




 博客聚焦NMT中单词删除或重复生成问题,介绍了普通注意力计算方法。重点阐述了sparsemax在源语句单词上的稀疏、constrained softmax在时间步上的稀疏,将二者结合产生稀疏并有界的注意力权重,还说明了上界值u的三种确定方式。
博客聚焦NMT中单词删除或重复生成问题,介绍了普通注意力计算方法。重点阐述了sparsemax在源语句单词上的稀疏、constrained softmax在时间步上的稀疏,将二者结合产生稀疏并有界的注意力权重,还说明了上界值u的三种确定方式。
背景:在NMT中,单词有时会从源中删除或在翻译中重复生成。
思路:普通的注意力计算中,在得到每个时间步隐藏层状态的分数后,对其softmax归一化处理得到权重值。sparsemax:在源语句单词上的稀疏,计算时只考虑一些单词,其余单词的概率为0。constrained softmax:在时间步上的稀疏,返回一个接近sofrmax(z)的分布,注意力概率受限于上界值,本文将这两个稀疏结合在一起,产生稀疏并有界的注意力权重。
之前普通注意力的计算:![]()
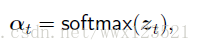
![]() 是注意力的值,也就是隐藏层状态每个时间步的权重,
是注意力的值,也就是隐藏层状态每个时间步的权重,![]() 是对分数的softmax归一化处理。
是对分数的softmax归一化处理。
![]() 上界值,限制了每个单词能接收的注意力数量。
上界值,限制了每个单词能接收的注意力数量。
sparsemax: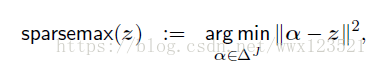
![]()
是分数z在概率单纯形上的欧几里得投影。 这些预测倾向于触及单纯形的边界,产生稀疏的概率分布。 这允许解码器仅使用源中的几个单词,为所有其他单词指定零概率。
constrained softmax:
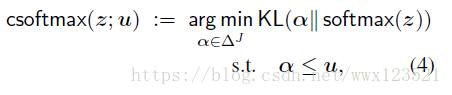
![]()
![]()
![]()
![]()
u是上界向量。返回一个接近sofrmax(z)的分布,注意力概率受限于u。
![]() 表示表示每个源单词词在时间步骤t已经收到的累积注意力。
表示表示每个源单词词在时间步骤t已经收到的累积注意力。![]() 表示包含每个源单词词的fertility上限的向量。
表示包含每个源单词词的fertility上限的向量。
直观地,每个源单词j获得![]() 个注意力的credits,其在解码过程中被消耗。 如果所有credits都用完了,那么从那时起它就不会受到关注。 与sparsemax变换不同,sparsemax变换对源单词进行稀疏注意,受约束的softmax导致随时间步长的稀疏性。
个注意力的credits,其在解码过程中被消耗。 如果所有credits都用完了,那么从那时起它就不会受到关注。 与sparsemax变换不同,sparsemax变换对源单词进行稀疏注意,受约束的softmax导致随时间步长的稀疏性。
constrained sparsemax:
结合以上两种,提供稀疏并有界的概率:
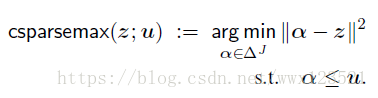
上界值u的确定:
1.constant:所有源单词的fertility都是一个固定的整数
2.guided:基于IBM模型训练一个单词对齐器,词典中每一个单词的fertility是训练数据中的最大观察值
3.predict:使用一个双向LSTM 标签器训练一个离散的fertility预测模型,在训练的时候,使用fast-align评估的fertility作为监督

















 7271
7271




 到【灌水乐园】发言
到【灌水乐园】发言







