






 本文介绍了Hive的数据类型,包括创建表的语法规则和示例,特别是重点讲解了分区表的创建,如单分区和双分区的建表语句。还涉及到添加、删除分区的操作,并讨论了内部表与外部表的区别。此外,文中提到了数据加载方法,如`LOAD DATA`命令的使用,以及如何根据字段查找和更新数据。最后,提到了正则匹配在加载数据中的应用。
本文介绍了Hive的数据类型,包括创建表的语法规则和示例,特别是重点讲解了分区表的创建,如单分区和双分区的建表语句。还涉及到添加、删除分区的操作,并讨论了内部表与外部表的区别。此外,文中提到了数据加载方法,如`LOAD DATA`命令的使用,以及如何根据字段查找和更新数据。最后,提到了正则匹配在加载数据中的应用。
数据类型:
Hive的数据类型
: primitive_type
| array_type
| map_type
| struct_type
:primitive_type
|TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| STRINGhive中创建表的语法规则:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
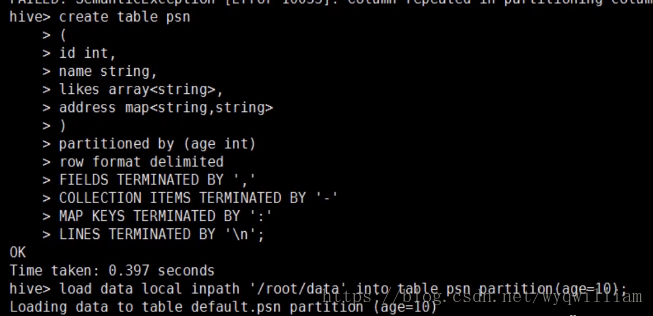
创建表示范:
CREATE TABLE person(
id INT,
name STRING,
age INT,
likes ARRAY<STRING>,
address MAP<STRING,STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
查看表状态:
DESCRIBE [EXTENDED|FORMATTED] table_name创建文件,加上数据:
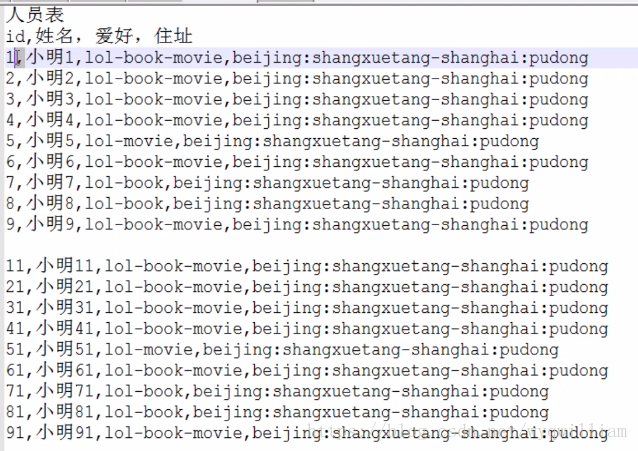
加载数据(将数据加载在表中):

查看:
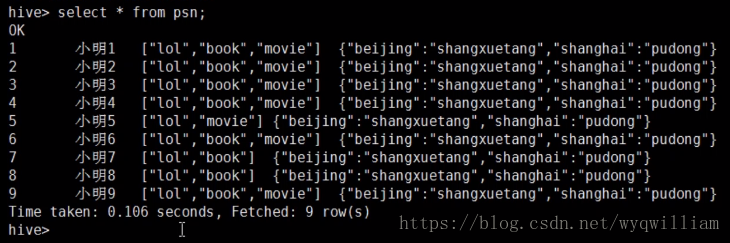
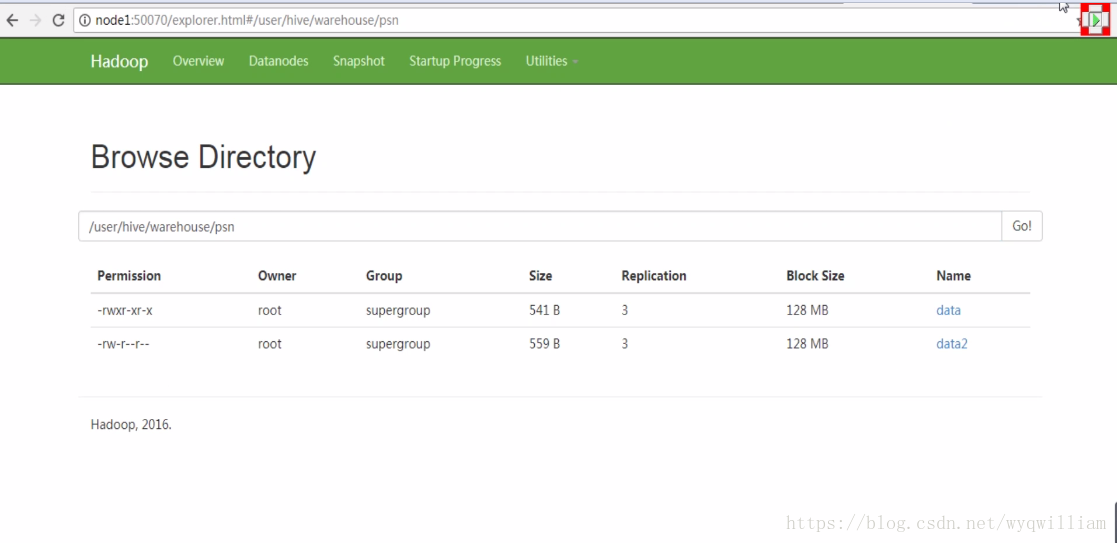
查看当前进程:
ss -nal内部表与外部表:
详细请看:
https://blog.youkuaiyun.com/wyqwilliam/article/details/81061038
创建表
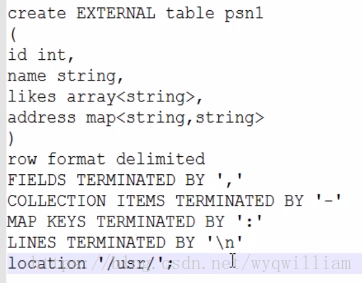
加载数据
![]()
查看状态
![]()
hive创建表中的分区问题:
Hive 分区partition
必须在表定义时指定对应的partition字段
a、单分区建表语句:
create table day_table (id int, content string) partitioned by (dt string);
单分区表,按天分区,在表结构中存在id,content,dt三列。 以dt为文件夹区分
b、 双分区建表语句:
create table day_hour_table (id int, content string) partitioned by (dt string, hour string);
双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。 先以dt为文件夹,再以hour子文件夹区分
添加分区:
Hive添加分区表语法 (表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (partition_column = partition_col_value, partition_column = partition_col_value, ...)
例: ALTER TABLE day_table ADD PARTITION (dt='2008-08-08', hour='08')
create table person4 (
id int,
name string,
likes ARRAY<string>,
address MAP<string,string>
)
PARTITIONED BY (sex string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';
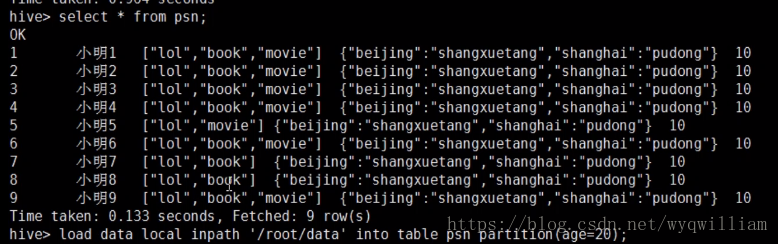
load data local inpath '/tmp/data/person0_data' into table person4 PARTITION (sex='1');hive> select * from person4;
OK
11 小明11 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
21 小明21 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
31 小明31 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
41 小明41 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
51 小明51 ["lol","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
61 小明61 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
71 小明71 ["lol","book"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
81 小明81 ["lol","book"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
91 小明91 ["lol","book","movie"] {"beijing":"shangxuetang","shanghai":"pudong"} 1
Time taken: 0.804 seconds, Fetched: 9 row(s)
添加双分区:
create table person6 (
id int,
name string,
likes ARRAY<string>,
address MAP<string,string>
)
PARTITIONED BY (sex string, age int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';
load data local inpath '/tmp/data/person6_data' into table person6 PARTITION (sex='1',age=18);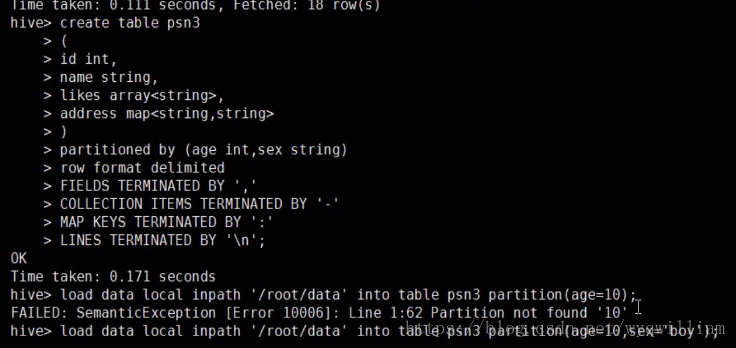
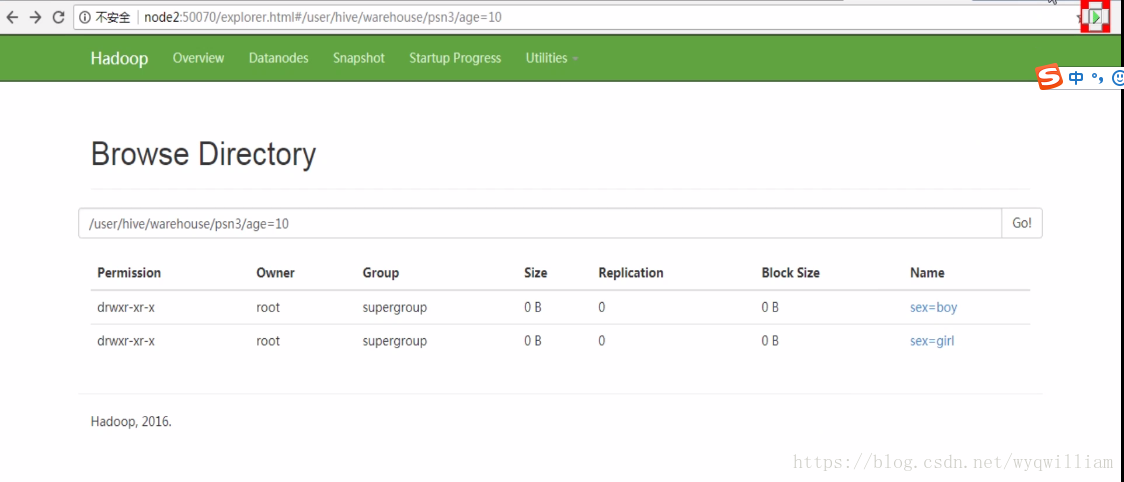 添加分区:
添加分区:
![]()
删除分区:
添加/删除分区,内部表删除分区后该分区下的数据也会被删除,外部表删除分区后该分 区下的数据不会被删除
ALTER TABLE person4 add PARTITION (sex='3');
ALTER TABLE person6 drop PARTITION (sex='1',age=18);
ALTER TABLE person6 drop PARTITION (sex='2');#会删除 sex='2'和 age=18
ALTER TABLE person4 drop PARTITION (age=20); #会删除 sex='3'和 age=20 
load data inpath 'hdfs path' into table table_name
这个操作实际是把 hdfs path 下的文件移动到了 hive 配置的存放的数据的目录下
load data local inpath 'hdfs path' into table table_name
这个操作实际是把本地的文件上传到 hdfs 的临时目录下,然后把该文件移动到了 hive 配 置的存放的数据的目录下
多次 load 相同的文件,数据会追加,而不是覆盖
按照字段查找数据:
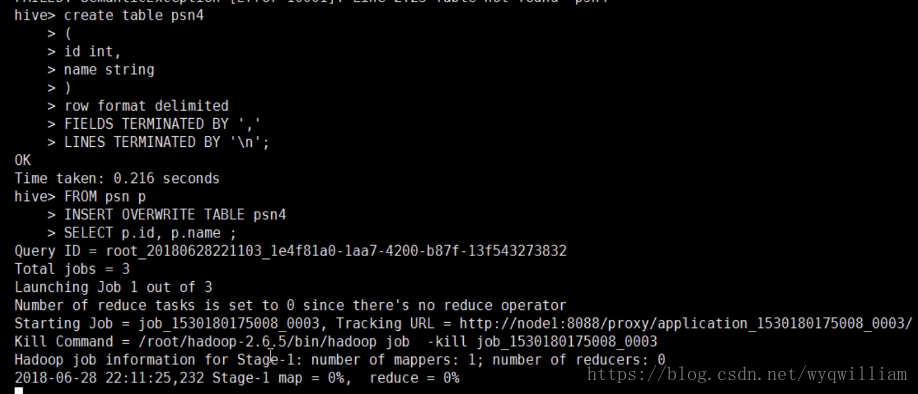
分字段查找数据,然后再添加
 查看:
查看:
hive中插入文件的四种方式:
1.load
load data local inpath '/tmp/data/person0_data' into table person0;2.from insert
from person0
insert into table person7
select id,name,hobbies,address;
create table person2 as select id, hobbies from person0; #MapReduce3.insert values into table from
4.hdfs dfs -put
hive版本1.2.1
更新数据:

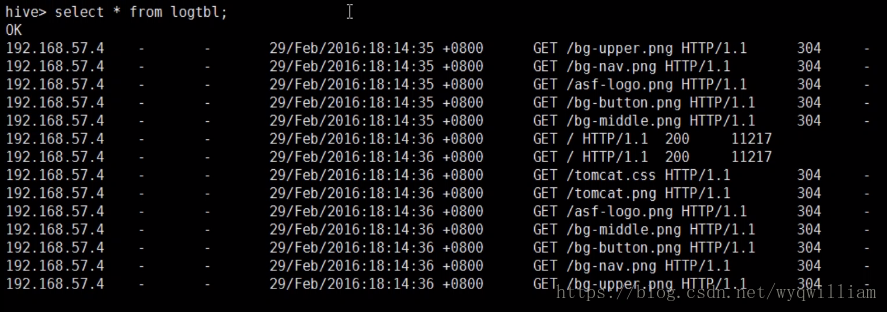
利用正则匹配加载数据
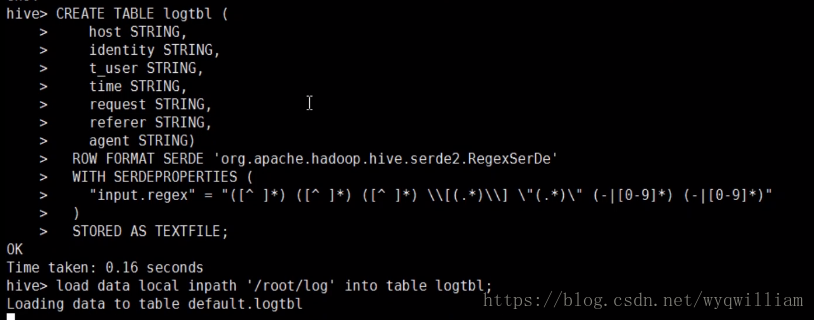
原数据文件

















 6340
6340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









