




 本文介绍如何使用Python3进行微博评论的情感分析。通过爬取微博评论数据,结合百度AI的情感分析API,将评论分为积极和消极两类。首先设置Python3环境,安装Pycharm、Postman和Scrapy。接着爬取评论数据,获取百度AI的认证参数,使用Postman获取Access_token。最后编写代码并运行Scrapy爬虫,得到情感分析结果。
本文介绍如何使用Python3进行微博评论的情感分析。通过爬取微博评论数据,结合百度AI的情感分析API,将评论分为积极和消极两类。首先设置Python3环境,安装Pycharm、Postman和Scrapy。接着爬取评论数据,获取百度AI的认证参数,使用Postman获取Access_token。最后编写代码并运行Scrapy爬虫,得到情感分析结果。
本文主要针对微博评论的正负情感分析,案例简单,只能针对微博评论第一页进行情感分析,分为积极情感和消极情感
首先需要Python3的开发环境,此处我用到的是Python3.7.3
然后需要下载安装Pycharm、Postman和Scrapy框架
一、爬取微博评论数据
打开你想要爬取的微博评论,然后shift+ctrl+i打开控制台应用
在network中找出关于评论的那一条,在preview中可以看到是否有评论,如果有评论就打开旁边 的header,提取评论的url以备后面用到,具体看下图
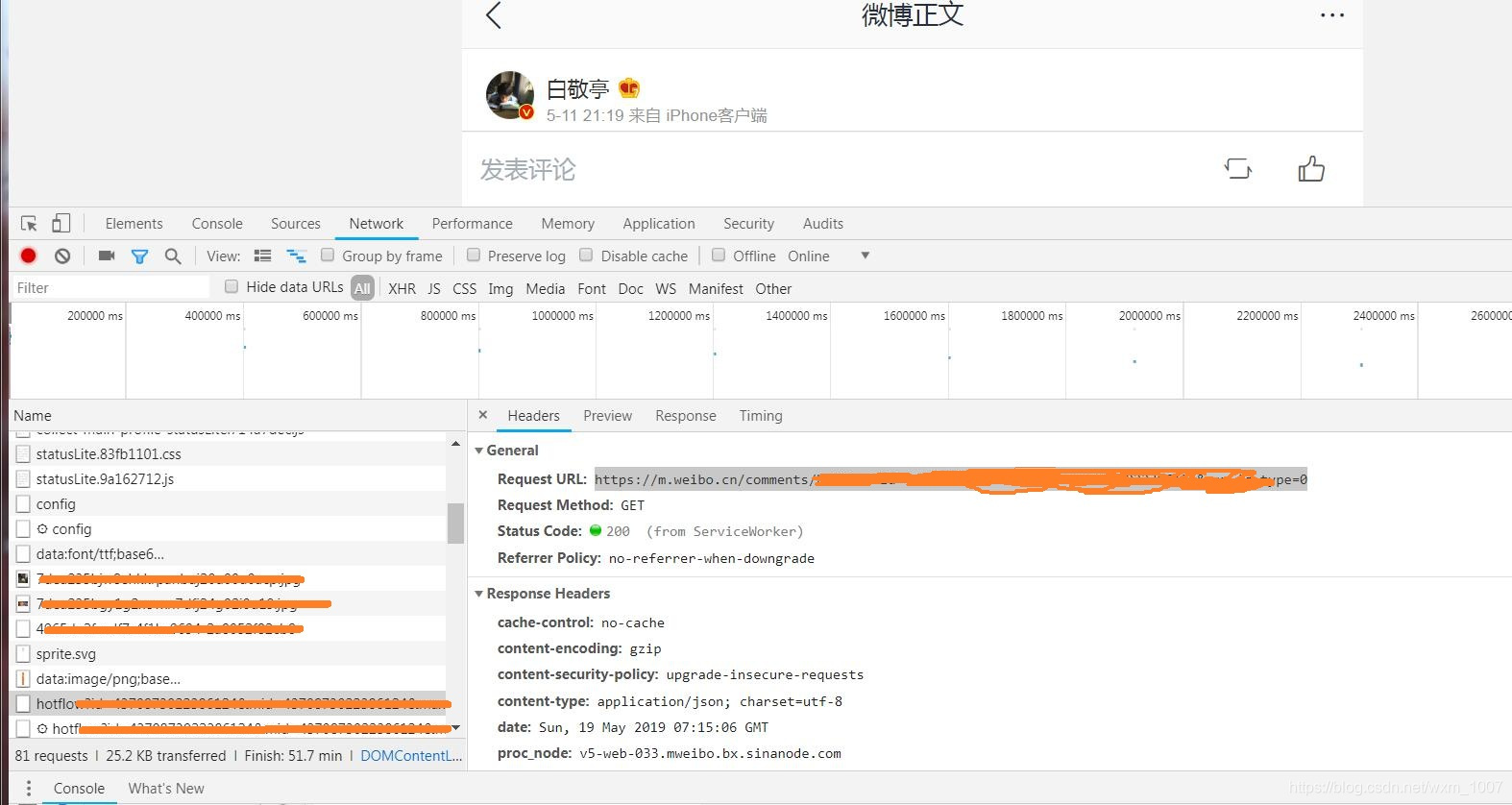
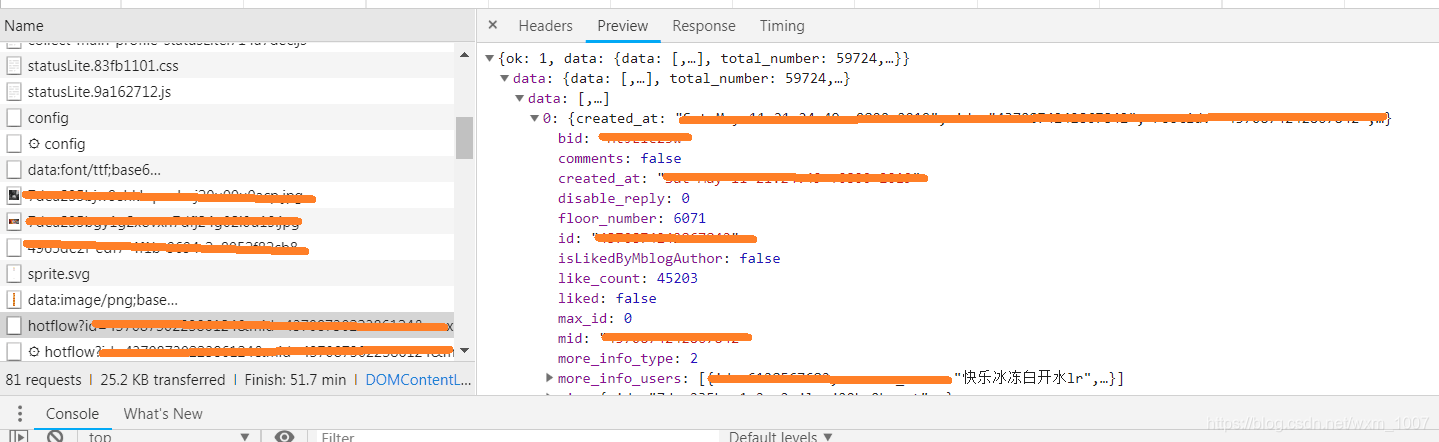
二、调用百度AI
注册百度云账号并申请情感分析项目,获得AppID、API Key、Secret Key这些参数,具体可参考:https://blog.youkuaiyun.com/ChenVast/article/details/82682750
然后用postman来获取Access_token,因为之后调用API需要用上加载url的后面,具体可参考:
http://ai.baidu.com/docs#/Auth/top
此处我是用postman来获取(postman后面还可以用来调试,所以此处选择了postman),如下图: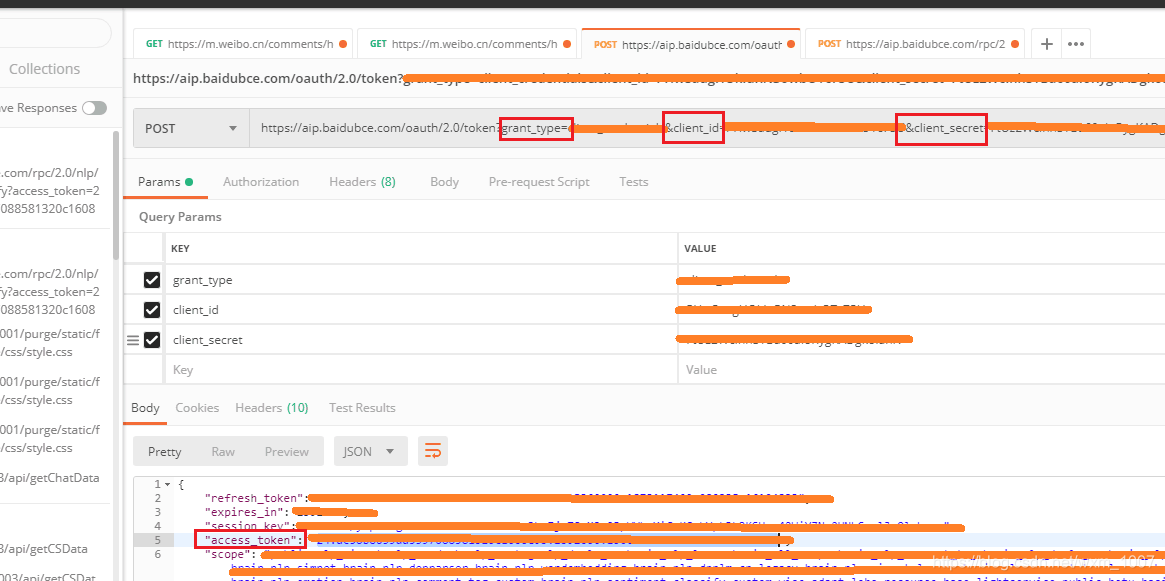
上面红框框选的Access_Token就是我们所需要的
三、编写代码
主要代码如下(comments.py里面,这里的comments.py是上一篇文章创建Scrapy第一个爬虫项目得方法得来的):
import scrapy
import json
import codecs
import re
class CommentSpider(scrapy.Spider):
name = "comment"
start_urls = [
"https://m.weibo.cn/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"(这就是前文获取的微博评论的url)
]
def parse(self, response):
# filename = "firstPageComment.json"
# data = json.loads(response.text)
# print(data['data']['data'][0]['text'])
# data = json.dumps(data, ensure_ascii = False)
# # print(data.data[0].text)
# # print(data)
# with codecs.open(filename, 'w+', encoding='utf-8') as f:
# f.write(data)
"""
解析评论信息
:param response: Response对象
"""
result = json.loads(response.text)
if result.get('ok') and result.get('data').get('data') and len(result.get('data').get('data')):
comment_list = result.get('data').get('data')
for comment in comment_list:
if (comment.get('text')):
comment_text = re.sub(r'</?(.+?)>', '', comment.get('text'))
# print("1",comment_text)
body = {"text": comment_text}
# TODO: 百度API 发送请求,获取自然语言分析结果
yield scrapy.http.Request('https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?access_token=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',(这是获取的Accessed_token加在后面)
callback = self.requestCallBack,
method='POST',
body = json.dumps(body))
def requestCallBack(self, response):
result = json.loads(response.text)
if result.get('text') and result.get('items'):
# print(result.get('text'), '积极情感' if result.get('items')[0].get('positive_prob') > result.get('items')[0].get('negative_prob') else '消极情感')
print('积极情感' if result.get('items')[0].get('positive_prob') > result.get('items')[0].get('negative_prob') else '消极情感')
# else:
# print('error', result)
然后修改items.py里面的内容:
import scrapy
class WeibospiderItem(scrapy.Item):
# define the fields for your item here like:
weibo_id = scrapy.Field()
text = scrapy.Field()
pass
四、运行
在Pycharm终端输入scrapy crawl comment
然后稍等一会就可以在终端看见输出结果,如下图:
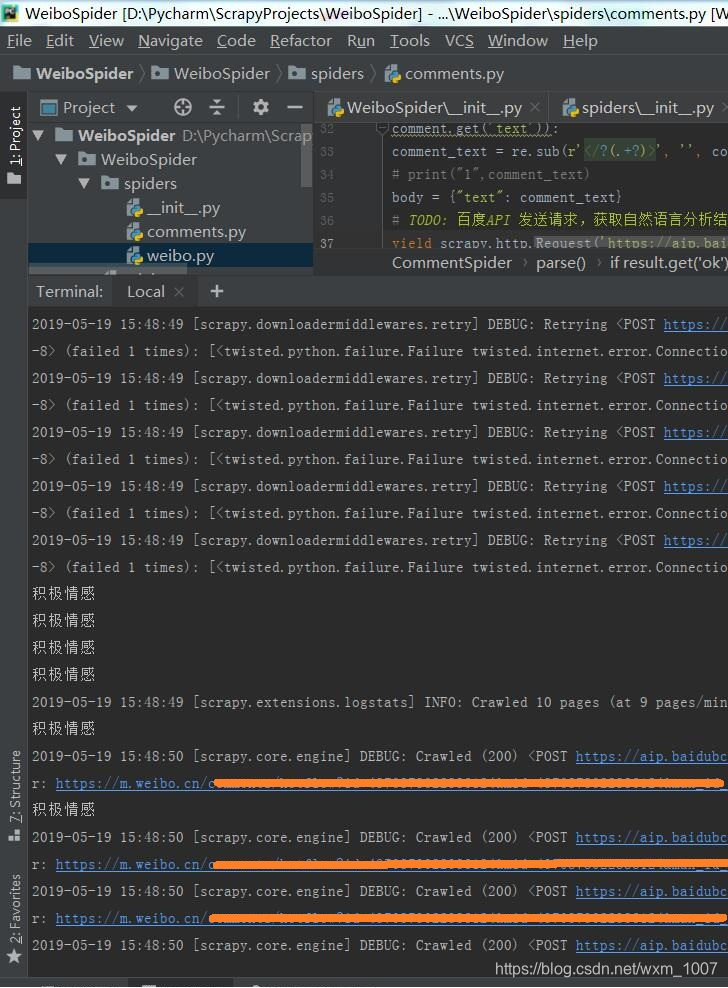
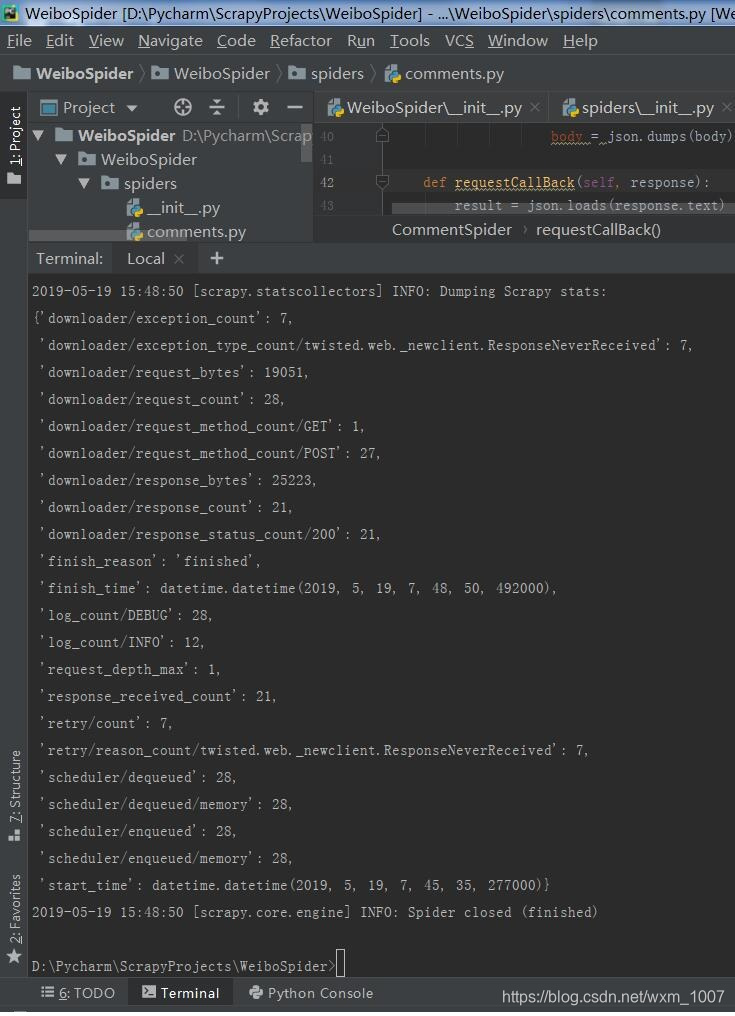
中途用postman 调试的截图如下: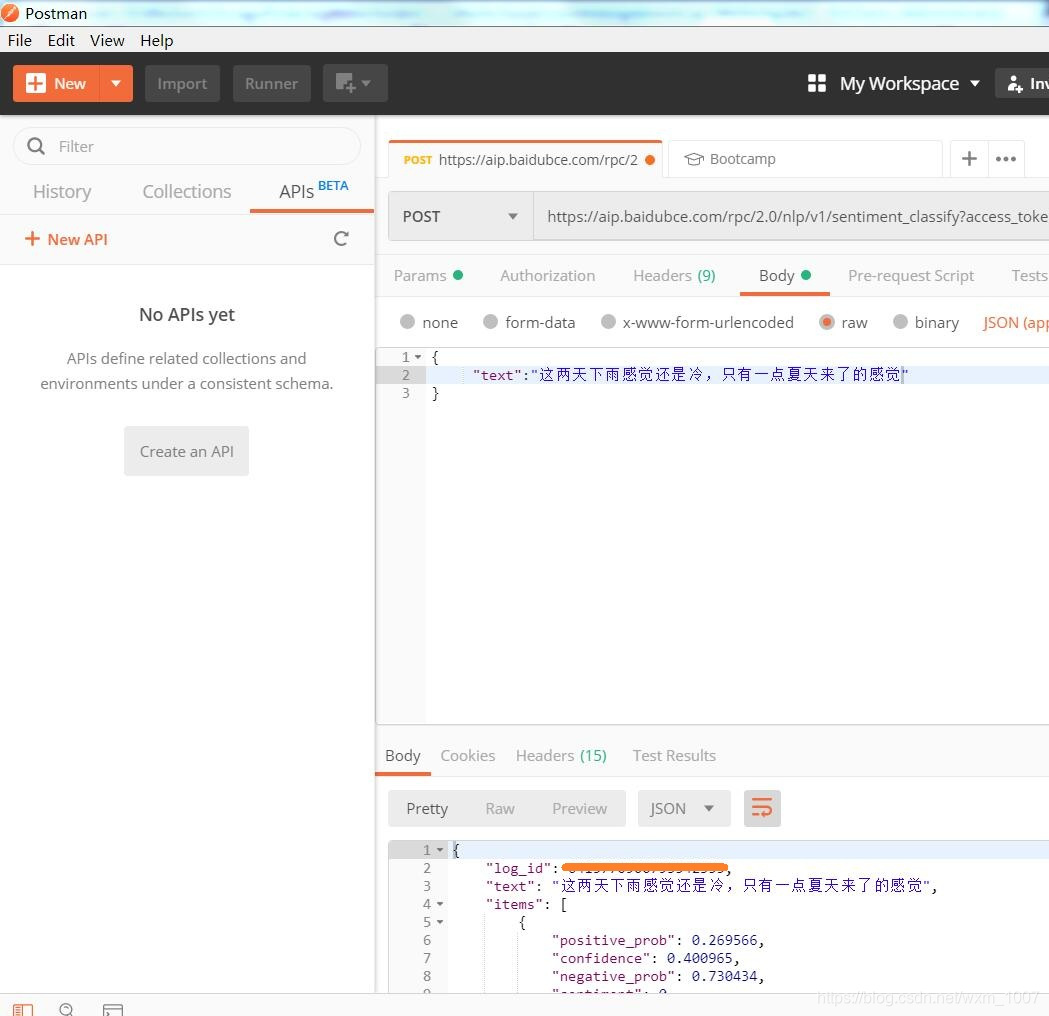
到这里就大致完成了,本人实属菜鸟,是在朋友指导下才得以完成。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









