






支持向量机(Support Vector Machine,SVM)是一种流行的监督学习算法,用于分类和回归分析。SVM 算法的核心思想是在特征空间中寻找一个最优的分割超平面,以此来区分不同的类别。以下是 SVM 算法的原理、优缺点以及适应场景的详细介绍。
SVM算法原理
1. **最大化间隔**:SVM 试图找到一个能够最大化类别间隔的超平面。这个超平面被称为最优分割超平面(Optimal Hyperplane),它到最近的数据点(支持向量)的距离最大。
2. **支持向量**:支持向量是那些位于或最接近分割超平面的数据点。这些点对于定义超平面至关重要。
3. **核技巧**:SVM 可以使用核技巧来处理非线性问题。核函数允许算法在高维空间中寻找最优分割超平面,而无需显式地计算高维空间中的坐标。
4. **软间隔**:在实际应用中,数据可能不是完全线性可分的。SVM 引入了软间隔的概念,允许一些数据点违反间隔规则,以适应数据的实际情况。
SVM算法的优点
1. **优秀的泛化能力**:SVM 在高维空间和低维样本情况下都能表现良好,具有很好的泛化能力。
2. **适用于非线性问题**:通过核技巧,SVM 可以有效地处理非线性分类问题。
3. **鲁棒性**:SVM 对于异常值和噪声数据具有一定的鲁棒性。
4. **参数少**:与神经网络等算法相比,SVM 的参数较少,这使得模型选择和调参更加容易。
5. **优化问题明确**:SVM 的优化目标是明确的,即最大化间隔,这使得算法在理论上具有良好的基础。
SVM算法的缺点
-
计算复杂度高:对于大规模数据集,SVM 的训练过程可能非常耗时。
-
核选择问题:核函数的选择和参数设置对模型性能有很大影响,但并没有通用的指导原则。
-
对数据规模敏感:SVM 对于大规模数据集的处理能力有限,尤其是在核方法中。
-
不适合大规模数据:在处理大规模数据集时,SVM 的性能可能会下降,因为它需要计算和存储一个巨大的矩阵。
-
对缺失数据敏感:SVM 对缺失数据非常敏感,需要对数据进行预处理以填补缺失值
SVM算法的适应场景
-
小到中等规模的数据集:SVM 在小到中等规模的数据集上表现良好,尤其是当数据具有高维特征时。
-
特征空间维度高:当特征空间的维度远高于样本数量时,SVM 可以有效地处理这类问题。
-
非线性问题:对于非线性分类问题,通过选择合适的核函数,SVM 可以取得良好的性能。
-
需要高精度的场景:在需要高精度分类的场景中,如生物信息学、医学诊断等,SVM 是一个不错的选择。
-
数据预处理充分:当数据经过充分预处理,如特征选择、缺失值处理等,SVM 可以发挥出更好的性能。
利用SVM对鸢尾花数据集进行分类:从数据可视化到模型训练
我们将通过一个简单的例子来展示如何使用支持向量机(SVM)对鸢尾花(Iris)数据集进行分类。我们将从数据的可视化开始,然后进行模型的训练,最后可视化SVM的分类结果。
代码解析
1. 数据加载与可视化
data = pd.read_csv("iris.csv", header=None)
data1 = data.iloc[:50, :] # 假设前50行是第一个类别
data2 = data.iloc[50:, :] # 假设后100行是其他类别
plt.scatter(data1[1], data1[3], marker='+') # 绘制第一个类别的数据
plt.scatter(data2[1], data2[3], marker='o') # 绘制其他类别的数据
plt.show()-
功能:加载数据并绘制两个类别的数据点。
-
问题:
-
数据集的类别划分可能不准确。Iris 数据集通常包含三个类别,但代码中只分为两类。
-
数据集的列索引可能不准确。Iris 数据集通常有5列(4个特征 + 1个标签),但代码中直接使用列索引
[1]和[3]。
-
2. SVM 模型训练
X = data.iloc[:, [1, 3]] # 选择第2列和第4列作为特征
y = data.iloc[:, -1] # 假设最后一列是标签
svm = SVC(kernel='linear', C=float('inf'), random_state=0)
svm.fit(X, y)-
功能:使用 SVM 模型对数据进行训练。
-
问题:
-
C=float('inf'):C是正则化参数,值越大表示对误分类的惩罚越大。设置为无穷大可能会导致过拟合。 -
数据集的标签可能需要进一步处理。Iris 数据集的标签通常是字符串(如 "setosa"、"versicolor"、"virginica"),需要将其转换为数值标签。
-
3. 可视化 SVM 结果
w = svm.coef_[0] # 获取超平面的权重
b = svm.intercept_[0] # 获取偏置项
x1 = np.linspace(0, 7, 300) # 生成 x 轴的值
x2 = -(w[0] * x1 + b) / w[1] # 超平面方程
x3 = (1 - (w[0] * x1 + b)) / w[1] # 上边界
x4 = (-1 - (w[0] * x1 + b)) / w[1] # 下边界
plt.plot(x1, x2, linewidth=2, color='r') # 绘制超平面
plt.plot(x1, x3, linewidth=1, color='r', linestyle='--') # 绘制上边界
plt.plot(x1, x4, linewidth=1, color='r', linestyle='--') # 绘制下边界
plt.scatter(vets[:, 0], vets[:, 1], c='b', marker='x') # 绘制支持向量
plt.show()-
功能:绘制超平面和支持向量。
运行结果
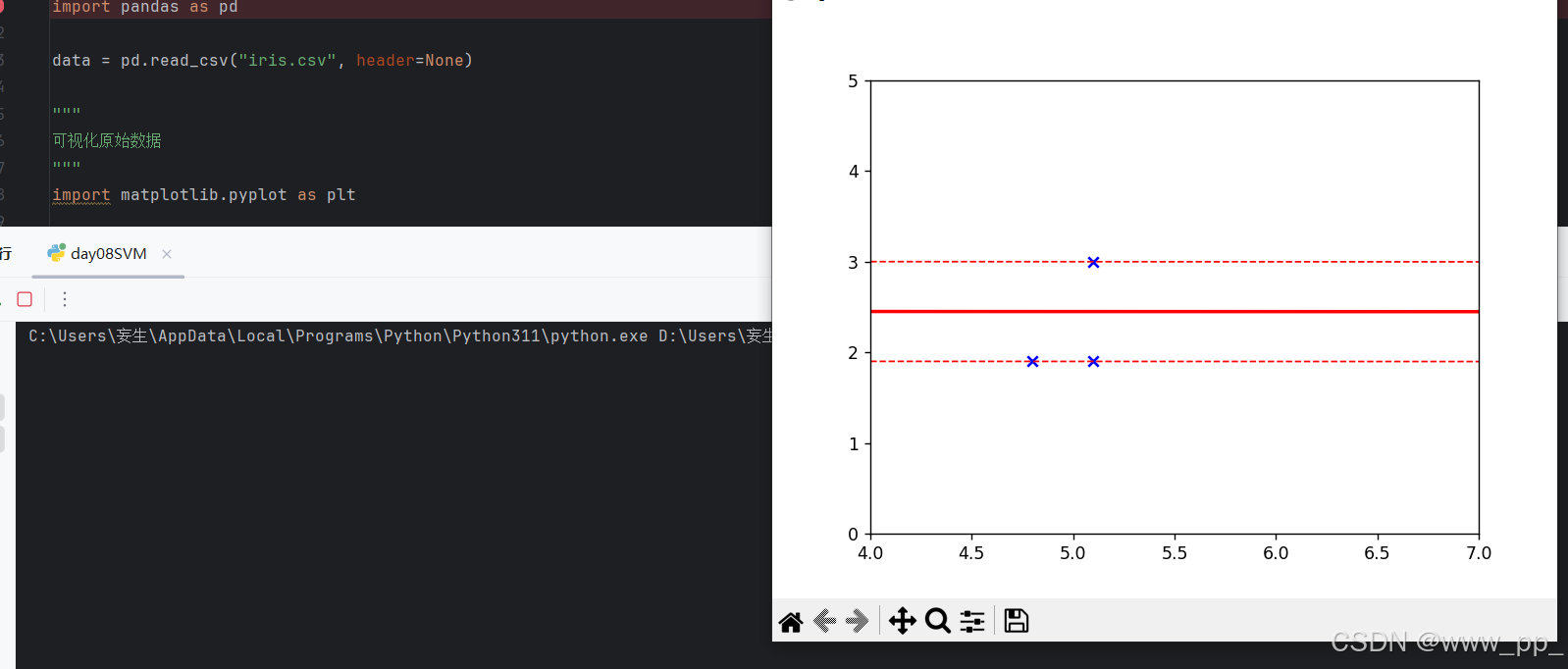
结论
通过这个简单的例子,我们展示了如何使用SVM对鸢尾花数据集进行分类。我们首先对数据进行了可视化,然后训练了一个SVM模型,并最终可视化了分类结果。这个过程不仅展示了SVM的强大功能,也展示了数据可视化在理解模型中的重要性。
总结
总的来说,SVM 是一种强大的分类算法,适用于多种场景,尤其是在数据预处理充分且数据规模适中的情况下。然而,对于大规模数据集和需要快速响应的应用,SVM 可能不是最佳选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









