



 本文基于统计学习方法(李航)的教材例子,利用Python的sklearn库构建并可视化决策树。文章详细介绍了如何处理数据、应用决策树模型,并通过graphviz进行图形展示。在过程中,还解决了中文乱码问题,提供了完整的代码示例。
本文基于统计学习方法(李航)的教材例子,利用Python的sklearn库构建并可视化决策树。文章详细介绍了如何处理数据、应用决策树模型,并通过graphviz进行图形展示。在过程中,还解决了中文乱码问题,提供了完整的代码示例。
以统计学习方法(李航)这本书的例子为基础
需要注意的地方:
- 我用的是pycharm
- python版本是3.7
- graphviz是一个软件,在pycharm里面下了还得去官网下
下完之后得加入环境变量可能还需要重启电脑 - 缺啥库就安啥库
- 那个数据是我自己设置的,手敲的。
贷款申请样本数据表
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
数据集
| 特征量 | 表示 |
|---|---|
| 年龄 | 青年:1 中年:2 老年:3 |
| 有工作 | 是:1 否:0 |
| 有自己的房子 | 是1:否:0 |
| 信贷情况 | 一般:1 好:2 非常好:3 |
| 类别 | 是:1 否:0 |
dataset=[
[1,0,0,1,0],
[1,0,0,2,0],
[1,1,0,2,1],
[1,1,1,1,1],
[1,0,0,1,0],
[2,0,0,2,0],
[2,0,0,2,0],
[2,1,1,2,1],
[2,0,1,3,1],
[2,0,1,2,1],
[3,0,1,3,1],
[3,0,1,2,1],
[3,1,0,3,1],
[3,1,0,3,1],
[3,0,0,1,0]
]
X = [x[0:4] for x in dataset] #取出特征值
print(X)
Y = [y[-1] for y in dataset]#取Y值
print(Y)
用sklearn的求决策树的方法求出决策树,再利用graphviz进行可视化
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
dataset=[
[1,0,0,1,0],
[1,0,0,2,0],
[1,1,0,2,1],
[1,1,1,1,1],
[1,0,0,1,0],
[2,0,0,2,0],
[2,0,0,2,0],
[2,1,1,2,1],
[2,0,1,3,1],
[2,0,1,2,1],
[3,0,1,3,1],
[3,0,1,2,1],
[3,1,0,3,1],
[3,1,0,3,1],
[3,0,0,1,0]
]
feature =['年龄','没有工作','没有自己的房子','信贷情况']
classname =['不借','借']
X = [x[0:4] for x in dataset]
print(X)
Y = [y[-1] for y in dataset]
print(Y)
tree_clf = DecisionTreeClassifier(max_depth=4)
tree_clf.fit(X, Y)
上面是求决策树的方法但是不能可视化,然后在此基础上加上下面的代码
export_graphviz(
tree_clf,
out_file=("loan.dot"),
feature_names=feature,
class_names=classname,
rounded=True,
filled=True,
)
运行代码会在本目录生成loan.dot文件
再在pycharm里面的本地终端中进入当前目录执行以下命令
dot -Tpng loan.dot -o loan.png
就会生成png的图片。
我的目录如下
但是你会发现会出现中文乱码
那么你继续加以下代码
import re
# 打开 dot_data.dot,修改 fontname="支持的中文字体"
f = open("./loan.dot", "r+", encoding="utf-8")
open('./Tree_utf8.dot', 'w', encoding="utf-8").write(re.sub(r'fontname=helvetica', 'fontname="Microsoft YaHei"', f.read()))
f.close()
然后看看效果图
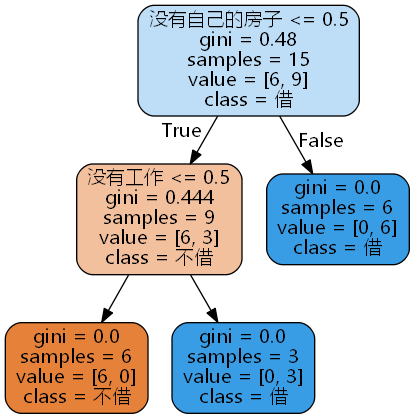
整个代码如下
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
dataset=[
[1,0,0,1,0],
[1,0,0,2,0],
[1,1,0,2,1],
[1,1,1,1,1],
[1,0,0,1,0],
[2,0,0,2,0],
[2,0,0,2,0],
[2,1,1,2,1],
[2,0,1,3,1],
[2,0,1,2,1],
[3,0,1,3,1],
[3,0,1,2,1],
[3,1,0,3,1],
[3,1,0,3,1],
[3,0,0,1,0]
]
feature =['年龄','没有工作','没有自己的房子','信贷情况']
classname =['不借','借']
X = [x[0:4] for x in dataset]
print(X)
Y = [y[-1] for y in dataset]
print(Y)
tree_clf = DecisionTreeClassifier(max_depth=4)
tree_clf.fit(X, Y)
export_graphviz(
tree_clf,
out_file=("loan.dot"),
feature_names=feature,
class_names=classname,
rounded=True,
filled=True,
)
import re
# 打开 dot_data.dot,修改 fontname="支持的中文字体"
f = open("./loan.dot", "r+", encoding="utf-8")
open('./Tree_utf8.dot', 'w', encoding="utf-8").write(re.sub(r'fontname=helvetica', 'fontname="Microsoft YaHei"', f.read()))
f.close()
'''
dot -Tpng loan.dot -o loan.png
生成图片
'''


















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









