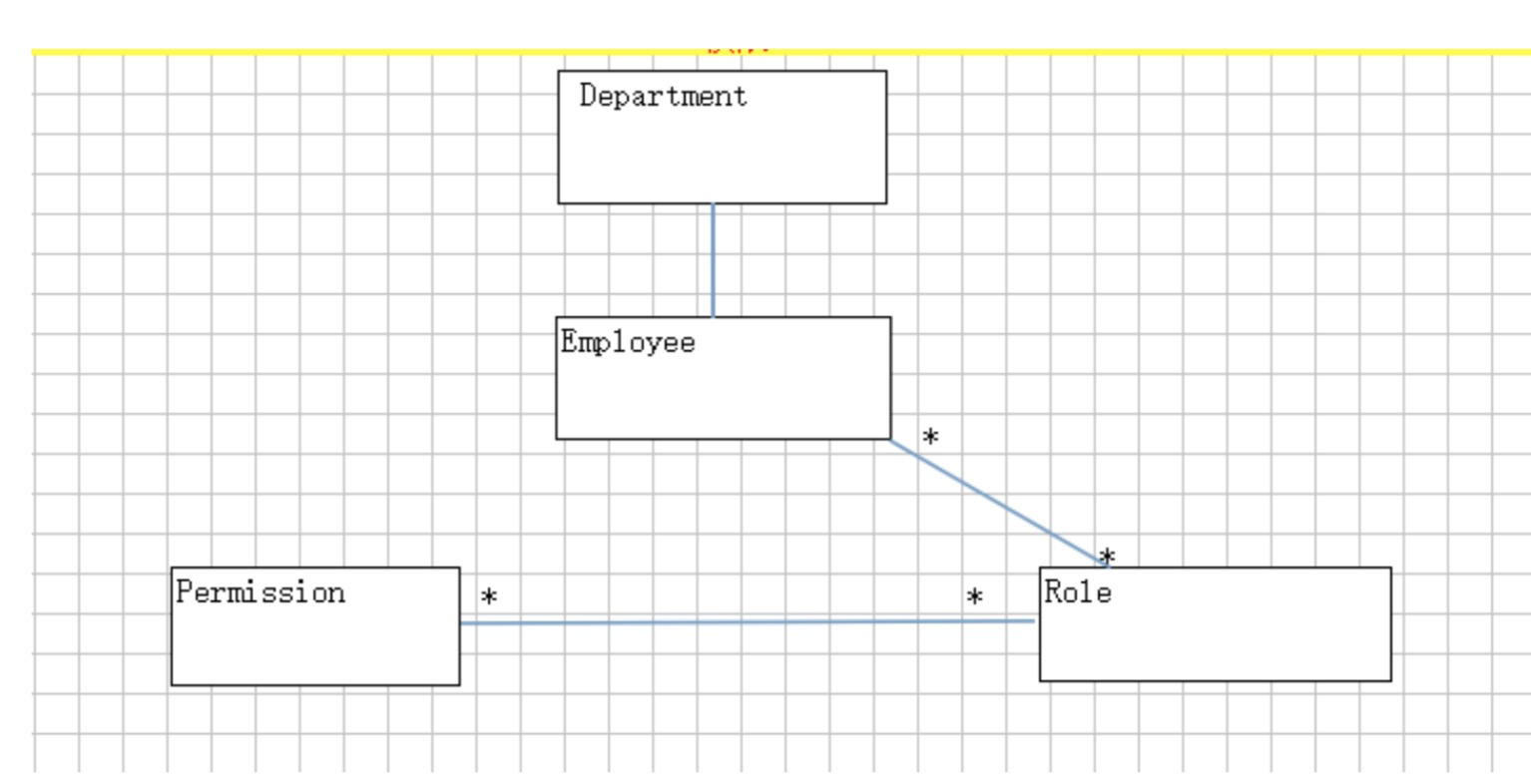
简单理解为:谁扮演什么角色, 被允许做什么操作用户对象:user: 当前操作用户角色对象:role:表示权限操作许可权的集合权限对象:permission: 资源操作许可权例子:张三(user) 下载(permission)一个高清无码的种子(资源), 需要VIP权限(role)张三--->普通用户--->授权---->VIP用户----->下载种子
引入了Role的概念,目的是为了隔离User(即动作主体,Subject)与Privilege(权限,表示对Resource的一个操作,即Operation+Resource)。
Role作为一个用户(User)与权限(Privilege)的代理层,解耦了权限和用户的关系,所有的授权应该给予Role而不是直接给User或 Group。
Privilege是权限颗粒,由Operation和Resource组成,表示对Resource的一个Operation。例如,对于新闻的删除操作。Role-Privilege是many-to-many的关系,这就是权限的核心。
两大特征是
1.由于角色/权限之间的变化比角色/用户关系之间的变化相对要慢得多,减小了授权管理的复杂性,降低管理开销。
2.灵活地支持企业的安全策略,并对企业的变化有很大的伸缩性。
执行流程分析
Permission
id expression name
1 com.zqx.PermissionController:execute 权限列表
2 com.zqx.PermissionController:edit 编辑权限
3 com.zqx.PermissionController:delete 删除权限
4 com.zqx.PermissionController:reload 重新加载权限
5 com.zqx.RoleController:execute 角色列表
6 com.zqx.RoleController:edit 编辑角色
7 com.zqx.RoleController:delete 删除角色
8 com.zqx.RoleController:save 添加角色
角色
id name List<Permission>1 角色管理员 5,6,7,82 权限管理员 1,2,3,4
员工
id name List<Role>1 小胖 12 小陈 23 班长 1,2
小胖这个用户登陆:1,检查用户名和密码;2,检查通过;
1,得到小胖这个用户的对应的所有的角色:R1
2,根据所有的角色,得到小胖所有的权限信息:P5,P6,P7,P8
3,把小胖所有的权限的expression放到一个set中;
4,把小胖这个对象和他的权限列表放到session中;
小胖操作系统:1,点角色管理;2,请求被权限检查拦截器拦截到了(PermissionCheckInterceptor.intercepte);
1,得到当次请求的Controller和方法;
2,判断,当前的这个方法是否是需要一个权限的;
3,如果当前方法不需要权限,直接放行;
4,如果当前方法需要权限,
1,把当前请求的method变成com.zqx.RoleController:execute一个表达式;
2,在当前用户的permissionset中去看是否有这个表达式;
3,如果有,放行;
4,如果没有,直接导向到没有权限那个页面;Copy
日志记录
当很多方法在开始、结束、抛异常时都需要记录,我们就可以采取上述AOP的思想来简化代码
日志记录最佳实践
1.关键业务操作:比如删除,更新等dml类型的操作的数据,尤其是要审计的日志一定要记录;推荐info级别:查询类的操作不推荐记录日志。
2.异常日志:如果是系统异常,比如网络不通,数据库连接失败等需要记录error日志。
3.业务规则异常:例如数据违反约束,这类推荐记录debug级别日志,不推荐info级别。这类信息正常情况下应该不需要关注,由程序返回值直接来实现,但是如果需要排查bug这部分信息还是很有价值。
1、 在程序开始运行应该以INFO记录程序开始运行的消息。
2、 在程序初始化过程中,如果影响程序主体正常运行错误出现,应该以FATAL记录出现错误的函数名、事件和错误号;如果只是一个不影响程序正常功能的模块出现错误,则应该以ERROR记录出现错误的函数名、模块名、事件和错误号。
3、 在程序初始化完成后,应该以INFO记录程序初始化完成的消息。
4、 在函数的入口,如果需要验证参数,则可以以DEBUG的形式输出参数的信息。如果重要参数不正确,则应该以ERROR输出。
5、 在调用比较成熟的API时,如果失败,则以ERROR记录,并且有错误号记下错误号。
6、 在调用没有经过严格测试的库时,即使返回成功,也要以DEBUG的形式记录下返回的结果。
7、 以捕获异常时,以ERROR记录下错误。
8、 在进行数据库操作时,以DEBUG的级别输出执行的SQL词句,对于取回的结果,最好是能打印出所有构造完成的对象的信息。
9、 在与其它程序进行通信时,以DEBUG记录下通信过程中的重要信息。
10、 对程序中的每个线程,它们的初始化完成和开始运行也要以INFO记录下来。
11、 对程序中需要检查运行性能的地方,以DEBUG记录下运行耗时。
12、 程序正常结束时,和初始化的记录方式相同,对各个模块的卸载采用和加载是一样的处理方式。当程序都卸载完成后以INFO记录程序退出的消息。
你应在适当级别上进行log
如果你遵循了上述第一点的做法,接下来你要对你程序中每一个log语句使用不同的log级别。其中最困难的一个任务是找出这个log应该是什么级别
以下是我的一些建议:
-
TRACE level: 如果使用在生产环境中,这是一个代码异味(code smell)。它可以用于开发过程中追踪bug,但不要提交到你的版本控制系统
-
DEBUG level: 把一切东西都记录在这里。这在debug过程中最常用到。我主张在进入生产阶段前减少debug语句的数量,只留下最有意义的部分,在调试(troubleshooting)的时候激活。
-
INFO level: 把用户行为(user-driven)和系统的特定行为(例如计划任务…)
-
NOTICE level: 这是生产环境中使用的级别。把一切不认为是错误的,可以记录的事件都log起来
-
WARN level: 记录在这个级别的事件都有可能成为一个error。例如,一次调用数据库使用的时间超过了预设时间,或者内存缓存即将到达容量上限。这可以让你适当地发出警报,或者在调试时更好地理解系统在failure之前做了些什么
-
ERROR level: 把每一个错误条件都记录在这。例如API调用返回了错误,或是内部错误条件
-
FATAL level: 末日来了。它极少被用到,在实际程序中也不应该出现多少。在这个级别上进行log意味着程序要结束了。例如一个网络守护进程无法bind到socket上,那么它唯一能做的就只有log到这里,然后退出运行。
记住,在你的程序中,默认的运行级别是高度可变的。例如我通常用INFO运行我的服务端代码,但是我的桌面程序用的是DEBUG。这是因为你很难在一台你没有接入权限的机器上进行调试,但你在做用户服务时,比起教他们怎么修改log level再把生成的log发给你,我的做法可以让你轻松得多。当然你可以有其他的做法:)
4. 你应该写有意义的log
这可能是最重要的建议了。没有什么比你深刻理解程序内部,却写出含糊的log更糟了。
在你写日志信息之前,总要提醒自己,有突发事件的时候,你唯一拥有的只有来自log文件,你必须从中明白发生了什么。这可能就是被开除和升职之间的微妙的差距。
当开发者写log的时候,它(log语句)是直接写在代码环境中的,在各种条件中我们应该写入基于当前环境的信息。不幸的是,在log文件中并没有这些环境,这可能导致这些信息无法被理解。
解决这个情况(在写warn和error level时尤为重要)的一个方法是,添加辅助信息到log信息中,如果做不到,那么改为把这个操作的作用写下。
还有,不要让一个log信息的内容基于上一个。这是因为前面的信息可能由于(与当前信息)处于不同的类别或者level而没被写入。更坏的情况是,它因多线程或异步操作,在另一个地方(或是以另一方式)出现。
日志信息应该用英语
这个建议可能有点奇怪,尤其是对法国佬(French guy)来说。我还是认为英语远比法语更简炼,更适应技术语言。如果一个信息里面包含超过50%的英语单词,你有什么理由去用法语写log呢
把英法之争丢一边,下面是这个建议背后的原因:
-
英语意味着你的log是用ASCII编码的。这非常重要,因为你不会真正知道log信息会发生什么,或是它被归档前经过何种软件层和介质。如果你的信息里面使用了特殊字符集,乃至UTF-8,它可能并不会被正确地显示(render),更糟的是,它可能在传输过程中被损坏,变得不可读。不过这还有个问题,log用户输入时,可能有各种字符集或者编码。
-
如果你的程序被大多数人使用,而你又没有足够的资源做国际化,英语会成为你的不二之选。如果你有国际化,那么让界面与终端用户更亲近(closer)(这通常不会是你的log)
-
如果你国际化了你的log(例如所有的warning和error level信息),给他们一个特定的有意义的错误码。这样,用户做与语言无关的搜索,找到相关信息。这种良好的模式已经在虚拟内存(VMS)操作系统中应用了很久,而我必须承认它非常有用。如果你曾经设计过这种模式,你还可以试试这种模式: APP-S-CODE 或者 APP-S-SUB-CODE,它们分别代表: APP: 应用程序的3字缩写 S: 严重程度的1字缩写(例如D代表debug,I代表info) SUB: 这个code所从属的应用程序的子部分 CODE: 一个数字代号,指定这个问题中的错误
你应该给log带上上下文
没有什么比这样的log信息更糟的了
Transaction failed
Copy
或是
User operation succeeds
Copy
又或是API异常时:
java.lang.IndexOutOfBoundsException
Copy
没有相应的上下文,这些信息不过是噪音,它们不会对调试过程中有意义的数值或是空间起作用(add value and consume space)。
带上上下文的信息要有价值得多,例如:
Transaction 234632 failed: cc number checksum incorrect
Copy
或是
User 54543 successfully registered e-mail<a href="mailto:user@domain.com">user@domain.com</a>
Copy
又或是
IndexOutOfBoundsException: index 12 is greater than collection size 10
Copy
日志不宜太多或太少
这听着貌似很愚蠢。log的数量是有一个合适的平衡的。
太多的log会使从中获得有价值的东西变得困难。当人工地浏览这种十分混乱的log,尝试调试产品在早上3点的一个问题可不是一个好事。
太少的log,你可能无法调试问题: 调试就像在拼一个困难的拼图,你需要得到足够的拼块。
不幸的是,这没有魔法般的规则去知道应该log些什么。所以需要严格地遵从第一第二点,程序可以变得很灵活,轻松地增减log的长度(verbosity)。
解决这个问题的一个方法是,在开发过程中尽可能多地进行log(不要被加入用于程序调试的log所迷惑)。当应用程序进入生产过程时,对生成的log进行一次分析,根据所发现的问题增减log语句。尤其是在调试时,在你需要的部分,你可以有更多的上下文或logging,确保在下一个版本中加入这些语句(可以的话,同时解决它来让这个问题在记忆中保持新鲜)。当然,这需要运维人员和开发者之间大量的交流。
这是一个复杂的任务,但是我推荐你重构logging语句,如你重构代码一样多。这样可以在产品的log和它的log语句的修改中有一个紧密的反馈循环。如果你的组织有一个连续的交付进程的话,它会十分有效,正如持续的重构。
Logging语句是与代码注释同级的代码元数据。保持logging语句与代码相同步是很重要的。没什么比调试时获得与所运行的代码毫无关系的信息更糟了。
你应该考虑阅读者
为什么要对应用程序做log
唯一的答案是,在某一天会有人去读它(或是它的意义)。更重要的是,猜猜谁会读它,这是很有趣的事。对于不同的”谁”,你将要写下的log信息的内容,上下文,类别和level会大不同。
这些”谁”包括:
-
一个尝试自己解决问题的终端用户(想象一个客户端或桌面程序)
-
一个在调试产品问题的系统管理员或者运维工程师
-
一个在开发中debug,或者在解决产品问题的开发者
开发者了解程序内部,所以给他的log信息可以比给终端用户的复杂得多。为你的目标阅读者调整你的表达方式,乃至为此加入额外的类别(dedicate separate catagories)。
你不应该只为调试而log
正如log会有不同的阅读者,它也有不同的使用理由。即便调试是最显而易见的阅读log的目的,你同样可以有效地把log用在:
-
审查: 有时商业上会有需求。这可以获取与管理或者合法用户的有意义的事件。通常会有一些语句描述这个系统中的用户在做些什么(例如谁登录了,谁在编辑……)
-
建档: log是打上了时间戳的(有时是微妙级的),可以成为一个为程序各部分建档的好工具。例如记录一个操作的开始和结束,你可以自动化(通过解析log)或是在调试中,进行性能度量,而不需要把这些度量加到程序中。
-
统计: 如果你每次对一个特定事件(例如特定的错误或事件)进行log,你可以对运行中的程序(或用户行为)进行有趣的统计。这可以添加(hook)到一个警报系统中去连续地发现大量error。
总结
我希望这可以帮助你生成更多有用的log。如果我忘记了一些必须的(对你而言)建议,请谅解。对了,如果你看了这篇博客之后并不能更好地进行log,我并不负责 :)
事务处理
上面已经说过了
统一异常处理
在Web接口开发中,我们希望我们的接口函数运行过程中,即使抛出了异常,也能给客户端相应数据,告诉客户请求出错或者服务器出错,而不是直接宕机不去相应客户,并且我们还希望,我们抛异常之后相应数据格式要统一,此时便可以使用AOP思想做统一的异常处理
首先看我们添加一个girl的这段代码
@PostMapping(value = "/girl")public Girl addGirl(@Valid Girl girl, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
logger.error(bindingResult.getFieldError().getDefaultMessage());
return null;
}
return girlRepository.save(girl);}Copy
有错误时返回null,而成功是返回girl。这边的问题是格式不统一。
如果我们定义"code","msg",和"data"是server返回给client端的三个field,这样client端因为统一的格式,能够更容易的处理之后的操作。
{
"code": -1,
"msg": "some error message here",
"data": null
}{
"code": 0
"msg": "success",
"data": {
"id": 20,
"cupSize": "B",
"age": 25
}}Copy
我们先来创建一个Result对象并包含这三个field
public class Result<T> {
private int code;
private String msg;
private T data;
public int getCode() {
return code;
}
public String getMsg() {
return msg;
}
public T getData() {
return data;
}
public void setCode(int code) {
this.code = code;
}
public void setMsg(String msg) {
this.msg = msg;
}
public void setData(T data) {
this.data = data;
}}Copy
然后重新refactor一下这段添加girl的代码
@PostMapping(value = "/girl")public Result addGirl(@Valid Girl girl, BindingResult bindingResult) {
Result result = new Result();
if (bindingResult.hasErrors()) {
result.setCode(-1);
result.setMsg(bindingResult.getFieldError().getDefaultMessage());
return result;
}
result.setCode(0);
result.setMsg("success");
result.setData(girlRepository.save(girl));
return result;}Copy
我们看到每次都是做很多的set操作还是很繁琐,那就进一步refactor一下。
建一个ResultUtil类
import com.zfu.domain.Result;public class ResultUtil {
public static Result generateSuccessResult(final Object object) {
Result result = new Result();
result.setCode(0);
result.setMsg("success");
result.setData(object);
return result;
}
public static Result generateErrorResult(final int errorCode, final String errorMsg) {
Result result = new Result();
result.setCode(errorCode);
result.setMsg(errorMsg);
return result;
}}Copy
有了这个类的帮助,我们再进一步改进一下添加一个girl这段代码
@PostMapping(value = "/girl")public Result addGirl(@Valid Girl girl, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
return ResultUtil.generateErrorResult(-1, bindingResult.getFieldError().getDefaultMessage());
}
return ResultUtil.generateSuccessResult(girlRepository.save(girl));}Copy
这时我们有一个需求,将女生按年龄分类。假如她的年龄小于等于12,返回你还在读小学吧;假如他的年龄小于等于17,返回你还在读中学吧。
为了满足这个需求,我们可以先在service类里写一个方法
/**
* if age <= 12,
* 返回你还在读小学吧
* else if age <= 17,
* 返回你还在读中学吧
* else
* do something...
*/
public void classifyGirlsByAge(int id) throws Exception {
Girl girl = girlRepository.findOne(id);
int age = girl.getAge();
if (age <= 12) {
throw new Exception("你还在读小学吧");
} else if (age <= 17) {
throw new Exception("你还在读中学吧");
}
// do something..
}Copy
然后在controller类里调用这个service的方法,来响应这个请求
@GetMapping(value = "girl/age/{id}")public void classifyGirlsByAge(@PathVariable("id") int id) throws Exception {
girlService.classifyGirlsByAge(id);}Copy
然后在controller这一层throw一个exception,会导致server挂掉。那我们怎么handle这个情况呢。
先创建一个ResultEnum来枚举Exception类型的信息
public enum ResultEnum {
UNKNOWN_ERROR(-1, "unknown error"),
SUCCESS(0, "success"),
PRIMARY_SCHOOL(100, "你还在上小学吧"),
MIDDLE_SCHOOL(101, "你还在上中学吧");
private int code;
private String msg;
ResultEnum(int code, String msg) {
this.code = code;
this.msg = msg;
}
public int getCode() {
return code;
}
public String getMsg() {
return msg;
}}Copy
再写一个ExceptionHandler,带上@ControllerAdvice这个Annotation来handle那些runtime exception。
import com.zfu.domain.Result;import com.zfu.domain.ResultEnum;import com.zfu.exception.GirlException;import com.zfu.utils.ResultUtil;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.web.bind.annotation.ControllerAdvice;import org.springframework.web.bind.annotation.ExceptionHandler;import org.springframework.web.bind.annotation.ResponseBody;@ControllerAdvicepublic class GirlExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(GirlExceptionHandler.class);
@ExceptionHandler(value = Exception.class)
@ResponseBody
public Result handle(Exception e) {
if (e instanceof GirlException) {
GirlException girlException = (GirlException) e;
return ResultUtil.generateErrorResult(girlException.getCode(), girlException.getMsg());
}
logger.error(e.getMessage());
return ResultUtil.generateErrorResult(ResultEnum.UNKNOWN_ERROR.getCode(), ResultEnum.UNKNOWN_ERROR.getMsg());
}}Copy
五、工厂模式
简单工厂
简单工厂模式不能说是一个设计模式,说它是一种编程习惯可能更恰当些。因为它至少不是Gof23种设计模式之一。但它在实际的编程中经常被用到,而且思想也非常简单,可以说是工厂方法模式的一个引导,所以我想有必要把它作为第一个讲一下。
模式动机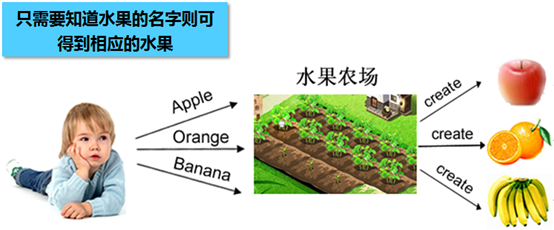
考虑一个简单的软件应用场景,一个软件系统可以提供多个外观不同的按钮(如圆形按钮、矩形按钮、菱形按钮等),这些按钮都源自同一个基类,不过在继承基类后不同的子类修改了部分属性从而使得它们可以呈现不同的外观,如果我们希望在使用这些按钮时,不需要知道这些具体按钮类的名字,只需要知道表示该按钮类的一个参数,并提供一个调用方便的方法,把该参数传入方法即可返回一个相应的按钮对象,此时,就可以使用简单工厂模式。
模式定义
简单工厂模式(Simple Factory Pattern):又称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。在简单工厂模式中,可以根据参数的不同返回不同类的实例。简单工厂模式专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。
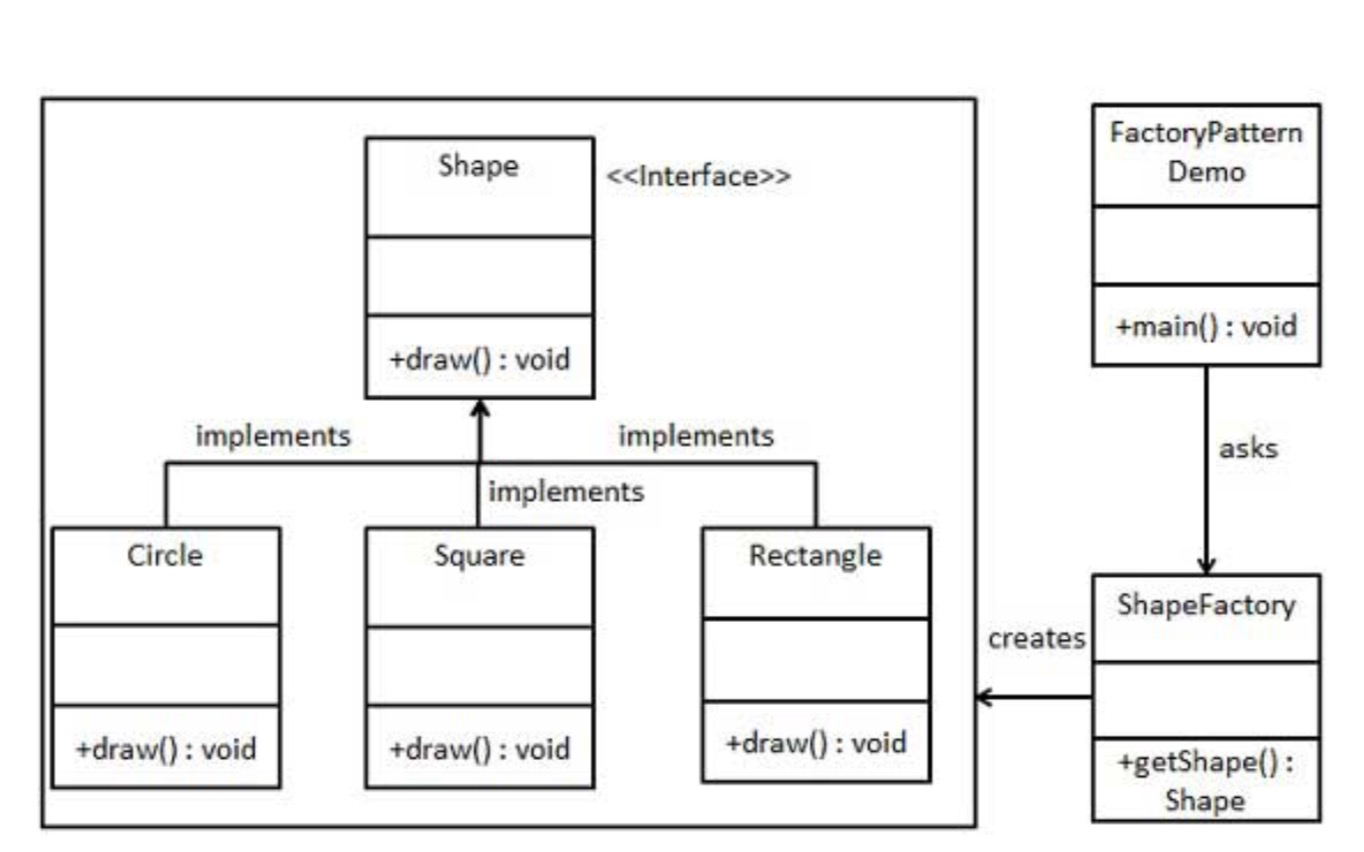
步骤 1
创建一个接口:
Shape.java
public interface Shape {
void draw();}
步骤 2
创建实现接口的实体类。
Rectangle.java
public class Rectangle implements Shape {
@Override
public void draw() {
System.out.println("Inside Rectangle::draw() method.");
}}
Square.java
public class Square implements Shape {
@Override
public void draw() {
System.out.println("Inside Square::draw() method.");
}}
Circle.java
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Inside Circle::draw() method.");
}}
步骤 3
创建一个工厂,生成基于给定信息的实体类的对象。
ShapeFactory.java
public class ShapeFactory {
//使用 getShape 方法获取形状类型的对象
public Shape getShape(String shapeType){
if(shapeType == null){
return null;
}
if(shapeType.equalsIgnoreCase("CIRCLE")){
return new Circle();
} else if(shapeType.equalsIgnoreCase("RECTANGLE")){
return new Rectangle();
} else if(shapeType.equalsIgnoreCase("SQUARE")){
return new Square();
}
return null;
}}
步骤 4
使用该工厂,通过传递类型信息来获取实体类的对象。
FactoryPatternDemo.java
public class FactoryPatternDemo {
public static void main(String[] args) {
ShapeFactory shapeFactory = new ShapeFactory();
//获取 Circle 的对象,并调用它的 draw 方法
Shape shape1 = shapeFactory.getShape("CIRCLE");
//调用 Circle 的 draw 方法
shape1.draw();
//获取 Rectangle 的对象,并调用它的 draw 方法
Shape shape2 = shapeFactory.getShape("RECTANGLE");
//调用 Rectangle 的 draw 方法
shape2.draw();
//获取 Square 的对象,并调用它的 draw 方法
Shape shape3 = shapeFactory.getShape("SQUARE");
//调用 Square 的 draw 方法
shape3.draw();
}}Copy
工厂方法
抽象工厂
六、控制反转IOC
在传统的应用开发过程中,当我们需要一个A对象的时候,需要我们自己去new一个A对象,并且如果这个A对象在创建过程中还依赖了B对象,我们还得自己去new这个B对象,这样就导致了newA对象的程序员还必须得知道B对象的存在,增大了类之间的耦合性,违反了依赖导致原则,不利于后续的拓展
并且在传统的应用开发过程中,我们即使使用到了接口,但还是需要自己去new接口的实现类,因此并没有做到真正的解耦,并没有做到真正的面向接口编程
IoC(Inversion of Control,控制反转
思想就是利用工厂模式,设置一个对象的容器,将对象的创建,依赖的管理,生命周期的管理都交给容器来完成,当我们需要一个对象A的时候,只需要使用类似于 A a = factory.get("A")的方式,从容器中拿A对象就可以了,至于A对象在创建过程中还需要什么对象我们完全不用去考虑
使用接口的时候,我们只需要将接口的实现类放入IOC容器中,然后从容器中拿接口的实现就可以了,可以实现真正的解耦,真正的面向接口编程。
七、观察者模式
定义:当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知它的依赖对象。观察者模式属于行为型模式。
意图:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
主要解决:一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
何时使用:一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
/**
* 被观察者,也就是微信公众号服务
* 实现了Observerable接口,对Observerable接口的三个方法进行了具体实现
* @author jstao
*
*/public class WechatServer implements Observerable {
//注意到这个List集合的泛型参数为Observer接口,设计原则:面向接口编程而不是面向实现编程
private List<Observer> list;
private String message;
public WechatServer() {
list = new ArrayList<Observer>();
}
@Override
public void registerObserver(Observer o) {
list.add(o);
}
@Override
public void removeObserver(Observer o) {
if(!list.isEmpty())
list.remove(o);
}
//遍历
@Override
public void notifyObserver() {
for(int i = 0; i < list.size(); i++) {
Observer oserver = list.get(i);
oserver.update(message);
}
}
public void setInfomation(String s) {
this.message = s;
System.out.println("微信服务更新消息: " + s);
//消息更新,通知所有观察者
notifyObserver();
}}Copy
八、Zookeeper
ZK简述
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架, 它负责存储和管理大家都关心的数据, 然后接受观察者的注册, 一旦这些数据的状态发生变化, Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出 相应 的反 应 , 从而 实现集群中类似Master/Slave管理模式
存储结构
zookeeper中的数据是按照“树”结构进行存储的。而且znode节点还分为4中不同的类型。
znode
根据本小结第一部分的描述,很显然zookeeper集群自身维护了一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为“znode”。如下如所示:
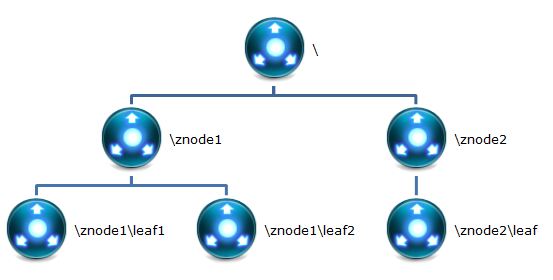
-
每一个znode默认能够存储1MB的数据(对于记录状态性质的数据来说,够了)
-
可以使用zkCli命令,登录到zookeeper上,并通过ls、create、delete、sync等命令操作这些znode节点
-
znode除了名称、数据以外,还有一套属性:zxid。这套zid与时间戳对应,记录zid不同的状态(后续我们将用到)
那么每个znode结构又是什么样的呢?如下图所示:

此外,znode还有操作权限。如果我们把以上几类属性细化,又可以得到以下属性的细节:
-
czxid:创建节点的事务的zxid
-
mzxid:对znode最近修改的zxid
-
ctime:以距离时间原点(epoch)的毫秒数表示的znode创建时间
-
mtime:以距离时间原点(epoch)的毫秒数表示的znode最近修改时间
-
version:znode数据的修改次数
-
cversion:znode子节点修改次数
-
aversion:znode的ACL修改次数
-
ephemeralOwner:如果znode是临时节点,则指示节点所有者的会话ID;如果不是临时节点,则为零。
-
dataLength:znode数据长度。
-
numChildren:znode子节点个数。
znode中的存在类型
我们知道了zookeeper内部维护了一套数据结构:由znode构成的集合,znode的集合又是一个树形结构。每一个znode又有很多属性进行描述。并且znode的存在性还分为四类,如下如所示:
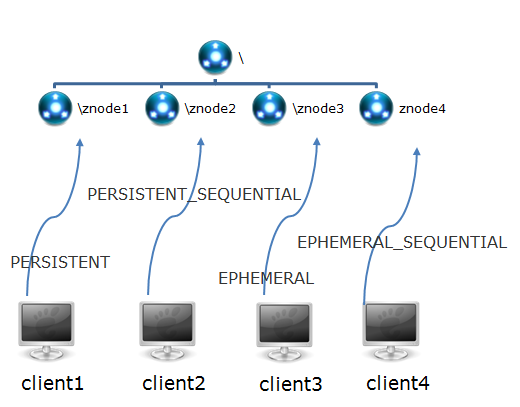
znode是由客户端创建的,它和创建它的客户端的内在联系,决定了它的存在性:
-
PERSISTENT-持久化节点:创建这个节点的客户端在与zookeeper服务的连接断开后,这个节点也不会被删除(除非您使用API强制删除)。
-
PERSISTENT_SEQUENTIAL-持久化顺序编号节点:当客户端请求创建这个节点A后,zookeeper会根据parent-znode的zxid状态,为这个A节点编写一个全目录唯一的编号(这个编号只会一直增长)。当客户端与zookeeper服务的连接断开后,这个节点也不会被删除。
-
EPHEMERAL-临时目录节点:创建这个节点的客户端在与zookeeper服务的连接断开后,这个节点(还有涉及到的子节点)就会被删除。
-
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点:当客户端请求创建这个节点A后,zookeeper会根据parent-znode的zxid状态,为这个A节点编写一个全目录唯一的编号(这个编号只会一直增长)。当创建这个节点的客户端与zookeeper服务的连接断开后,这个节点被删除。
-
另外,无论是EPHEMERAL还是EPHEMERAL_SEQUENTIAL节点类型,在zookeeper的client异常终止后,节点也会被删除。
应用场景
统一命名服务
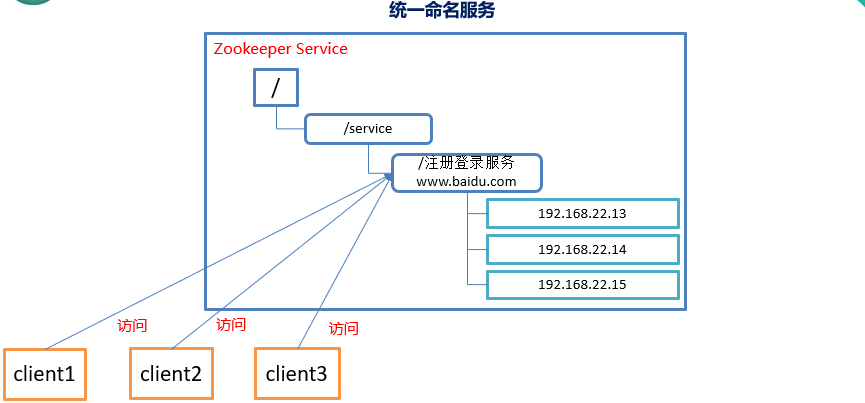
负载均衡

统一配置管理
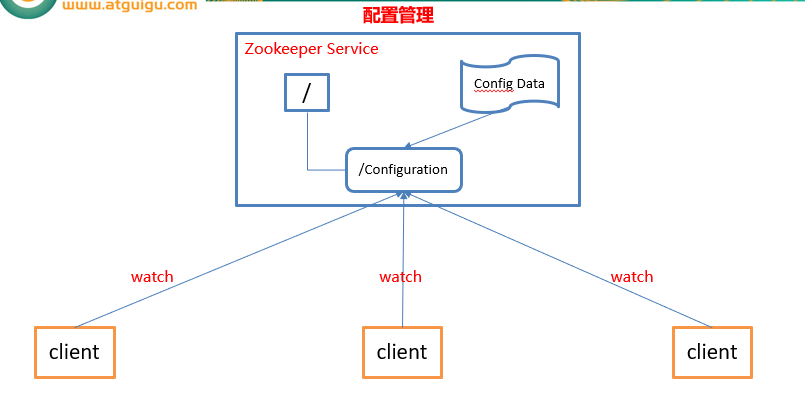
集群管理
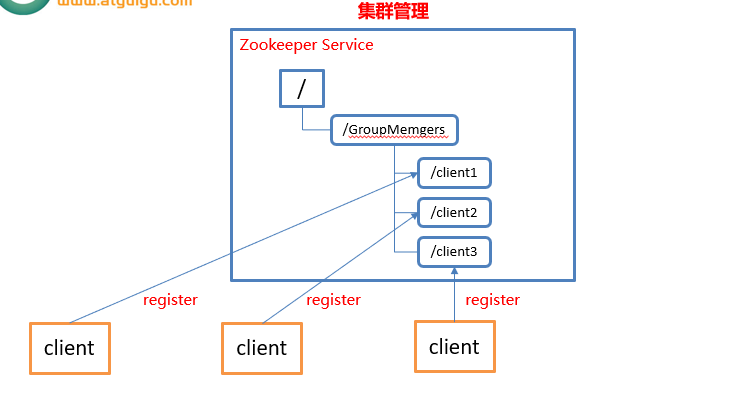
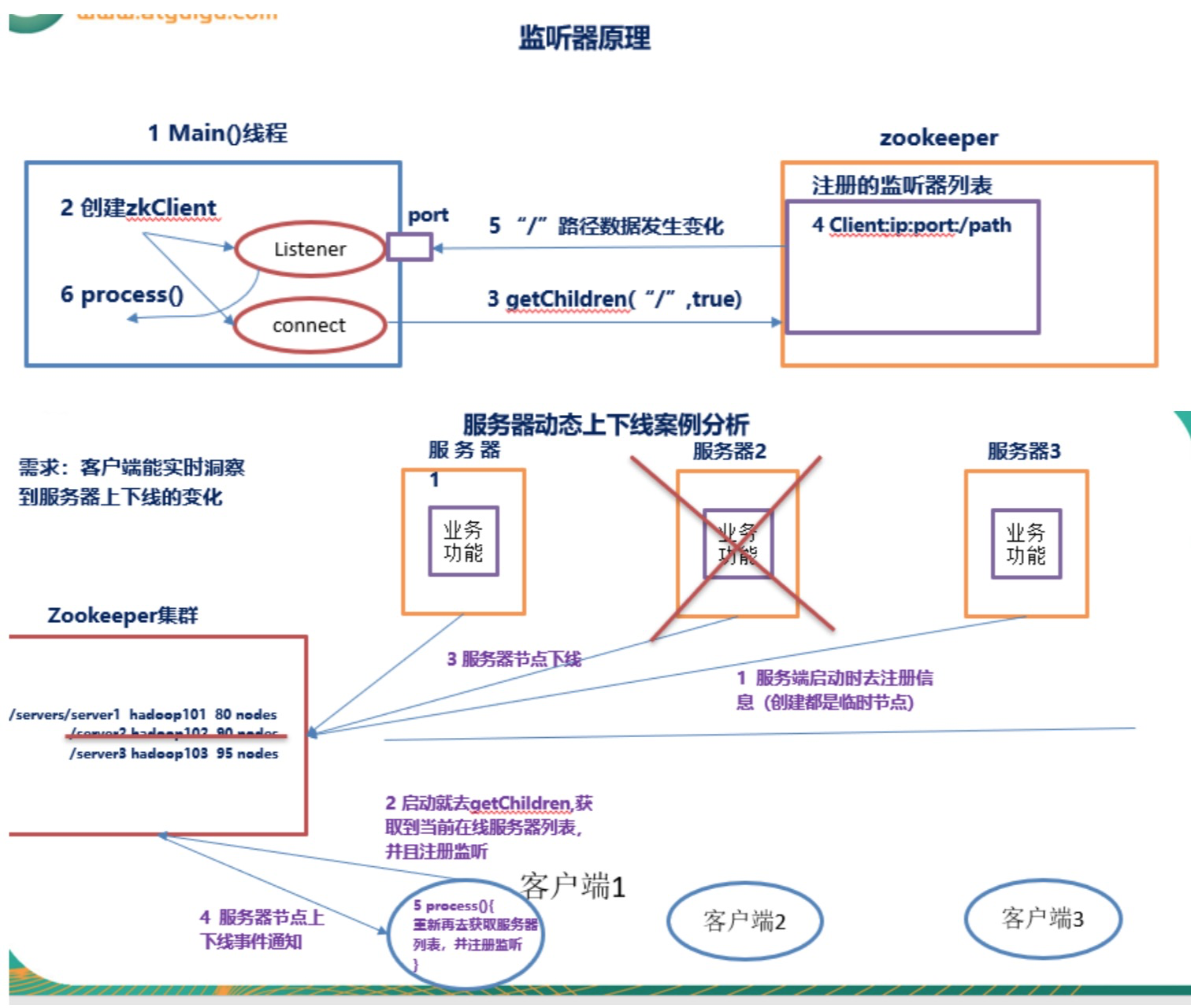
服务器动态上下线
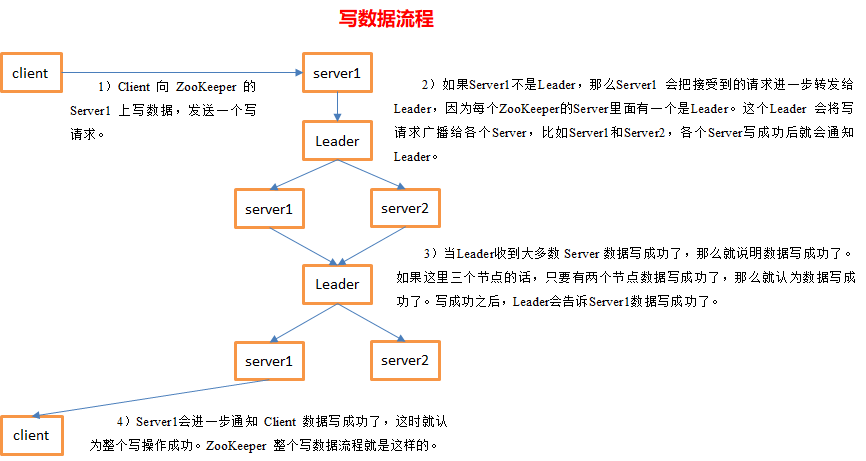
写数据流程
Zookeeper提供的是 弱一致性,CAP限制,读的的数据可能不是最新的,如果想读到最新的数据,应该手动调用sync方法从Leader同步数据
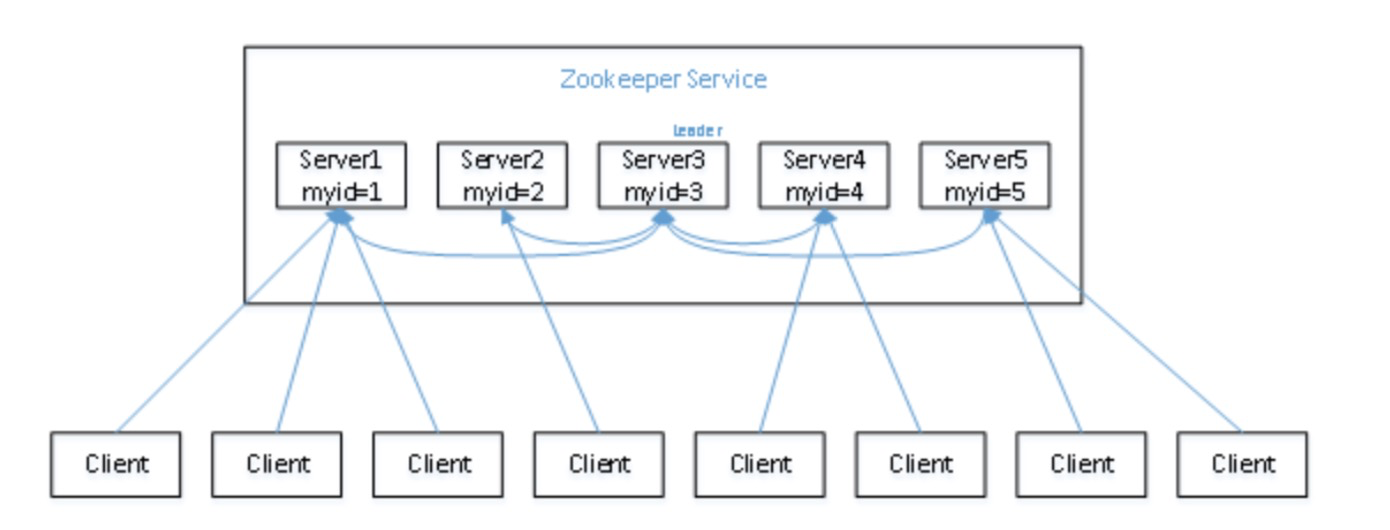
Leader选举
ZK的Leader负责同步数据,发起选举
1)半数机制:集群中半数以上机器存活,集群可用。所以zookeeper适合装在奇数台机器上。
2)Zookeeper虽然在配置文件中并没有指定master和slave。但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通过内部的选举机制临时产生的
3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









