




简要总结
这篇文章提出了一种名为Diff-SCM的深度结构因果模型,旨在解决高维观测数据(特别是图像数据)的反事实估计这一开放性挑战。研究的核心在于,即使在已知因果结构的情况下,如何利用神经网络量化干预措施的因果效应。Diff-SCM通过结合生成式能量模型(特别是扩散模型)的最新进展,并利用因果模型所蕴含的边际和条件分布的梯度进行迭代采样来完成推理。其反事实估计过程首先通过确定性前向扩散推断潜在变量,然后利用反因果预测器相对于输入的梯度,在逆向扩散过程中进行干预。此外,论文还提出了一种评估生成反事实的新指标。
领域基础知识:因果推理与生成模型
假如我们不仅能预测未来(比如,根据天气预报知道明天会下雨),还能回答“如果我做了某件事,结果会怎样?”(比如,如果我带伞了,就不会淋湿)以及“如果过去某个条件不同,现在会怎样?”(比如,如果昨天没下雨,地面就不会湿)。这三种认知能力——观察、干预和反事实推理——构成了著名的“Pearl的因果层级”,代表了我们理解世界从浅到深的三个层次。
在人工智能领域,我们通常训练模型从大量数据中学习模式,这主要对应于“观察”层面。例如,一个图像识别模型可以学会识别猫和狗,它通过学习“看到”大量猫和狗的图片来完成任务。这属于统计学习的范畴,关注的是变量之间的关联性(例如,猫的图片通常有尖耳朵和胡须)。然而,这种关联性并不能告诉我们“为什么”这张图片是猫,或者“如果我把猫的耳朵P成圆的,它还会是猫吗?”
要回答这类“为什么”和“如果”的问题,我们需要深入到因果推理(Causal Inference)层面。因果推理旨在揭示数据生成背后的真实机制,理解变量之间“谁导致谁”的关系。在因果关系中,这种关系是具有方向性的:原因的改变会影响结果,但反过来不一定。例如,吸烟会导致肺癌,但肺癌并不会导致吸烟。理解这种方向性对于构建能够预测干预效果、甚至生成假设情景的模型至关重要。
近年来,生成模型(Generative Models)在机器学习领域取得了突破性进展。这类模型的目标是学习数据的真实分布,并能够生成与真实数据相似的新样本。其中,扩散模型(Diffusion Models)作为一种新型的生成式能量模型(Energy-Based Models, EBMs),在图像生成领域展现出惊人的能力,甚至在图像合成质量上超越了生成对抗网络(GANs)。扩散模型的工作原理可以形象地理解为:它首先模拟一个“前向扩散过程”,逐步向一张清晰的图片中添加噪声,直到图片完全变成随机噪声;然后,它学习一个“逆向去噪过程”,从完全的噪声开始,逐步去除噪声,最终恢复出一张清晰、真实的图片。这种迭代式的去噪过程,不仅能够生成高质量的样本,还为在生成过程中施加精细的控制和干预提供了新的可能性。
研究的主要背景:高维数据因果估计的挑战
尽管因果推理的理论框架已经比较成熟(例如,Judea Pearl的结构因果模型),并且深度学习在处理高维数据(如图像、文本)方面展现出无与伦比的强大能力,但将两者有效结合,特别是针对高维数据进行因果效应估计和反事实生成,仍然是一个充满挑战的开放性问题。
为什么高维数据下的因果估计如此困难?
- 维度灾难: 图像、视频等高维数据具有巨大的特征空间。传统的因果模型往往在低维、结构化的数据上表现良好,但难以直接处理这些原始高维数据。
- “黑箱”问题: 深度学习模型虽然能学习高维特征并做出准确预测,但其内部运作机制通常不透明,难以直接解读和操纵其中的因果关系。我们很难明确指出模型中的哪个神经元或哪个特征对应着因果图中的某个特定变量。
- 干预的复杂性: 在高维数据上进行“干预”远比在低维数据上复杂。例如,在图像中将“猫”变成“狗”,不仅仅是改变一个标签,而是需要改变图像的像素、形状、纹理等多个方面,同时还要保持图像的整体连贯性和真实性。
- 反事实的“最小化”要求: 生成的反事实不仅仅是另一个随机样本。它要求在满足干预条件的同时,尽可能地保留原始“事实”观测的其他非干预属性。例如,将“猫”变成“狗”,我们希望背景、光线、甚至猫的姿态等都能尽可能地保留下来,只改变“猫”的本质特征。这种“最小化改变”的要求,对模型的控制能力提出了极高的要求。
- 评估的难题: 反事实是假设性的情景,其“真实”结果在现实中无法观测。这使得评估生成反事实的质量成为一个公认的难题。我们如何判断一个生成的“狗”图片既真实,又确实是“这只猫”在被干预成“狗”之后的样子,而不是另一只完全不同的狗?
现有的许多使用神经网络进行因果估计的方法,往往只能应用于半合成的低维数据集。这使得在高维、真实世界数据上进行精确、可控的因果分析成为一个迫切需要解决的问题。
作者的问题意识:弥合深度学习与因果推理的鸿沟
论文作者Pedro Sanchez和Sotirios A. Tsaftaris正是洞察到了这一关键的空白。他们看到了扩散模型在生成高维数据方面的强大潜力,也认识到结构因果模型(SCMs)在形式化因果关系方面的严谨性。因此,他们提出的核心问题是:能否将扩散模型的强大生成能力与结构因果模型的严谨因果推理框架相结合,从而实现对高维数据的有效反事实估计?
具体而言,他们希望通过这项研究回答以下几个关键问题:
- 如何将结构因果模型中抽象的因果机制,以一种可学习、可操作的方式融入到深度生成模型(特别是扩散模型)中?
- 扩散模型的迭代采样特性如何被巧妙地利用,以实现因果推理中精确的“干预”操作?
- 在高维数据(特别是图像)上,如何生成既真实可信,又能在改变目标属性的同时保持其他属性不变的“最小化”反事实?
- 鉴于反事实的本质是假设性,无法获得真实标签,如何设计一个有效且可靠的评估指标来量化生成反事实的质量?
研究意义:推动高维数据因果推理与可解释性
这项研究具有深远的理论和实践意义:
-
理论创新与范式融合: Diff-SCM首次将扩散模型与结构因果模型这两个看似独立的领域进行了深度融合,为深度因果学习提供了一个全新的理论框架。它将扩散过程巧妙地解释为因果关系的逐步“弱化”(前向扩散)和“强化”(逆向扩散),这种创新的视角极大地丰富了我们对因果生成模型的理解和构建方式。这种融合不仅是技术上的叠加,更是对两种范式内在联系的深刻洞察。
-
技术突破与高维数据处理: 论文提出的方法成功地克服了现有因果估计方法在处理高维图像数据时的局限性。通过将因果干预嵌入到扩散模型的生成过程中,Diff-SCM能够直接在像素层面生成复杂、高分辨率的反事实图像。这一技术突破为图像领域的因果分析、深度学习模型的可解释性(例如,通过生成反事实来解释模型决策)、公平性分析(通过改变敏感属性观察输出变化)以及增强模型对抗性鲁棒性等多个前沿应用开辟了广阔的道路。
-
反事实评估的里程碑: 针对反事实评估这一长期存在的难题,论文提出了“反事实潜在散度(Counterfactual Latent Divergence, CLD)”这一新颖且有效的评估指标。CLD不仅考虑了生成反事实的视觉真实性和与目标类别的匹配度,更关键的是,它巧妙地融入了对反事实“最小性”的考量。这个指标的提出,为未来反事实研究提供了一个更全面、更具指导意义的评估工具,有助于推动该领域的标准化和进展。
-
赋能可解释AI与智能决策: 能够生成高质量的反事实,意味着我们能更好地理解复杂深度学习模型的决策依据,并探索不同干预措施可能带来的后果。例如,在医疗领域,医生可以模拟“如果患者的某个生理指标发生变化,疾病的诊断结果会如何?”;在金融领域,分析师可以探索“如果某个市场参数调整,投资组合的风险会如何?”。这种“假设情景”的生成能力,将极大地增强人工智能系统的透明度和可信赖性,为需要做出关键决策的领域提供强大的决策支持工具。
综上所述,Diff-SCM的提出是深度学习与因果推理交叉领域的一个重大进展,它不仅在理论上实现了两大前沿技术的融合,更在实践中为高维数据上的精确、可控因果干预和反事实估计提供了强大而有效的工具和理论基础。
正文(逻辑梳理)
背景:因果推理的维度挑战与扩散模型的曙光
想象一下,我们有一张猫的图片,我们想知道“如果这张猫的图片被分类成狗,它应该长什么样?”这个问题不是简单地生成一张狗的图片,而是在保持原图片尽可能多的其他特征(比如背景,我们有一张猫的图片,我们想知道“如果这张猫的图片被分类成狗,它应该长什么样?”这个问题不是简单地生成一张狗的图片,而是在保持原图片尽可能多的其他特征(比如背景、姿态等)不变的情况下,只改变那些导致其被识别为“狗”的特征。这正是反事实估计(Counterfactual Estimation)的核心:针对一个已发生的“事实”(factual observation),提出一个“如果…那么…”的假设情景,并生成对应的结果。
在机器学习领域,我们通常处理的是“观测数据”(observational data),即被动收集到的数据,从中学习变量之间的统计关联。然而,因果推理则更进一步,它关注变量间的“干预”(intervention)效果。干预意味着我们主动改变某个变量(原因),然后观察其他变量(结果)如何响应。这种干预能力是构建智能系统、理解世界运作机制的关键。
然而,当数据是高维的,比如图像、视频或复杂的生物医学信号时,进行因果干预和反事实估计就变得极其困难。传统的因果模型往往难以直接处理这些复杂的高维数据,而深度学习模型虽然擅长学习高维特征,但其“黑箱”性质使得因果关系的显式建模和干预变得不透明。
近年来,生成式能量模型(Generative Energy-Based Models, EBMs)中的扩散模型(Diffusion Models)取得了显著进展。这类模型通过模拟一个逐步加噪的“前向扩散过程”,然后学习一个“逆向去噪过程”来生成高质量数据。扩散模型的迭代性质和在潜在空间中操作的能力,为在生成过程中施加精细控制提供了新的可能性。这让研究者们看到了将扩散模型与因果推理结合,以解决高维数据反事实估计挑战的希望。
挑战:高维反事实估计的症结所在
将因果推理与深度生成模型结合,特别是针对高维数据进行反事实估计,面临着几个核心挑战:
- 因果机制的深度学习表示: 结构因果模型(SCMs)通过结构赋值(structural assignments) x ( k ) : = f ( k ) ( p a ( k ) , u ( k ) ) x^{(k)} := f^{(k)}(pa^{(k)}, u^{(k)}) x(k):=f(k)(pa(k),u(k))来定义变量间的因果机制,其中 x ( k ) x^{(k)} x(k)是内生变量, p a ( k ) pa^{(k)} pa(k)是其父节点(直接原因), u ( k ) u^{(k)} u(k)是外生变量(代表未建模的外部因素或随机性)。如何让深度神经网络学习并表示这些抽象的因果机制,并确保其符合因果图的结构,是一个难题。
- 干预的实现: 在因果推理中,“干预”是一个非常具体的操作,例如 d o ( X = x ) do(X=x) do(X=x)表示将变量X强制设置为某个值x,这会“切断”X与它父节点之间的因果连接。如何在深度生成模型的迭代过程中,精确地模拟这种因果机制的“破坏”和“重构”,是实现干预的关键。
- 反事实的生成与控制: 反事实估计不仅需要生成干预后的结果,还需要在给定一个“事实”观测的基础上进行。这意味着生成过程必须在改变特定属性的同时,尽可能保留原始观测的其他非干预属性。这要求模型具备精细的控制能力,以实现“最小化”的改变。
- 评估的困难: 反事实是“假设”情景,在现实中无法观测到其“真实值”。因此,如何客观、有效地评估生成反事实的质量(包括真实性、相关性以及最小性),是一个公认的难题。传统的像素级比较往往不足以捕捉图像结构和语义上的变化。
方法:Diff-SCM——扩散过程与结构因果模型的深度融合
Diff-SCM(Diffusion Causal Models)正是为了应对上述挑战而提出的。它巧妙地将扩散模型的迭代生成能力与结构因果模型的理论框架结合起来,实现高维数据的反事实估计。
核心思想:SDEs下的因果关系演变
Diff-SCM的核心思想是将因果变量的动态建模为伊藤过程(Itô process),即一种随机微分方程(Stochastic Differential Equation, SDE)。这个过程描述了变量 x t ( k ) x^{(k)}_t xt(k)在时间 t ∈ [ 0 , T ] t \in [0, T] t∈[0,T]内从观测到的内生变量 x 0 ( k ) = x ( k ) x^{(k)}_0 = x^{(k)} x0(k)=x(k)逐渐演变为其对应的外生噪声 x T ( k ) = u ( k ) x^{(k)}_T = u^{(k)} xT(k)=u(k),然后再逆转的过程。
1. 前向扩散过程(Forward Diffusion):因果关系的弱化
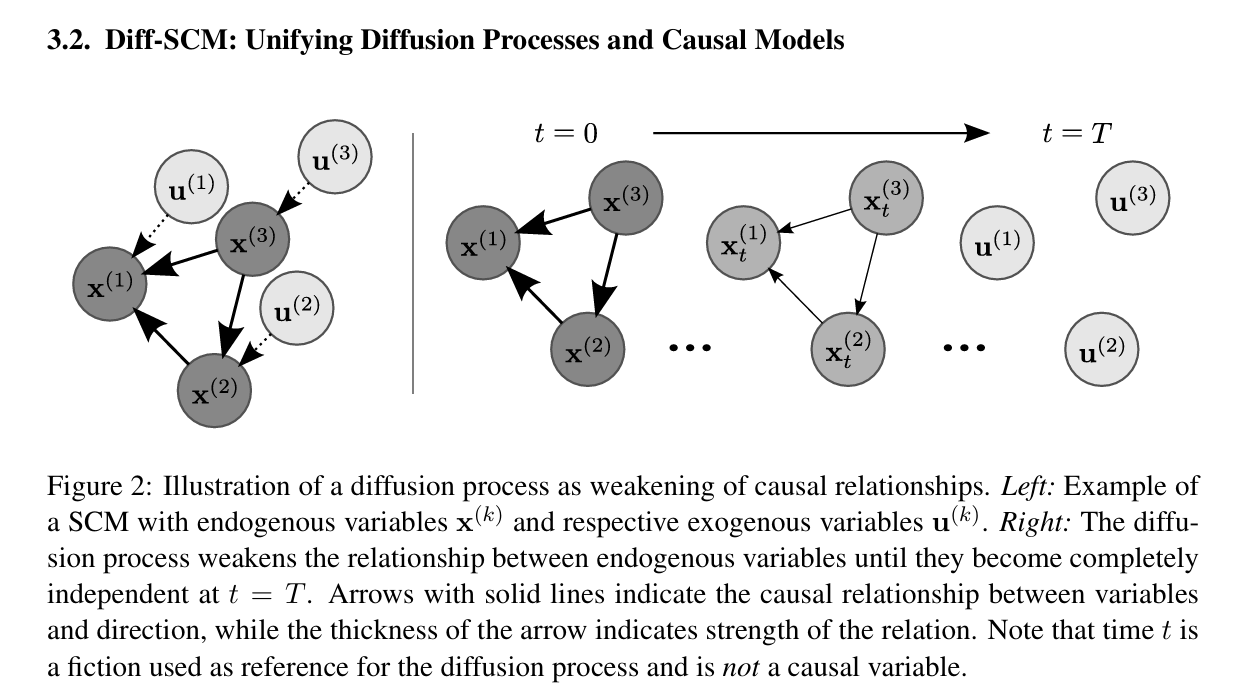
Diff-SCM将前向扩散过程理解为因果关系的逐渐弱化。随着时间 t t t的增加,数据点 x 0 ( k ) x^{(k)}_0 x0(k)逐渐被高斯噪声污染,直到 t = T t=T t=T时,所有的内生变量都变成了独立的、符合高斯分布的外生噪声 u ( k ) u^{(k)} u(k)。这模拟了SCM中外生变量 U U U相互独立这一约束 p ( U ) = ∏ k = 1 K p ( u ( k ) ) p(U) = \prod_{k=1}^K p(u^{(k)}) p(U)=∏k=1Kp(u(k))。
数学上,这可以表示为以下SDE(针对每个节点 k k k):
d x ( k ) = − 1 2 β t x ( k ) d t + β t d w , ∀ k ∈ [ 1 , K ] dx^{(k)} = -\frac{1}{2}\beta_t x^{(k)} dt + \sqrt{\beta_t} dw, \quad \forall k \in [1, K] dx(k)=−21βtx(k)dt+βtdw,∀k∈[1,K]
其中, x ( k ) x^{(k)} x(k)是第 k k k个内生变量, β t \beta_t βt是与时间相关的噪声方差, d w dw dw是维纳过程(Brownian motion),代表随机噪声的累积。这个过程使得原始SCM所蕴含的联合分布 p G ( X ) p_G(X) pG(X)逐渐扩散为独立的高斯分布,等价于 p ( U ) p(U) p(U)。
2. 逆向扩散过程(Reverse Diffusion):因果关系的强化与干预
生成过程是前向SDE的逆向SDE的解。逆向过程通过迭代更新外生噪声 x T ( k ) = u ( k ) x^{(k)}_T = u^{(k)} xT(k)=u(k),并利用数据分布的梯度 ∇ x t ( k ) log p ( x t ( k ) ) \nabla_{x^{(k)}_t} \log p(x^{(k)}_t) ∇xt(k)logp(xt(k)),逐步将其恢复为原始的内生变量 x 0 ( k ) = x ( k ) x^{(k)}_0 = x^{(k)} x0(k)=x(k)。这个过程可以被视为因果关系的强化。
逆向SDE的公式为:
d x ( k ) = [ − 1 2 β t + β t ∇ x t ( k ) log p ( x t ( k ) ) ] d t + β t d w ˉ dx^{(k)} = \left[-\frac{1}{2}\beta_t + \beta_t \nabla_{x^{(k)}_t} \log p(x^{(k)}_t)\right] dt + \sqrt{\beta_t} d\bar{w} dx(k)=[−21βt+βt∇xt(k)logp(xt(k))]dt+βtdwˉ
其中, d w ˉ d\bar{w} dwˉ是逆向维纳过程。关键在于,这个逆向SDE的迭代特性为施加干预提供了极大的灵活性。
干预机制:反因果预测器的梯度引导
Diff-SCM的一个关键创新在于,它利用反因果预测器(anti-causal predictor)的梯度来施加干预。
命题1(Proposition 1):干预作为反因果梯度更新
论文提出了一个重要的命题:考虑SCM <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









