






你知道吗,目前各大手机应用商店里已经有7个搭载了DeepSeek-R1的手机app,其中3个的回答质量优于DeepSeek官方app,另外4个虽然回答质量略逊一筹,但服务稳定,几乎不会出现"服务器繁忙"的情况。

想找到最好的搭载了DeepSeek-R1的手机app?以下是我的三大推荐:
第一名,天工app及其网页端
第二名,跃问网页端
第三名,知乎app和知乎直答网页端
为什么推荐这些应用?我在2025年2月19日至24日进行了详细测评。结果表明,这三个应用不仅避免了排名第四的deepseek官方app常见的"服务器繁忙"问题,而且回答质量更为出色。
如果上述三个应用都无法使用,可以考虑以下备选(按推荐顺序排列):
第五名,腾讯元宝 第六名,秘塔AI搜索 第七名,问小白 第八名,纳米AI搜索
测试方法:
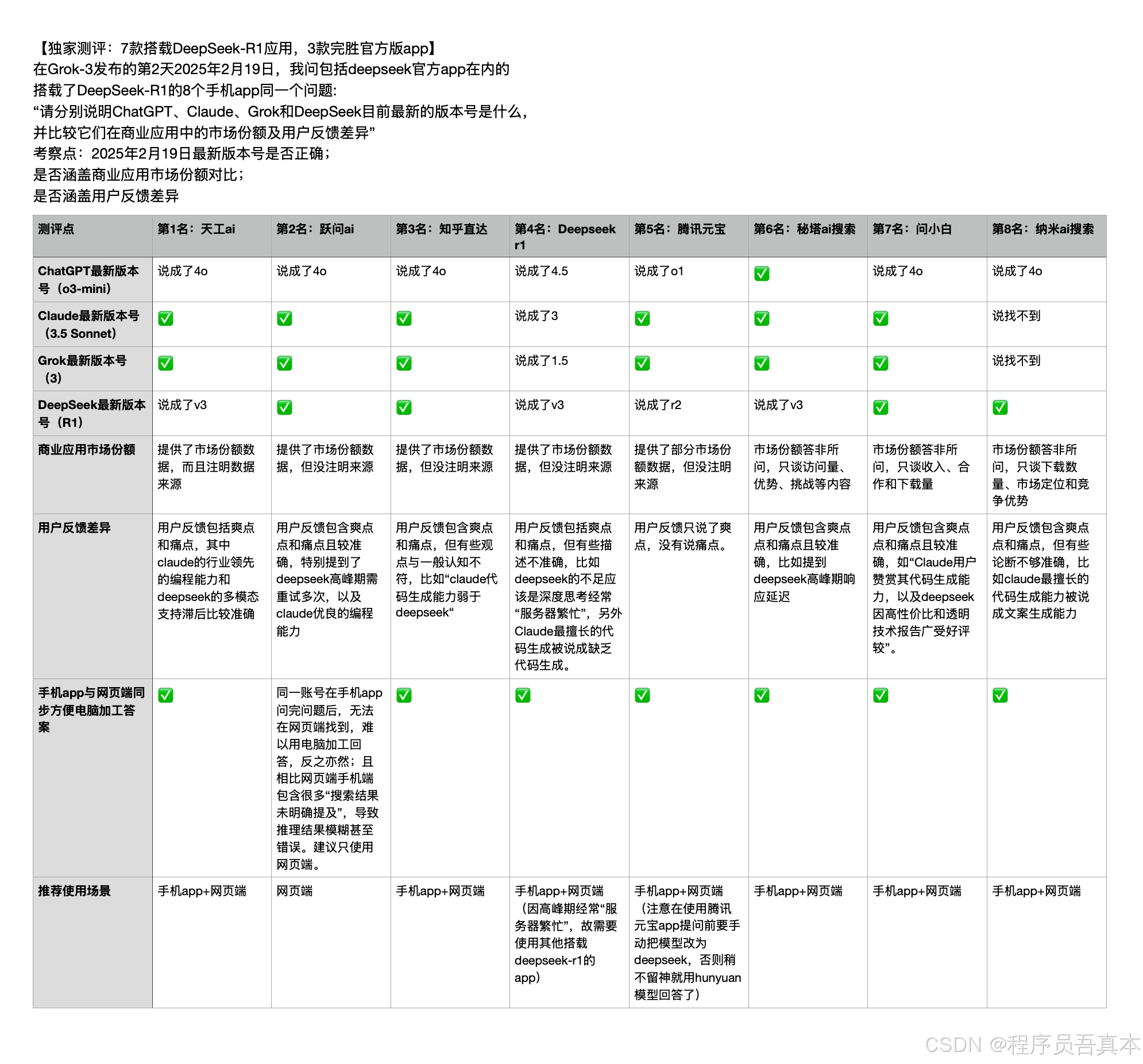
在Grok-3发布的第2天2025年2月19日,我问包括deepseek官方app在内的搭载了DeepSeek-R1的8个手机app同一个问题: “请分别说明ChatGPT、Claude、Grok和DeepSeek目前最新的版本号是什么,并比较它们在商业应用中的市场份额及用户反馈差异”,并同时打开深度思考和联网搜索这两个选项。这个问题既考验最新信息获取能力,又测试分析能力,非常适合评估应用的实际表现。
测试结果如下:
先看排名第4的DeepSeek官方app的表现。在2月19日的测试中,它对4个大模型的最新版本号全都回答错误,连自家产品的版本号都未能准确说明,反映出其获取最新信息的能力较弱(不过在2月24日的测试中有所进步,答对了3个,只有Grok不知道)。相比之下,其他7个应用在这方面都表现更好。deepseek官方app虽然提供了市场份额数据,但未注明数据来源。在用户反馈方面,内容虽然涵盖了爽点和痛点,但部分描述存在明显错误:它将DeepSeek的主要问题误描述为"长文本处理能力弱于ChatGPT",而实际上最大的问题是经常显示"服务器繁忙";同时还错误地声称Claude缺乏代码生成能力,而代码生成恰恰是Claude的强项。值得称赞的是,官方app的手机端与网页端同步功能做得很好,方便用户在电脑上加工答案。但遗憾的是,高峰期频繁出现的"服务器繁忙"问题几乎抵消了这些优势。
天工能够排名第一,主要优势在于不仅提供了市场份额数据,还标注了数据来源。
跃问位列第二,是因为它整体表现优秀:在4个大模型最新版本号中答对3个,提供了市场份额数据,且用户反馈全面准确。但它存在一个问题:同一账号在手机app提问后,无法在网页端查看历史记录,不便于用电脑整理回答内容,反之亦然。此外,相比网页端,手机端常出现"搜索结果未明确提及"的情况,导致推理结果不够清晰甚至出错。因此建议仅使用网页端。
知乎直达排名第三,主要是因为其用户反馈中有些观点与普遍认知不符,比如它认为"Claude的代码生成能力弱于DeepSeek"。
腾讯元宝排名第五,原因是它只提供了部分市场份额数据,且用户反馈仅着重爽点而忽略痛点,评价不够全面。特别提醒:使用腾讯元宝app前需手动选择DeepSeek模型,否则容易误用Hunyuan模型。
秘塔AI搜索排名第六,主要是因为其市场份额分析偏离主题,只谈及访问量、优势和挑战等周边内容。
问小白的表现与秘塔AI搜索相近,但排在第七位,是因为它缺少秘塔AI搜索提供的研究型内容搜索和分析功能。
纳米AI搜索排在第八,主要因为其搜索信息不够完整,无法找到Claude和Grok的最新版本号。市场份额分析也偏离主题,仅讨论下载量、市场定位和竞争优势。虽然提供了优缺点分析,但部分判断不够准确,如将Claude最擅长的代码生成能力误认为是文案生成能力。
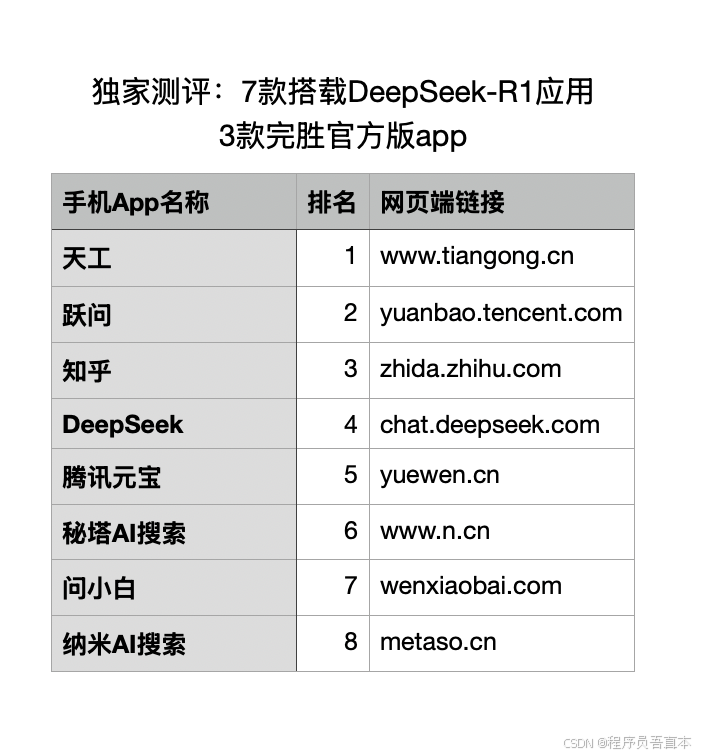
你可能想知道这8个App的网页端链接,以便用手机app问完问题后,在电脑上加工答案。以下是包括DeepSeek在内的8个搭载deepseek-r1的手机app的网页端地址,建议截图保存。

















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









