







 混淆矩阵用于评估分类模型的性能,包含True Positives, False Positives, False Negatives和True Negatives。准确率、召回率、Precision、F1-Score等指标揭示模型优劣。在二分类和多分类问题中,这些指标帮助我们全面理解模型效果。"
112017333,10546045,IDEA中Vue与后端数据实时刷新实践,"['Vue框架', '后端开发', '数据库操作', '移动端开发', '机器学习']
混淆矩阵用于评估分类模型的性能,包含True Positives, False Positives, False Negatives和True Negatives。准确率、召回率、Precision、F1-Score等指标揭示模型优劣。在二分类和多分类问题中,这些指标帮助我们全面理解模型效果。"
112017333,10546045,IDEA中Vue与后端数据实时刷新实践,"['Vue框架', '后端开发', '数据库操作', '移动端开发', '机器学习']
混淆矩阵是除了ROC曲线和AUC之外的另一个判断分类好坏程度的方法。
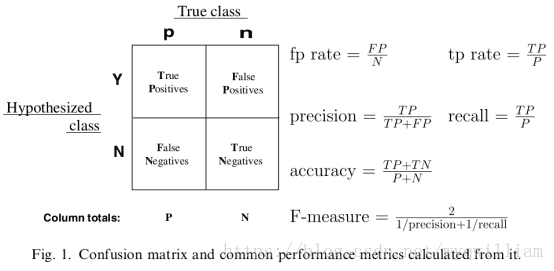
对以上混淆矩阵的解释:
P:样本数据中的正例数。
N:样本数据中的负例数。
Y:通过模型预测出来的正例数。
N:通过模型预测出来的负例数。
True Positives:真阳性,表示实际是正样本预测成正样本的样本数。
Falese Positives:假阳性,表示实际是负样本预测成正样本的样本数。
混淆矩阵是除了ROC曲线和AUC之外的另一个判断分类好坏程度的方法。
对以上混淆矩阵的解释:
P:样本数据中的正例数。
N:样本数据中的负例数。
Y:通过模型预测出来的正例数。
N:通过模型预测出来的负例数。
True Positives:真阳性,表示实际是正样本预测成正样本的样本数。
Falese Positives:假阳性,表示实际是负样本预测成正样本的样本数。
 1260
2087
1126
8887
1260
2087
1126
8887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















