






应用场景:
如果一个项目除了实时计算,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,应首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
1.什么是Spark?
Spark是一个分布式计算平台,是用Scala编写的计算框架。它基于内存的快速,通用,可扩展的大数据分析引擎,可以用来对分布式存储的数据进行计算处理。Spark生态系统已经发展成为一个包含多个子项目的集合:SparkCore,SparkSQL,SparkStreaming,SparkMLlib ... 等
SparkCore:
实现了Spark的基本功能,包含了任务调度,内存管理,错误恢复,与存储系统交互等模块。SparkCoer中还包含了对弹性分布式数据集的API定义。
SparkSQL:
是Spark用来操作结构化数据的程序包。通过SparkSQL我们可以使用SQL或者ApacheHive版本的SQL(HQL)来查询数据。Spark支持多种数据源比如Hive表,Parquet以及JSON等。
Spark Streaming:
是Sqark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与SparkCore中的RDDAPI高度对应。
SparkMLlib:
提供了常见的机器学习功能的程序库。包括分类,回归,聚类,协同过滤等,还提供了模型评估,数据导入等额外的支持功能。
2.什么是RDD
RDD(Resilient Distributed Dataset)
rdd叫做分部式数据集,是Spark中最基本的数据抽象,它代表一个不可变,可分区,里面的元素可并行计算的集合
3.RDD的弹性
(1) 自动进行内存和磁盘数据储存的切换 储存弹性.
Spark 优先把数据放到内存中,如果内存放不下,就会放到磁盘中,程序进行自动的存储切换
(2) 基于血统的搞效容错机制 (过程弹性)
在RDD进行转换和动作的时候,会形成RDDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据.
(3) Task 如果失败会自动进行特定次数的重试
RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认4次.
(4) Stage 如果失败会自动进行特定次数的重试
如果Job的某个Stage阶段计算失败,框架也会自动进行任务的重新计算,默认4次.
(5) Checkpoint 和 Persist 可主动或被动触发
RDD 可以通过Persist持久化将RDD缓存到内存或者磁盘,当再次用到该RDD时直接读取就行.也可以将RDD进行检查点, 检查点会将数据存储在HDFS中, 该RDD的所有父RDD 依赖都会呗移除.
(6) 数据调度弹性
Spark 把这个 JOB执行模型抽象为通用的有向无环图DAG,可以将多Stage的任务串联或并行执行,调度引擎自动处理Stage的失败以及Task的失败.
(7) 数据分片的高度弹性
可以根据业务的特征,动态调整数据分片的个数,提升整体的应用执行效率.
4.RDD 的特点
RDD 表示只读的分区的数据集, 对RDD 进行改动, 只能通过 RDD 的转换操作,由一个RDD得到一个新的RDD, 新的 RDD 包含了从其他 RDD 衍生所必需的信息.RDDs之间存在依赖, RDD的执行是按照血缘关系延时计算的.如果血缘关系较长,可以通过持久化RDD来切断血缘关系.
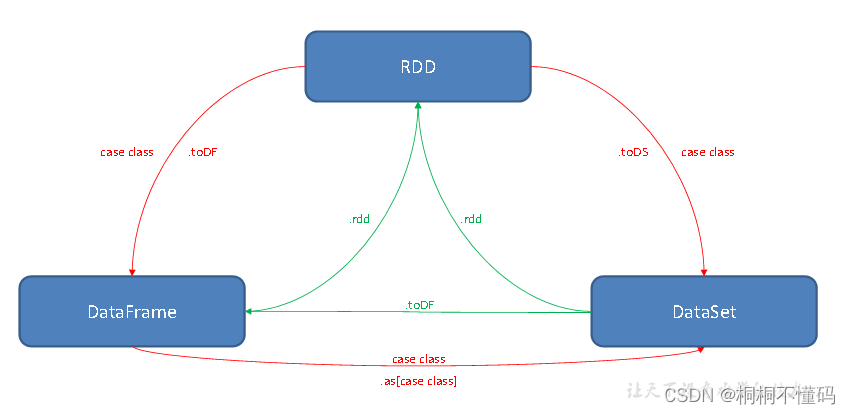
5.RDD, Dataset, DataFrame 之间的区别
(1)DataSet和RDD
大数据的框架许多都要把内存中的数据往磁盘里写,所以DataSet取代rdd和dataframe。因为,现阶段底层序列化机制使用的是java的或者Kryo的形式。但是,java序列化出来的数据很大,影响存储Kryo对于小数据量的处理很好,但是数据量一大,又会出现问题,所以官方的解决方法是使用自定义的编码器(Encoder)去序列化
(2)DataSet和DataFrame
DataSet跟DataFrame还是有挺大区别的,DataFrame开发都是写sql,但是DataSet是使用类似RDD的API。所以可以理解成DataSet就是存了个数据类型的RDD
(1)相同点:
都是分布式数据集
DataFrame底层是RDD,但是DataSet不是,不过他们最后都是转换成RDD运行
DataSet和DataFrame的相同点都是有数据特征、数据类型的分布式数据集(schema)
(2)不同点:
(a)schema信息:
RDD中的数据是没有数据类型的
DataFrame中的数据是弱数据类型,不会做数据类型检查
虽然有schema规定了数据类型,但是编译时是不会报错的,运行时才会报错
DataSet中的数据类型是强数据类型
(b)序列化机制:
RDD和DataFrame默认的序列化机制是java的序列化,可以修改为Kyro的机制
DataSet使用自定义的数据编码器进行序列化和反序列化
6.Spark Streaming:
Spark Streaming类似于Apache Storm,(flink)用于流式数据的处理。Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。
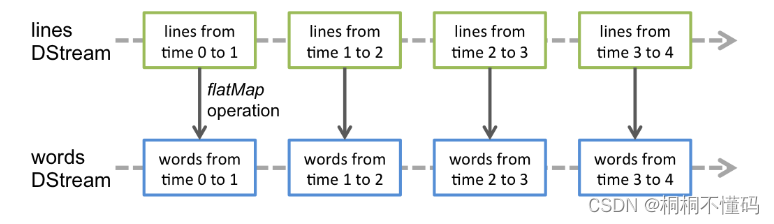
Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此 得名“离散化”)
(1)Spark Streaming架构
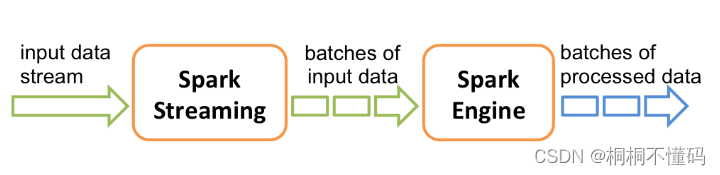
Spark Streaming使用“微批次”的架构,把流式计算当作一系列连续的小规模批处理来对待。Spark Streaming从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在500毫秒到几秒之间,由应用开发者配置。每个输入批次都形成一个RDD,以 Spark 作业的方式处理并生成其他的 RDD。 处理的结果可以以批处理的方式传给外部系统
(2)代码实现
def main(args: Array[String]): Unit = {
//创建sparkContext
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getName)
//创建sparkStream
val ssc = new StreamingContext(conf, Seconds(5))//表示每五秒一个批次.
//接收tcp实时传输数据,对数据进行wordcount. 没五秒计算一次\
val line: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.137.33", 9999)
//处理数据
val ds: DStream[String] = line.flatMap(_.split(" "))
val ds1: DStream[(String, Int)] = ds.map((_, 1)).reduceByKey(_ + _)
//写出数据
ds1.print()
//启动程序
ssc.start()
ssc.awaitTermination()
}(3)具体步骤:
- 定义消息输入源来创建DStreams.
- 定义DStreams的转化操作和输出操作。
- 通过 streamingContext.start()来启动消息采集和处理.
- 等待程序终止,可以通过streamingContext.awaitTermination()来设置
- 通过streamingContext.stop()来手动终止处理程序。
注意:
StreamingContext一旦启动,对DStreams的操作就不能修改了。在同一时间一个JVM中只有一个StreamingContext可以启动stop() 方法将同时停止SparkContext,可以传入参数stopSparkContext用于只停止StreamingContext。
(4)什么是DStreams
Discretized Stream 是 Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是以系列连续的RDD来表示。
对数据的操作也是按照RDD为单位来进行的
计算过程由Spark engine来完成
(5)基本数据源
1.文件数据源
文件数据流:能够读取所有HDFS API兼容的文件系统文件,通过fileStream方法进行读取
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)Spark Streaming 将会监控 dataDirectory 目录并不断处理移动进来的文件,记住目前不支持嵌套目录。 像flume 数据收集。
- 文件需要有相同的数据格式
- 文件进入 dataDirectory的方式需要通过移动或者重命名来实现。
- 一旦文件移动进目录,则不能再修改,即便修改了也不会读取新数据。
如果文件比较简单,则可以使用 streamingContext.textFileStream(dataDirectory)方法来读取文件。文件流不需要接收器,不需要单独分配CPU核。
2.自定义数据源 3.RDD队列

















 2612
2612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









