










我们在上一遍文章中介绍了如何通过 LangChain实现开发自定义MCP Server,并langgraph.prebuilt 提供的预定义代理(Agent)模板+DeepSeek实现了MCP Client的调用。
本文在上一篇文章基础上继续深化,介绍基于 LangChain +DeepSeek如何实现实现多个MCP调用。首先自定义了两个MCP Server,其中:一个是算术计算器MCP Server,并通过sdtio传输协议发布,另一个是天气预报MCP Server,通过sse传输协议发布。然后实现一个MCP Client,使用langgraph.prebuilt的create_react_agent代理模板,并调用DeepSeek大模型完成整个 MCP 调用流程,同时给出来整个示例的 Python 代码。
一、MCP是什么
现代 Web 应用正加速与大语言模型(LLMs)深度融合,构建超越传统问答场景的智能解决方案。为突破模型知识边界,增强上下文理解能力,开发者普遍采用多源数据集成策略,将 LLM 与搜索引擎、数据库、文件系统等外部资源互联。然而,异构数据源的协议差异与格式壁垒,往往导致集成复杂度激增,成为制约 AI 应用规模化落地的关键瓶颈。因此,Anthropic公司推出了模型上下文协议(Model Context Protocol, MCP),通过标准化接口为 AI 应用与外部数据源建立统一交互通道。这一协议体系不仅实现了数据获取与操作的规范化,更构建起可扩展的智能体开发框架,使开发者能够基于原生 LLM 能力快速构建复杂工作流。

MCP遵循客户端 - 服务器架构,围绕几个关键组件:
1、MCP Host:用户使用的应用程序,比如:Claude客户端、Cursor这样的AI应用程序,它与大语言模型集成,提供 AI 交互环境以访问不同工具和数据源。
2、MCP Client:与MCP Server建立并维护一对一连接的组件。它属于AI应用程序的内部组件,使其能够与 MCP Server通信。例如,若需要 PostgreSQL 数据,MCP 客户端会将请求格式化为结构化消息发送给 MCP 服务器。
3、MCP Server:外部数据源集成并公开与之交互功能的组件。作为中间件连接 AI 模型与外部系统(如 PostgreSQL、Google Drive 或 API)。例如,当 Claude 分析 PostgreSQL 中的销售数据时,PostgreSQL 的 MCP 服务器会充当 Claude 与数据库之间的连接器。
二、前提条件
1、Python运行环境安装。建议使用Python3.10以上版本,本示例使用了 Python 3.12.9版本。
2、Python开发工具安装。本人是vue\Java\python多种语言开发,所以使用了 IntelliJ IDEA开发工具。读者可以根据个人习惯选择合适的Python开发工具,比如:PyCharm、VS Code。
3、注册DeepSeek,获得api_key。访问deepseek的AI开放平台完成注册:https://platform.deepseek.com。
三、代码实现
1、创建python工程
首先,通过开发工具创建一个python工程。这一步很简单,不再描述。
接着,激活虚拟环境。在项目根目录下,并通过以下命令创建并激活虚拟环境:
python -m venv venv #有的环境下命令是python3或者py
.\venv\Scripts\activate #windows下的激活命令
注意:如果是通过IDEA工具创建的Python工程,默认会创建并激活venv虚拟环境,就不再需要手动创建了。
2、pip安装依赖包
本示例使用langchain、LangGraph、langchain-mcp-adapters和DeepSeek,所以需要先安装依赖包。
在虚拟环境命令窗口执行:
pip install -U langchain langgraph
pip install -U langchain-mcp-adapters
pip install -U langchain-deepseek3、开发计算器MCP Server
通过Python开发工具,创建一个python文件,命名为math_server.py,通过stdio传输协议发布。源代码如下:
from mcp.server.fastmcp import FastMCP
import logging
# 配置日志记录器
logging.basicConfig(
level=logging.INFO, # 设置日志级别为 INFO
format="%(asctime)s - %(levelname)s - %(message)s" # 日志格式
)
logger = logging.getLogger(__name__)
# 创建 FastMCP 实例
mcp = FastMCP("Math")
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
logger.info("The add method is called: a=%d, b=%d", a, b) # 记录加法调用日志
return a + b
@mcp.tool()
def multiply(a: int, b: int) -> int:
"""Multiply two numbers"""
logger.info("The multiply method is called: a=%d, b=%d", a, b) # 记录乘法调用日志
return a * b
if __name__ == "__main__":
logger.info("Start math server through MCP") # 记录服务启动日志
mcp.run(transport="stdio") # 启动服务并使用标准输入输出通信4、开发天气预报MCP Server
通过Python开发工具,创建一个python文件,命名为weather_server.py,通过sse传输协议发布。源代码如下:
from mcp.server.fastmcp import FastMCP
import logging
# 配置日志记录器
logging.basicConfig(
level=logging.INFO, # 设置日志级别为 INFO
format="%(asctime)s - %(levelname)s - %(message)s" # 日志格式
)
logger = logging.getLogger(__name__)
mcp = FastMCP("Weather")
@mcp.tool()
async def get_weather(location: str) -> str:
"""Get weather for location."""
logger.info("The get_weather method is called: location=%s", location)
return "天气阳光明媚,晴空万里。"
if __name__ == "__main__":
logger.info("Start weather server through MCP") # 记录服务启动日志
mcp.run(transport="sse")5、开发MCP Client
通过Python开发工具,创建一个python文件,命名为math_client.py。源代码如下:
import asyncio
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
from langchain_deepseek import ChatDeepSeek
# 初始化 DeepSeek 大模型客户端
llm = ChatDeepSeek(
model="deepseek-chat", # 指定 DeepSeek 的模型名称
api_key="sk-e508ba61639640848060a1a2c1ee7b17" # 替换为您自己的 DeepSeek API 密钥
)
# 解析并输出结果
def print_optimized_result(agent_response):
"""
解析代理响应并输出优化后的结果。
:param agent_response: 代理返回的完整响应
"""
messages = agent_response.get("messages", [])
steps = [] # 用于记录计算步骤
final_answer = None # 最终答案
for message in messages:
if hasattr(message, "additional_kwargs") and "tool_calls" in message.additional_kwargs:
# 提取工具调用信息
tool_calls = message.additional_kwargs["tool_calls"]
for tool_call in tool_calls:
tool_name = tool_call["function"]["name"]
tool_args = tool_call["function"]["arguments"]
steps.append(f"调用工具: {tool_name}({tool_args})")
elif message.type == "tool":
# 提取工具执行结果
tool_name = message.name
tool_result = message.content
steps.append(f"{tool_name} 的结果是: {tool_result}")
elif message.type == "ai":
# 提取最终答案
final_answer = message.content
# 打印优化后的结果
print("\n计算过程:")
for step in steps:
print(f"- {step}")
if final_answer:
print(f"\n最终答案: {final_answer}")
# 定义异步主函数
async def main():
async with MultiServerMCPClient(
{
"math": {
"command": "python",
"args": ["./math_server.py"],
"transport": "stdio",
},
"weather": {
"url": "http://localhost:8000/sse",
"transport": "sse",
}
}
) as client:
agent = create_react_agent(llm, client.get_tools())
# 循环接收用户输入
while True:
try:
# 提示用户输入问题
user_input = input("\n请输入您的问题(或输入 'exit' 退出):")
if user_input.lower() == "exit":
print("感谢使用!再见!")
break
# 调用代理处理问题
agent_response = await agent.ainvoke({"messages": user_input})
# 调用抽取的方法处理输出结果
print_optimized_result(agent_response)
except Exception as e:
print(f"发生错误:{e}")
continue
# 使用 asyncio 运行异步主函数
if __name__ == "__main__":
asyncio.run(main())关键代码解释说明:
langgraph.prebuilt 是 LangGraph 框架中的一个模块,主要用于提供预构建的工具和功能,以简化复杂任务的实现。LangGraph 是一个基于 LangChain 的扩展框架,专注于构建多智能体(multi-agent)系统、工作流管理和任务编排。langgraph.prebuilt 提供了一些现成的组件和工具,帮助开发者快速搭建特定的工作流或任务逻辑,而无需从零开始编写代码。
(1)from langgraph.prebuilt import create_react_agent提供了预定义的代理(Agent)模板。langgraph.prebuilt 提供了一些预定义的代理(Agent)模板,例如基于反应式(reactive)逻辑的代理。 这些模板可以快速生成能够处理特定任务的代理,比如问答、任务分解、工具调用等。
(2)agent = create_react_agent(llm, client.get_tools())实现了工具集成与任务编排。支持将多个工具(tools)集成到工作流中,并通过预定义的逻辑进行任务编排。例如,您可以轻松地将算术计算工具、搜索引擎工具或其他自定义工具集成到代理的工作流中。
四、运行测试
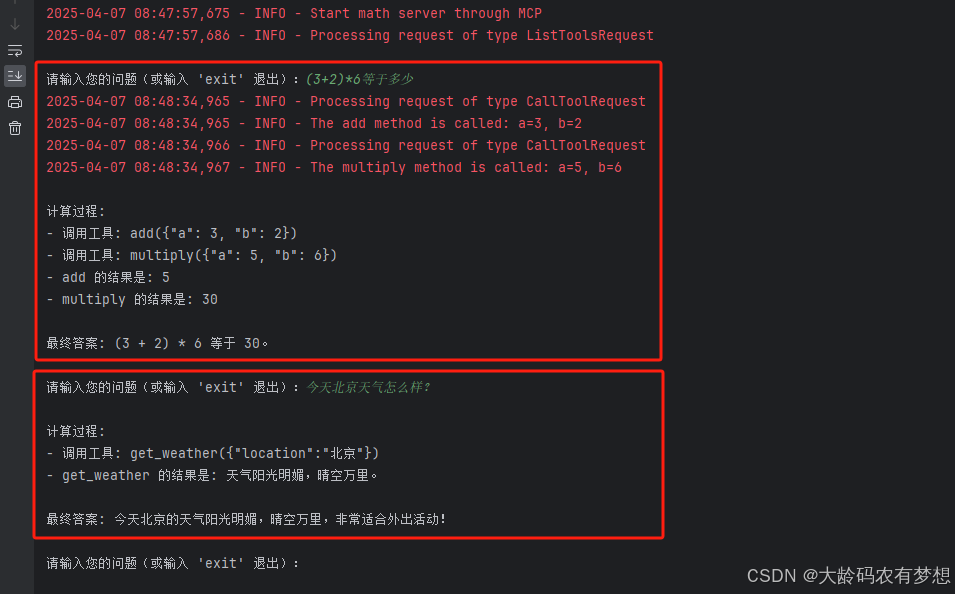
先运行MCP Server,即分别运行math_server.py和weather_server.py,再运行math_client.py,进行AI对话,观察日志输出结果,确定是否理解了用户的输入信息,并分别调用了对应的MCP Server服务。
智能体平台在线体验:https://www.yunbangong100.com:31111/


















 55
55

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











