









目录
5.1.单源最短路径---Dijkstra算法(无法处理带负权边的图)
5.2.单源最短路径---Bellman_ford算法(可以处理带负权边的图)
实现代码:(该算法还有一个名叫SPFA的优化,感兴趣的读者可以去了解,下面的代码没有实现)
注意:第三,四,五部分的代码,结合 Design-in-cpp/design in cpp/Other data structures/Graph at main · wunianor/Design-in-cpp内的完整代码一起食用,效果更佳;文章内容较长,如有错误烦请指出,谢谢!!!
一.图的基本概念
1.1. 图的定义
图是由顶点(Vertex)集合和边(Edge)集合组成的一种数据结构,通常表示为,其中
是顶点的非空集合,
是边的集合,边是顶点的无序对(对于无向图)或有序对(对于有向图)。
例如,在一个社交网络中,人可以看作顶点,人与人之间的朋友关系可以看作边。
1.2. 树与图的关系
树是一种特殊的图。树是一个无向连通图,其中任意两个顶点间有且仅有一条路径。它没有回路,并且有条边,其中
是顶点的个数。
例如,家族族谱可以看作是一棵树,祖先为根节点,后代为叶子节点和中间节点。
1.3. 图的分类
按边的方向分为无向图和有向图。无向图中边没有方向,比如城市之间的公路连接(不考虑单行道),边和
是一样的。有向图中边是有方向的,例如网络中的网页链接,从网页A指向网页B的链接和从网页B指向网页A的链接是不同的概念。
按边的权重分为有权图和无权图。有权图的边带有一个数值权重,比如在地图中城市之间的距离;无权图的边没有权重,或者可以认为权重都为1。
1.4. 完全图
对于无向完全图,每对不同的顶点之间都有一条边相连。一个有个顶点的无向完全图有
条边。例如,在一个小组讨论中,如果每个人都要和其他所有人直接交流,这种关系可以用无向完全图来表示。
对于有向完全图,每对不同的顶点之间都有两条有向边(方向相反),有条边。
1.5. 邻接顶点
对于无向图,如果边属于边集
,那么顶点
和
互为邻接顶点。
在有向图中,如果存在有向边,那么称
是
的邻接顶点,
是
的前驱顶点。
例如,在一个城市交通图中,如果有一条路连接城市A和城市B,那么城市A和城市B就是邻接顶点。
1.6. 顶点的度
对于无向图,顶点的度是与它相关联的边的数目,记作
。例如,在一个简单的三角形形状的无向图中,每个顶点的度都是2。在无向图中,所有顶点的度之和等于边数的两倍。这是因为每条边会对两个顶点的度各贡献1。例如,一个有5条边的无向图,所有顶点度之和为10。
对于有向图,顶点的入度是指向
的边的数目,记作
;出度是从
出发的边的数目,记作
。顶点的度=入度+出度,即
。在有向图中,所有顶点的入度之和=所有顶点的出度之和=边的数目。因为每条边有一个起点(贡献出度)和一个终点(贡献入度)。
1.7. 路径与路径长度,简单路径与回路
路径:若从顶点u出发有一组边使其可以到达顶点v,则称顶点u到顶点v的顶点序列为从顶点u到顶点v的路径.
路径长度:对于无权图,一条路径的路径长度是指该路径上边的数量;对于有权图,一条路径的路径长度是指该路径上所有边的权重之和.
简单路径:若路径上各顶点v1,v2,...,vk均不重复,则称这样的路径为简单路径
回路(环):起点和终点相同的简单路径。
1.8. 子图
设是一个图,
也是一个图,如果
且
,则称
是
的子图。
例如,从一个国家的交通地图中选取一个省的交通地图,这个省的交通地图就是整个国家交通地图的子图。
1.9. 连通图与强连通图
在无向图中,如果任意两个顶点之间都存在一条路径,则称该图是连通图。
对于有向图,如果对于任意两个顶点和
,都存在从
到
的路径和从
到
的路径,则称该有向图是强连通图。
1.10. 生成树与最小生成树
生成树:对于连通图,生成树是
的一个子图,它是一棵树,包含
的所有顶点,且边的数目为
,其中
是顶点的数目。
例如,在一个电力网络中,要保证n个节点都能通电,且只使用n-1条电线连接,这些电线构成的图就是生成树。
最小生成树:对于有权连通图,最小生成树是一棵生成树,它的所有边的权重之和最小.一个图的最小生成树不唯一.
例如,在一个城市规划中,要在各个城市之间铺设通信电缆,使所有城市都能通信,并且总电缆长度最短,这个最短的电缆连接方案就是最小生成树。
1.11. 稀疏图和稠密图
稀疏图是指边的数目相对顶点数目较少的图,通常当(对于无向图)时认为是稀疏图。
稠密图是指边的数目相对顶点数目较多的图,接近完全图的情况可以看作是稠密图。
二.图的存储方式
2.1.邻接矩阵(第三,四,五节的内容都通过邻接矩阵实现)
定义:
邻接矩阵是表示图的一种常用方式。对于一个有个顶点的图
,它的邻接矩阵是一个
的矩阵
。
如果是无向图,那么当顶点
和顶点
之间有边相连时,
(或者是等于边的权值);如果顶点
和顶点
之间没有边相连,则
。
如果是有向图,当存在从顶点
到顶点
的有向边时,
(或者等于边的权值),否则
。
顶点自己到自己可以用
表示.
示例:
以一个简单的无向图为例,有顶点,边
.则它的邻接矩阵
为:
,这里
表示顶点
和
之间有边相连.
优点:
①.适合稠密图
②.时间复杂度判断两个顶点是否相连
缺点:
①.不适合稀疏图
②.不适合查找与一个顶点相连的所有边,需要的时间.
2.2.邻接表
定义:
邻接表是图的一种链式存储结构.对于图中的每个顶点
,都有一个链表,链表中的节点存储了与
相邻的顶点(和从
到其的权值).
在有向图中,从顶点出发的边对应的顶点(和边的权值)存储在
的邻接表中,这种邻接表也叫做出边表.入边表则存储到达
的边对应的顶点(和边的权值).
示例:
对于无向图,边
,它的邻接表可以表示为:
的邻接链表:节点
→节点
的邻接链表:节点
的邻接链表:节点
优点:
①.适合存储稀疏图
②.适合查找一个顶点连接出去(or连接进来)的边
缺点:
①.不适合确定两个顶点是否连接及其权值值
三.图的遍历
3.1.广度优先遍历(bfs)
与树的bfs遍历差不多.
从指定的顶点开始,通过队列实现bfs遍历.
队列中存储每个顶点的下标.
初始时,将指定的顶点push进队列.
然后每次取出队首元素i*,
将的邻接顶点(没有遍历过的)入队列,同时将这些点标记为已遍历*.
重复上述标*的过程,直到队列为空.
// _vertexs是一个一维vector,可以通过下标找到顶点
// _vertexs.size()为图中顶点的个数
// get_vertex_index()->获取一个顶点在_vertexs数组内的下标
// _matrix是一个二维vector,为图的邻接矩阵
//广度优先遍历
void bfs(const V& src)
{
size_t srci = get_vertex_index(src);//获取顶点的下标
queue<size_t> q;//队列中存储顶点的下标
unordered_set<size_t> visited;//存储顶点的下标,表示哪些顶点已经遍历
q.push(srci);
visited.insert(srci);
size_t level_count = 0;//记录当前遍历到第几层
size_t level_size = q.size();//记录当前层有多少个顶点
cout << "bfs:" << endl;
while (!q.empty())
{
level_size = q.size();
cout << " 第" << level_count << "层:";
while (level_size--)
{
size_t front = q.front();
q.pop();
cout << _vertexs[front] << " ";
for (size_t j = 0; j < _matrix[front].size(); ++j)
{
//如果_vertexs[front]顶点与_vertexs[j]有边连接 且 _vertexs[j]没有遍历过
if (_matrix[front][j] != MAX_W && visited.count(j) == 0)
{
q.push(j);
visited.insert(j);
}
}
}
++level_count;
cout << endl;
}
}3.2.深度优先遍历(dfs)
与树的dfs遍历差不多.
从指定的顶点开始,通过递归实现dfs遍历.
// _vertexs是一个一维vector,可以通过下标找到顶点
// _vertexs.size()为图中顶点的个数
// get_vertex_index()---获取一个顶点在_vertexs数组内的下标
// _matrix是一个二维vector,为图的邻接矩阵
//深度优先遍历
void dfs(const V& src)
{
size_t srci = get_vertex_index(src);
vector<bool> visited(_vertexs.size(),false);//将已经遍历的顶点进行标记
size_t depth = 0;//记录顶点的深度
cout << "dfs:\n ";
_dfs(srci, visited, depth);
}
//dfs子函数
void _dfs(size_t srci, vector<bool>& visited,size_t depth)
{
//访问当前结点并标记
cout << _vertexs[srci] << "(" << depth << ") ";
visited[srci] = true;
//寻找 与当前结点相邻并且未访问的点 访问
for (size_t j = 0; j < _matrix[srci].size(); ++j)
{
if (_matrix[srci][j] != MAX_W && visited[j] == false)
{
_dfs(j, visited, depth + 1);
}
}
}
四.图的最小生成树算法
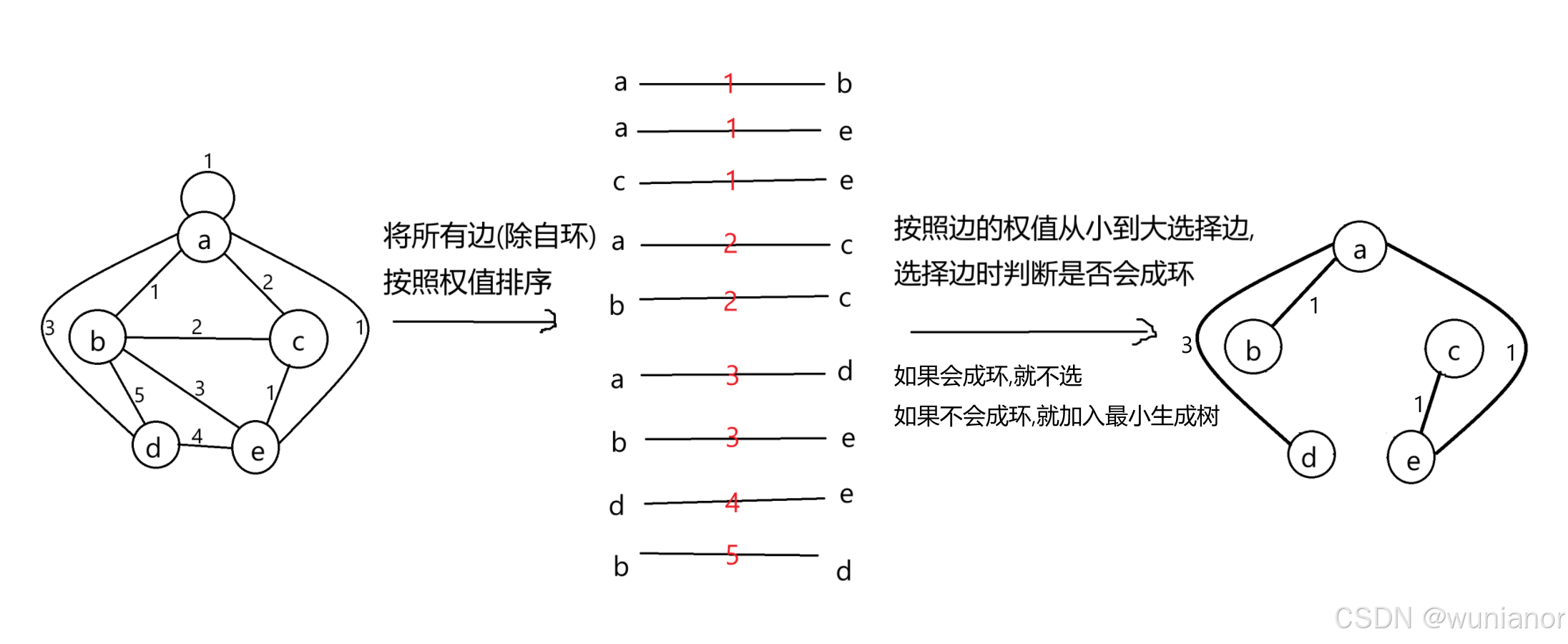
4.1.Kruskal算法
原理:
思想是贪心,
将图中所有的边(除掉自环)按照权值存储在小堆内,
从堆中依次取出每条边*,
如果这条边不会与之前选择过的边形成环,那么就将这条边加入到最小生成树中*;
如果会形成环,就抛弃*.
重复上述标*的过程,直到遍历完所有的边.
如果到最后最小生成树中有n-1条边(n为顶点个数),说明找到了这个图的最小生成树.
画图举例说明:
实现过程Q&A:
1.怎么将边存储到小堆内?
①.创建一个结构体,有边的起点下标,终点下标,权值三个成员变量.
②.重载>运算符,用于堆内比较两条边的权值
//内部类---边
struct Edge
{
size_t _srci;//边的起点的下标
size_t _desi;//边的终点的下标
W _w;//权值
//构造函数
Edge(size_t srci,size_t desi,const W& w):
_srci(srci),
_desi(desi),
_w(w)
{}
//用于排序(比较两条边的权值)
bool operator>(const Edge& b) const
{
return _w > b._w;
}
};2.怎么判断会不会成环?
①.使用并查集,判断当前取出来的边的两端是否在同一个集合.如果在一个集合,说明选择当前的边会成环.
②.每次选择某条边后,将这条边的两个顶点所在的集合进行合并.
实现代码:
// Self是typedef Graph<V, W, Direction, MAX_W>
// V是顶点的类型,
// W是边的权值的类型,
// Direction表示这个图是有向图还是无向图
// MAX_W作为两个顶点之间没有边的标识值
// _vertexs是一个一维vector,可以通过下标找到顶点
// _vertexs.size()为图中顶点的个数
// Edge是边类
// _matrix是一个二维vector,为图的邻接矩阵
// add_edge_by_index()函数---通过顶点的下标添加边
//最小生成树Kruskal算法(贪心+排序(堆)+并查集)
W kruskal(Self& min_tree,bool debug = false)
{
priority_queue<Edge, vector<Edge>, greater<Edge>> minpq;//小堆,按照边的权值来排序
//找到所有的边
for (size_t i = 0; i < _matrix.size(); ++i)
{
for (size_t j = (Direction == false ? i+1 : 0) ; j < _matrix[i].size(); ++j)
{
if (i == j) continue;//如果这条边的两个顶点是同一个顶点
if (_matrix[i][j] != MAX_W)
{
minpq.push(Edge(i,j,_matrix[i][j]));
}
}
}
size_t min_tree_edge_size = 0; //最小生成树的边的条数
W min_tree_total_w = W(); //最小生成树的总权值
UnionFindSet ufs(_vertexs.size()); //并查集,记录哪些点是一个集合的
//按照权值从小到大开始选边
while (!minpq.empty())
{
Edge edge = minpq.top();
minpq.pop();
//如果这条边的两个顶点不在一个集合中(即不会成环)
if (ufs.In_same_set(edge._srci, edge._desi) == false)
{
if (debug)//debug模式下打印选择的边
{
cout << "Selected Edge:" << _vertexs[edge._srci] << "->" << _vertexs[edge._desi] << "(w:" << edge._w << ")" << endl;
}
min_tree.add_edge_by_index(edge._srci, edge._desi, edge._w);//将这条边添加到最小生成树中
ufs.Union(edge._srci, edge._desi);//合并集合
min_tree_total_w += edge._w;
++min_tree_edge_size;
}
else if (debug)//debug模式下打印未选择的边
{
cout << "Unselected Edge:" << _vertexs[edge._srci] << "->" << _vertexs[edge._desi] << "(w:" << edge._w << ")" << endl;
}
}
//没找到最小生成树
if (min_tree_edge_size != _vertexs.size() - 1)
{
return W();
}
//找到了最小生成树
return min_tree_total_w;
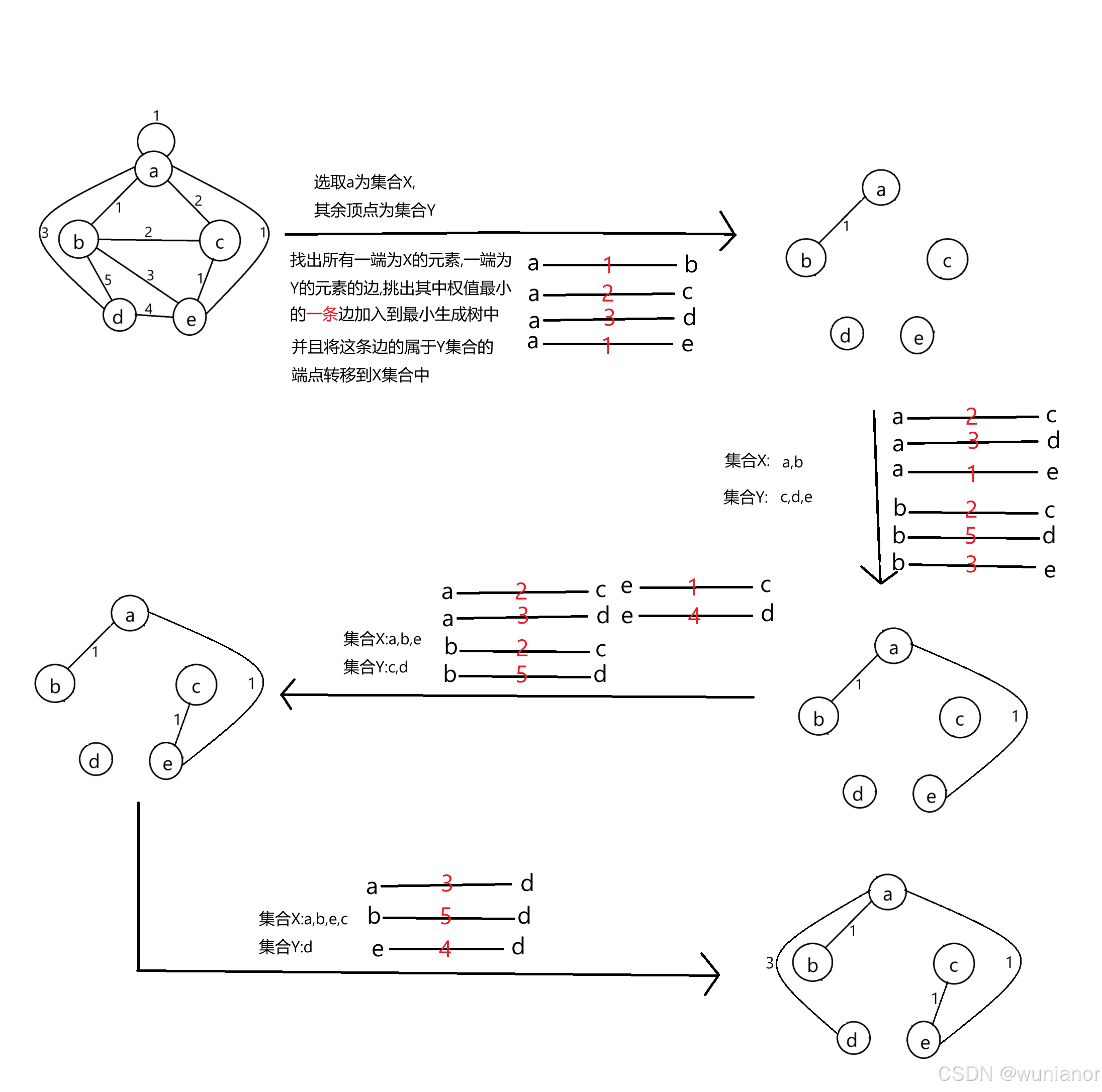
}4.2.Prim算法
原理:
思想是贪心,
定义两个集合X,Y,
集合X是已经在最小生成树内的顶点,
集合Y是还未加入最小生成树内的顶点,
初始时随便选取一个点(也可以在调用prim算法函数时传入一个点)在集合X内,其余点在集合Y内.
然后在所有一端是X的元素,一端是Y的元素的边内*,
找出权值最小的那条边*,
将这条边加入到最小生成树中*,
同时将这条边的那个在集合Y的顶点从集合Y移动到集合X内*.
重复上述标*的过程,直到遍历完所有能遍历的顶点.
如果最小生成树内有n-1条边(n为顶点个数),说明找到了这个图的最小生成树.
画图举例说明:
实现过程Q&A:
1.如何定义集合X和Y?
①.使用一个一维vector<bool>,每个下标对应一个顶点,如果该顶点在X集合内,标记为true;在Y集合内标记为false.
2.如何找到所有一端是X的元素,一端是Y的元素的边,并且找出权值最小的那条边?
①.当一个顶点加入X集合时,将一端为它,一端为Y集合的元素的所有边加入到小堆(按照边的权值比较)中(这一步小堆的代码可以参考Kruskal算法的实现过程部分)
②.从小堆中取出边时,需要判断这条边的一端是否在X集合内,一端是否在Y集合内.如果是,就将这条边加入到小堆中,否则从小堆中取下一条边.
实现代码:
//最小生成树prim算法
// Self是typedef Graph<V, W, Direction, MAX_W>
// V是顶点的类型,
// W是边的权值的类型,
// Direction表示这个图是有向图还是无向图
// MAX_W作为两个顶点之间没有边的标识值
// _vertexs是一个一维vector,可以通过下标找到顶点
// _vertexs.size()为图中顶点的个数
// Edge是边类
// _matrix是一个二维vector,为图的邻接矩阵
// add_edge_by_index()函数---通过顶点的下标添加边
// get_vertex_index()函数---获取一个顶点在_vertexs数组内的下标
W prim(Self& min_tree,const V& src,bool debug = false)
{
size_t srci = get_vertex_index(src);
vector<bool> X(_vertexs.size(),false); //已经加入最小生成树的顶点 在X中标记为true,否则为false
X[srci] = true;
W min_tree_total_w = W(); //最小生成树的总权
size_t min_tree_edge_size = 0;//当前最小生成树边的数量
priority_queue<Edge, vector<Edge>, greater<Edge>> minpq;//小堆,存边
//将起点为src,终点为X中被标记成false的顶点 的边push进小堆
for (size_t j = 0; j < _matrix[srci].size(); ++j)
{
if (_matrix[srci][j] != MAX_W && X[j] == false)
{
minpq.push(Edge(srci, j, _matrix[srci][j]));
}
}
while (!minpq.empty())
{
Edge min_edge = minpq.top();
minpq.pop();
//判断是否会成环
//(取出的边的起点是否已加入最小生成树(标记成true),终点是否没有加入最小生成树(标记为false))
if (X[min_edge._srci] == true && X[min_edge._desi] == false)
{
min_tree.add_edge_by_index(min_edge._srci, min_edge._desi, min_edge._w);
min_tree_total_w += min_edge._w;
++min_tree_edge_size;
if (debug)//debug模式下打印选择的边
{
cout << "Selected Edge:" << _vertexs[min_edge._srci] << "->" << _vertexs[min_edge._desi] << "(w:" << min_edge._w << ")" << endl;
}
X[min_edge._desi] = true;//将min_edge._desi标记成true(已加入最小生成树)
//将起点为min_edge._desi,终点为在X被标识成false的顶点 的边push进小堆
for (size_t j = 0; j < _matrix[min_edge._desi].size(); ++j)
{
if (_matrix[min_edge._desi][j] != MAX_W && X[j] == false)
{
minpq.push(Edge(min_edge._desi, j, _matrix[min_edge._desi][j]));
}
}
}
else if (debug)//debug模式下打印未选择的边
{
cout << "Unselected Edge:" << _vertexs[min_edge._srci] << "->" << _vertexs[min_edge._desi] << "(w:" << min_edge._w << ")" << endl;
}
}
//如果最小生成树的边不是 顶点数-1 条
if (min_tree_edge_size != _vertexs.size() - 1)
{
return W();
}
return min_tree_total_w;
}
五.图的最短路径算法
单源最短路径指求从一个点出发,到达其他点的最短路径
多源最短路径指求任意两点之间的最短路径
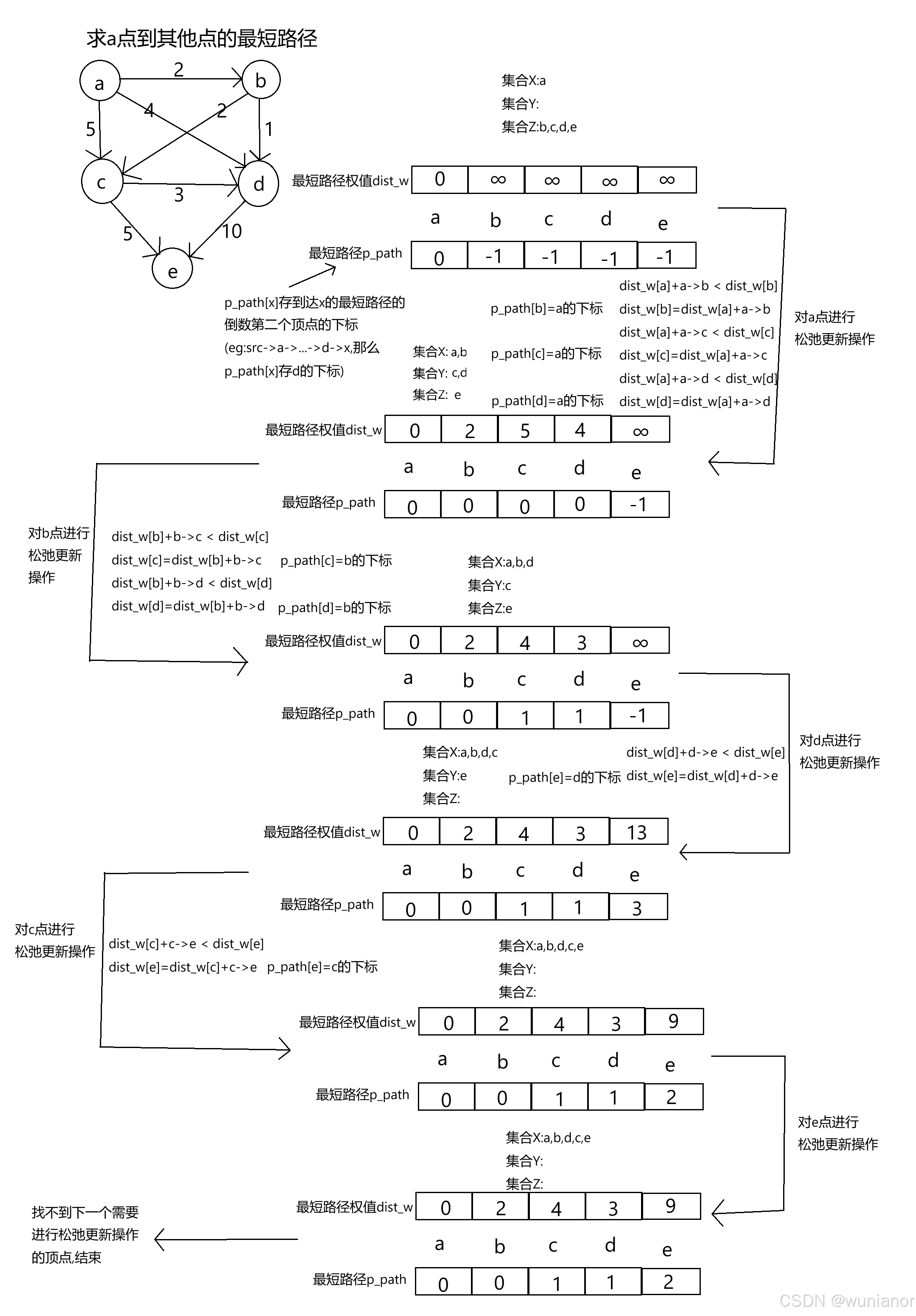
5.1.单源最短路径---Dijkstra算法(无法处理带负权边的图)
原理:
思想是贪心,只能处理不带负权边的图,
将图中的所有顶点分为三个集合,
分别为已经确定最短路径的顶点的集合X,没有确定最短路径但确定可以到达的顶点集合Y,暂未确定可以到达的顶点集合Z,
初始时,起始顶点(src)在集合X内,其他顶点在集合Z内;并且使用一个一维vector数组dist_w,用于存储src到每个点的最短路径权值,数组dist_w内的值全部初始化成不可达的标识值,然后dist_w[src的下标]=0;再设置一个cur变量,cur=起始顶点的下标.
随后对cur指向的点进行松弛更新操作*,
即更新与cur指向的点相邻且不在X集合内的所有顶点的最短路径权值(被更新最短路径的顶点可以认为在Y集合内)*,
更新完后,找到Y集合内最短路径权值最小的那个点,将这个点转移到集合X内,同时让cur=这个点的下标,作为下一次进行松弛更新的顶点*.
重复上述标*的操作,直到找不到下一次能进行松弛更新的顶点为止(此时,已经更新完所有src能到达的顶点的最短路径权值).
在上述操作中,还可以增加一个一维数组p_path,存储从src到这个点的最短路径(eg:src->a->b->c->destination)中倒数第二个顶点的下标(如示例中的c的下标).在算法运行的过程中不断地维护p_path数组.
画图举例说明:
实现过程Q&A:
1.真的需要实现上述的X,Y,Z三个集合吗?如果不需要,我怎么确定某个顶点是否确定了最短路径?
不需要真的实现上述的X,Y,Z三个集合(这三个集合只是为了便于理解);只需要用一个一维bool数组即可,确定了最短路径的顶点标记为true,否则即为false.
2.怎么对cur指向的点进行松弛更新操作?
对于与cur指向的点相邻且未在X集合内的顶点V_i,
如果dist_w[V_i]=不可达的标识值 或者 dist_w[cur]+cur与V_i相连的边的权值<dist_w[V_i],
就更新dist_w[V_i].
实现代码:
(如果图是用邻接表存储的,可以使用堆对寻找下一个进行松弛操作的顶点的过程进行优化)
/*
最短路径Dijkstra算法--->时间复杂度:O(n^2),空间复杂度O(n),其中n为顶点个数
思想是贪心
dist_w存src到各个点的最短路径的权值
p_path存从src到这个点的最短路径(eg:src->a->b->c->destination)中倒数第二个顶点的下标(如示例中的c的下标),
p_path可以倒推从src到各个点的最短路径
V为顶点的类型,
W为边的权值的类型,
MAX_W作为两个顶点之间没有边(or不能到达)的标识值
get_vertex_index()函数---获取一个顶点在_vertexs数组内的下标
_vertexs是一个一维vector,可以通过下标找到顶点
_vertexs.size()为图中顶点的个数
_matrix是一个二维vector,为图的邻接矩阵
*/
void dijkstra(const V& src, vector<W>& dist_w, vector<size_t>& p_path)
{
dist_w.resize(_vertexs.size(), MAX_W);
p_path.resize(_vertexs.size(), -1);
vector<bool> hash(_vertexs.size(), false);//最短路径已经确定的顶点标记为true,否则为false
size_t srci = get_vertex_index(src);
dist_w[srci] = W();
p_path[srci] = srci;
hash[srci] = true;
size_t cur = srci;//当前要进行松弛更新的点
while (true)
{
//松弛更新操作
for (size_t j = 0; j < _matrix[cur].size(); ++j)
{
if (_matrix[cur][j] != MAX_W && //如果cur顶点能到j顶点(cur顶点和j顶点之间有边连接)
hash[j] == false && //并且 src->j顶点的最短路径还没有确定
(dist_w[j]==MAX_W || dist_w[cur]+_matrix[cur][j] < dist_w[j]))//并且 到j顶点的权值为MAX_W or src->cur + cur->j < src->j
{
dist_w[j] = dist_w[cur] + _matrix[cur][j];
p_path[j] = cur;
}
}
//寻找被hash标记为false 且 到达它的权值最小的顶点,用于迭代cur
size_t next = -1;//下一个要进行松弛更新的点
for (size_t i = 0; i < _vertexs.size(); ++i)
{
if (hash[i] == false && //如果i顶点标记为false,
dist_w[i] != MAX_W && //并且目前判断src能到i顶点,
(next == -1 || dist_w[i] < dist_w[next])) //并且next顶点不存在 or 到达i顶点的权值小于到达next顶点的权值
{
next = i;
}
}
if (next != -1)//如果找到了,迭代cur,并在hash中将cur指向的顶点标记为true
{
cur = next;
hash[cur] = true;
}
else //如果没找到,说明src到所有点(可到达的点)的最短路径已经更新完毕
{
break;
}
}
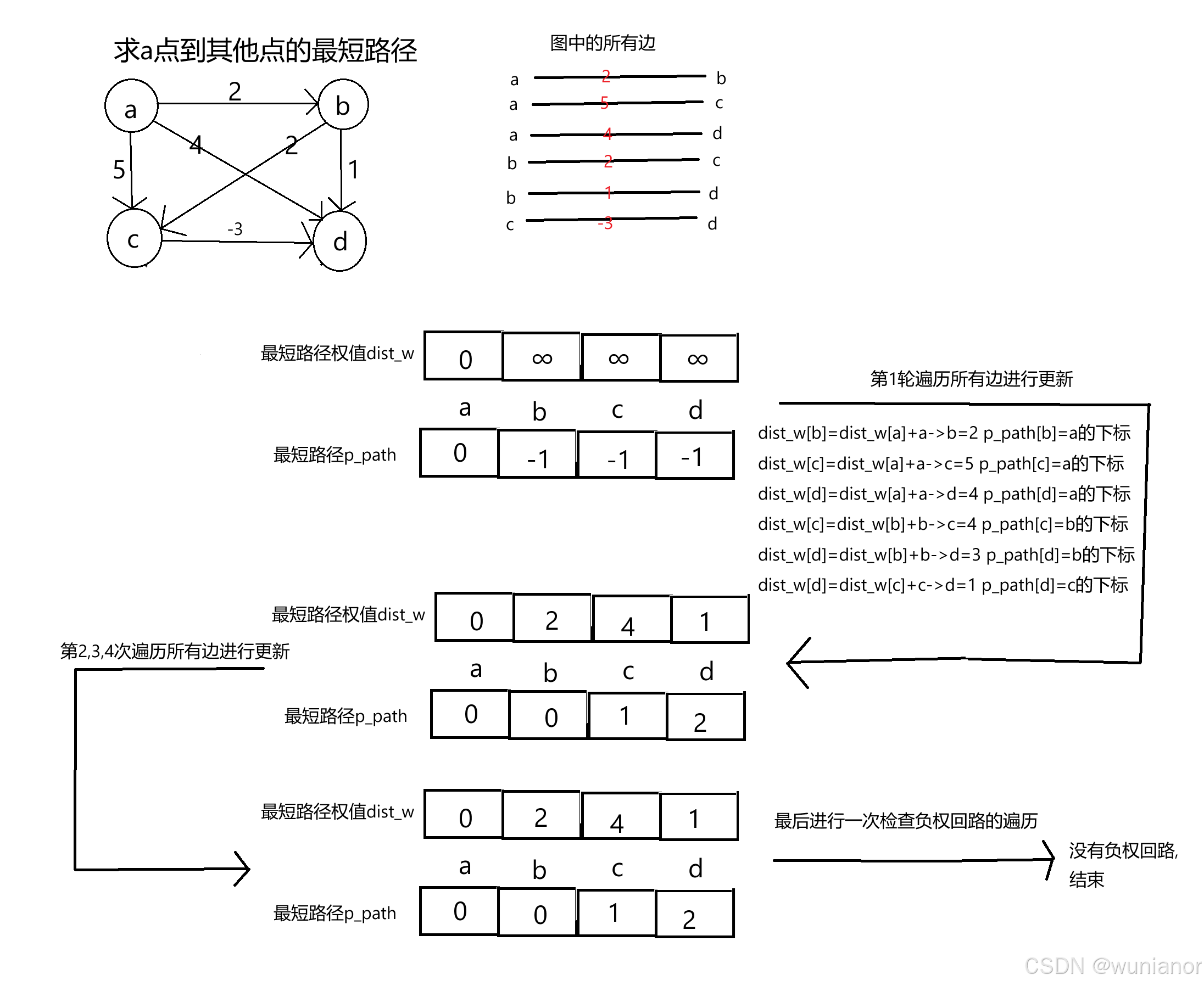
}5.2.单源最短路径---Bellman_ford算法(可以处理带负权边的图)
原理:
思想是暴力,可以处理带负权边的图,可以判断图中是否有负权回路(回路上所有边的权值和为负数),
用一维数组dist_w存储起始顶点src到每个顶点的最短路径权值,dist_w数组内所有元素全部初始化为不可达的标识值,然后dist_w[起始顶点src的下标]=0
用一维数组p_path存储从src到这个点的最短路径(eg:src->a->b->c->destination)中倒数第二个顶点的下标(如示例中的c的下标),p_path数组内所有元素全部初始化为-1,然后p_path[起始顶点src的下标]=起始顶点src的下标
对所有边进行n轮遍历(n为顶点的个数),
在每一轮中,如果顶点与顶点
有边相连,且dist_w[
]=不可达标识值 or dist_w[
]+
<dist_w[
],就更新dist_w[
]=dist_w[
]+
.
最后再进行一轮遍历,如果发现还能更新,说明有负权回路.
画图举例说明:
实现代码:(该算法还有一个名叫SPFA的优化,感兴趣的读者可以去了解,下面的代码没有实现)
//bellman_ford算法
//思想是暴力
//可以求带负权图的最短路径问题,可以检测负权回路
//时间复杂度O(n^3),空间复杂度O(n)
// V为顶点的类型,
// W为边的权值的类型,
// MAX_W作为两个顶点之间没有边(or不能到达)的标识值
// get_vertex_index()函数---获取一个顶点在_vertexs数组内的下标
// _vertexs是一个一维vector,可以通过下标找到顶点
// _vertexs.size()为图中顶点的个数
// _matrix是一个二维vector,为图的邻接矩阵
bool bellman_ford(const V & src, vector<W>&dist_w, vector<size_t>&p_path)
{
dist_w.resize(_vertexs.size(), MAX_W);
p_path.resize(_vertexs.size(), -1);
//初始化dist_w[srci]和p_path[srci]
size_t srci = get_vertex_index(src);
dist_w[srci] = W();
p_path[srci] = srci;
//进行n轮更新(src到某一个点最多经过n-2个点)
//第n+1轮(round==_vertexs.size())是用来检测是否存在负权回路
for (size_t round = 0; round <= _vertexs.size(); ++round)
{
bool update = false;//检查是否进行了松弛更新
//每一轮找到邻接矩阵中的所有边,对src到所有点的最短路径进行更新
for (size_t i = 0; i < _matrix.size(); ++i)
{
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
if (_matrix[i][j] != MAX_W && //如果i可以到j,
(dist_w[j] == MAX_W || //并且 distw[j]等于标识值(代表不可到达)
dist_w[i] + _matrix[i][j] < dist_w[j])) // 或者 src->i + i->j < src->j
{ //进行松弛更新
update = true;
dist_w[j] = dist_w[i] + _matrix[i][j];
p_path[j] = i;
}
}
}
//如果没更新,break
if (update == false)
{
break;
}
//如果第n+1轮进行了松弛更新,说明存在负权回路,返回false
if (round == _vertexs.size() && update == true)
{
return false;
}
}
return true;
}5.3.多源最短路径---Floyd_warshall算法
原理:
原理是动态规划,下图是它的定义(摘自OI-wiki).

下面说说我的理解:
假设顶点到顶点
有路径,那么先初始化成这样:
,
随后遍历图中剩余的n-2个顶点(n为顶底个数),对于剩余n-2个顶点中的每个顶点:
如果通过
到
的路径权值 < 当前
不通过
到
的路径权值,即
,
就将加入
到
的路径中,即
对图中的任意两点进行该操作,即可得到任意两点的最短路径.
实现代码:
//floyd_warshall算法(多源最短路径)
//求任意两个点之间的最短路径
//原理是动态规划
//dist_i_j存i到j点的最短路径的权值
//p_path_i_j存i->j的最短路径(eg:i->a->b->c->j)上 j的上一个顶点的下标(例子中是c的下标)
// V为顶点的类型,
// W为边的权值的类型,
// MAX_W作为两个顶点之间没有边(or不能到达)的标识值
// get_vertex_index()函数---获取一个顶点在_vertexs数组内的下标
// _vertexs是一个一维vector,可以通过下标找到顶点
// _vertexs.size()为图中顶点的个数
// _matrix是一个二维vector,为图的邻接矩阵
void floyd_warshall(vector<vector<W>>& dist_i_j,vector<vector<size_t>>& p_path_i_j,bool debug = false)
{
//初始化dist_i_j和p_path_i_j
dist_i_j.resize(_vertexs.size());
p_path_i_j.resize(_vertexs.size());
for (size_t i = 0; i < _vertexs.size(); ++i)
{
dist_i_j[i].resize(_vertexs.size(), MAX_W);
dist_i_j[i][i] = W();
p_path_i_j[i].resize(_vertexs.size(), -1);
p_path_i_j[i][i] = i;
}
//将邻接矩阵中的所有边先添加到dist_i_j内
for (size_t i = 0; i < _matrix.size(); ++i)
{
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
if (_matrix[i][j] != MAX_W)
{
dist_i_j[i][j] = _matrix[i][j];
p_path_i_j[i][j] = i;
}
}
}
//核心内容
for (size_t k = 0; k < _vertexs.size(); ++k)
{
for (size_t i = 0; i < _vertexs.size(); ++i)
{
for (size_t j = 0; j < _vertexs.size(); ++j)
{
if (dist_i_j[i][k] != MAX_W && //如果顶点i可以到顶点k
dist_i_j[k][j] != MAX_W && //并且顶点k可以到顶点j
dist_i_j[i][k] + dist_i_j[k][j] < dist_i_j[i][j]) //并且i->k + k->j < i->j
{
dist_i_j[i][j] = dist_i_j[i][k] + dist_i_j[k][j];
p_path_i_j[i][j] = p_path_i_j[k][j];
}
}
}
if (debug)//在debug模式下
{
// 打印权值观察数据
for (size_t i = 0; i < dist_i_j.size(); ++i)
{
for (size_t j = 0; j < dist_i_j[i].size(); ++j)
{
if (dist_i_j[i][j] == MAX_W)
{
cout << setw(5) << "*";
//printf("%4c", '*');
}
else
{
cout << setw(5) << dist_i_j[i][j];
//printf("%4d", dist_i_j[i][j]);
}
/*cout << " path:";
vector<V> path_i_j;
size_t parent = j;
while (parent != i)
{
path_i_j.push_back(_vertexs[parent]);
parent = p_path_i_j[i][parent];
}
path_i_j.push_back(_vertexs[i]);
reverse(path_i_j.begin(), path_i_j.end());
for (auto& vertex : path_i_j)
{
if (vertex != _vertexs[j])
{
cout << vertex << "->";
}
else
{
cout << vertex << endl;
}
}*/
}
cout << endl;
}
cout << "---------------------------------------------" << endl;
}
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









