







一.设计题目
基于优先级队列和并查集改进的求最小生成树的Kruskal算法。
二.主要内容
本实验主要实现了通过使用优先级队列(小堆)来存储边,然后使用树形结构的并查集(使用了路径压缩和按秩合并的优化)求解图的最小生成树的Kruskal算法。这种改进后的算法在处理边的选择和避免环的形成方面更加高效,时间复杂度在一般情况下为O(V^2logE+ElogE),在稀疏图中可以近似为O(ElogE),其中V是图中的顶点数,E是图中的边数。
三.课题设计的基本思想,原理和算法描述
(一)基本思想
贪心思想
Kruskal算法的核心思想是贪心策略。它总是选择当前权重最小的边,只要这条边不会与已经选择的边形成环。
优先级队列(小堆)的作用
用于存储图中的所有边(除去环),并按照边的权重进行排序。这样可以方便地获取权重最小的边,每次从队列中取出的都是当前未处理边中权重最小的边。
并查集的作用
并查集用于判断两条边的顶点是否在同一个集合中。在选择边的过程中,如果一条边的两个顶点不在同一个集合中,那么选择这条边不会形成环,可以将这条边加入最小生成树中,并且将这两个顶点所在的集合合并。
(二)原理
最小生成树原理
对于一个连通无向图,最小生成树是一棵包含图中所有顶点且边的权重之和最小的树。
Kruskal算法原理
首先将图中所有边(除去环)按照权重从小到大排序,然后依次选择边。在选择每条边时,使用并查集判断这条边的两个顶点是否在同一个集合中。如果不在同一个集合中,则选择这条边加入最小生成树,并合并这两个顶点所在的集合;如果在同一个集合中,则不选择这条边,因为选择它会形成环。
并查集原理
并查集是一种处理不相交集合合并与查询问题的数据结构。在Kruskal算法中,每个顶点最初都在自己的集合中。当选择一条边时,如果这条边的两个顶点所在的集合不同,则将这两个集合合并。通过不断合并集合,最终形成一个包含所有顶点的集合,这个集合对应的树就是最小生成树。
(三)算法描述
边的存储与排序
使用优先级队列(小堆)来存储图中的所有边(除去环)。通过遍历图的邻接矩阵_matrix,将所有非自环且权重不为标识值MAX_W的边加入优先级队列。这样,取出边时,优先级队列中的边将会按照权重从小到大的顺序取出。
最小生成树构建过程
初始化最小生成树的边数min_tree_edge_size为0,总权重min_tree_total_w为初始值W(),并创建一个并查集ufs,其大小为图中顶点的个数_vertexs.size()。
然后,只要优先级队列不为空,就取出队列顶部权重最小的边edge。使用并查集判断这条边的两个顶点edge.srci和edge.desi是否在同一个集合中。如果不在同一个集合中:
在调试模式(debug为true)下,打印选择的边的信息,包括边连接的两个顶点和边的权重。
将这条边加入最小生成树min_tree
使用并查集的Union方法合并这两个顶点所在的集合。
更新最小生成树的总权重min_tree_total_w和边数min_tree_edge_size。
如果这两个顶点在同一个集合中,并且处于调试模式,则打印未选择的边的信息。
结果判断
最后,检查最小生成树的边数是否等于顶点数减1。如果相等,则说明成功构建了最小生成树,返回最小生成树的总权重min_tree_total_w;否则,返回默认的W类型,表示未成功构建最小生成树。
四. 源程序及注释
(一)并查集类UnionFindSet
#pragma once
#include <vector>
using namespace std;
//并查集(树型结构)
//_ufs内的所有值初始默认为-1,
// 如果一个下标对应的值是负数,说明这个下标是一棵树的根,树的大小为这个负数的绝对值;
// 如果一个下标对应的值是非负数,说明这个下标的父亲是它对应的数(也是_ufs内的下标)
class UnionFindSet
{
vector<int> _ufs;
public:
//构造函数
UnionFindSet(size_t n) :
_ufs(n, -1)
{}
//寻找给定编号x的根
int Find_root(int x)
{
int root = x;
while (_ufs[root] >= 0)
{
root = _ufs[root];
}
//路径压缩(优化)
while (_ufs[x] >= 0)//如果x不为根,进行路径压缩,压缩从x到根的所有结点(不包括根)的路径
{
int parent = _ufs[x];
_ufs[x] = root;
x = parent;
}
return root;
}
//合并两个集合(树)---时间复杂度为O(α(n)),其中α为阿克曼函数的反函数,其增长极其缓慢,可以近似认为是O(1)
void Union(int x1, int x2)
{
int root1 = Find_root(x1);
int root2 = Find_root(x2);
//如果x1和x2在同一个集合,不需要合并,直接return
if (root1 == root2)
{
return;
}
//如果root1的集合数据量小于root2集合的数据量
//(按秩合并(启发式合并)优化:数据量小的往数据量大的合并)
if (abs(_ufs[root1]) < abs(_ufs[root2]))
{
swap(root1, root2);
}
//数据量小的集合往数据量大的集合合并
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
}
//判断x1和x2是否在同一个集合---时间复杂度为O(α(n)),其中α为阿克曼函数的反函数,其增长极其缓慢,可以近似认为是O(1)
bool In_same_set(int x1, int x2)
{
return Find_root(x1) == Find_root(x2);
}
//获取并查集中有多少个集合(树)
size_t Set_count()
{
size_t count = 0;
for (auto& e : _ufs)
{
if (e < 0)
{
++count;
}
}
return count;
}
};(二)图类Graph---包含Kruskal算法
#pragma once
#include <vector>
#include <unordered_map>
#include <queue>
#include <string>
#include <functional>
#include <iostream>
#include "UnionFindSet.h"
using namespace std;
//V是顶点的类型,
//W是边(权重)的类型,
//Direction为false表示无向图,
//从一个点不能到另一个点时使用MAX_W作为标识值
template<class V, class W, bool Direction = false, W MAX_W = INT_MAX>
class Graph
{
typedef Graph<V, W, Direction, MAX_W> Self;
vector<V> _vertexs; //顶点集合
unordered_map<V, int> _index_map; //顶点映射下标
vector<vector<W>> _matrix; //邻接矩阵
public:
//内部类边
struct Edge
{
size_t _srci;//边的起点的下标
size_t _desi;//边的终点的下标
W _w;//权值
Edge(size_t srci, size_t desi, const W& w) :
_srci(srci),
_desi(desi),
_w(w)
{
}
//用于排序
bool operator>(const Edge& b) const
{
return _w > b._w;
}
};
//图的创建:
//1.IO输入,适合OJ题,不适合测试
//2.图结构关系写到文件,读取文件
//3.手动添加边
Graph(const V* a, size_t n)
{
_vertexs.reserve(n);
for (size_t i = 0; i < n; ++i)
{
_vertexs.push_back(a[i]);
_index_map[a[i]] = i;
}
_matrix.resize(n);
for (size_t i = 0; i < n; ++i)
{
_matrix[i].resize(n, MAX_W);
}
}
//获取顶点的下标
size_t get_vertex_index(const V& vertex)
{
auto it = _index_map.find(vertex);
if (it != _index_map.end())
{
return it->second;
}
else
{
throw invalid_argument("顶点不存在");//抛异常
return -1;
}
}
//通过下标添加边
void add_edge_by_index(size_t srci, size_t desi, const W& w)
{
_matrix[srci][desi] = w;
if (Direction == false)//无向图
{
_matrix[desi][srci] = w;
}
}
//添加边
void add_edge(const V& src, const V& des, const W& w)
{
size_t srci = get_vertex_index(src);
size_t desi = get_vertex_index(des);
add_edge_by_index(srci, desi, w);
}
//最小生成树Kruskal算法(贪心+排序(堆)+并查集)
W kruskal(Self& min_tree, bool debug = false)
{
priority_queue<Edge, vector<Edge>, greater<Edge>> minpq;//小堆,按照边的权值来排序
//找到所有的边(除去环)
for (size_t i = 0; i < _matrix.size(); ++i)
{
for (size_t j = (Direction == false ? i + 1 : 0); j < _matrix[i].size(); ++j)
{
if (i == j) continue;//如果这条边的两个顶点是同一个顶点
if (_matrix[i][j] != MAX_W)
{
minpq.push(Edge(i, j, _matrix[i][j]));
}
}
}
size_t min_tree_edge_size = 0; //最小生成树的边的条数
W min_tree_total_w = W(); //最小生成树的总权值
UnionFindSet ufs(_vertexs.size()); //并查集,记录哪些点是一个集合的
//按照权值从小到大开始选边
while (!minpq.empty())
{
Edge edge = minpq.top();
minpq.pop();
//如果这条边的两个顶点不在一个集合中(即不会成环)
if (ufs.In_same_set(edge._srci, edge._desi) == false)
{
if (debug)//debug模式下打印选择的边
{
cout << "Selected Edge:" << _vertexs[edge._srci] << "->" << _vertexs[edge._desi] << "(w:" << edge._w << ")" << endl;
}
min_tree.add_edge_by_index(edge._srci, edge._desi, edge._w);
ufs.Union(edge._srci, edge._desi);//合并集合
min_tree_total_w += edge._w;
++min_tree_edge_size;
}
else if (debug)//debug模式下打印未选择的边
{
cout << "Unselected Edge:" << _vertexs[edge._srci] << "->" << _vertexs[edge._desi] << "(w:" << edge._w << ")" << endl;
}
}
//没找到最小生成树
if (min_tree_edge_size != _vertexs.size() - 1)
{
return W();
}
//找到了最小生成树
return min_tree_total_w;
}
//打印邻接矩阵
void print()
{
// 顶点
for (size_t i = 0; i < _vertexs.size(); ++i)
{
cout << "[" << i << "]->" << _vertexs[i] << endl;
}
cout << endl;
// 矩阵
// 横下标
cout << " ";
for (size_t i = 0; i < _vertexs.size(); ++i)
{
//cout << i << " ";
printf("%4d", i);
}
cout << endl;
for (size_t i = 0; i < _matrix.size(); ++i)
{
cout << i << " "; // 竖下标
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
//cout << _matrix[i][j] << " ";
if (_matrix[i][j] == MAX_W)
{
//cout << "* ";
printf("%4c", '*');
}
else
{
//cout << _matrix[i][j] << " ";
printf("%4d", _matrix[i][j]);
}
}
cout << endl;
}
cout << endl;
}
};
五.运行示例及结果分析
(一)运行示例
测试程序:
#include "Graph.h"
#include "UnionFindSet.h"
#include <iostream>
//测试函数
void TestGraphMinTree()
{
//测试无向图1
const char* str = "abcde";//无向图1和无向图2的顶点元素
Graph<char, int> g1(str, strlen(str));//无向图1
g1.add_edge('a', 'b', 1);//向无向图1添加边,下同
g1.add_edge('a', 'c', 2);
g1.add_edge('a', 'd', 3);
g1.add_edge('a', 'e', 1);
g1.add_edge('b', 'c', 2);
g1.add_edge('b', 'd', 5);
g1.add_edge('b', 'e', 3);
g1.add_edge('c', 'e', 1);
g1.add_edge('d', 'e', 4);
Graph<char, int> kminTree1(str, strlen(str));//最小生成树1
cout << "KminTree1_w:" << g1.kruskal(kminTree1, true) << endl;//打印最小生成树1的总权值
kminTree1.print();//打印最小生成树1的邻接矩阵
//测试无向图2
Graph<char, int> g2(str, strlen(str));//无向图2
g2.add_edge('a', 'a', 1);//向无向图2添加边,下同
g2.add_edge('a', 'b', 5);
g2.add_edge('a', 'd', 3);
g2.add_edge('a', 'e', 2);
g2.add_edge('b', 'c', 7);
g2.add_edge('b', 'e', 6);
g2.add_edge('c', 'e', 4);
g2.add_edge('d', 'e', 1);
Graph<char, int> kminTree2(str, strlen(str));//最小生成树2
cout << "KminTree2_w:" << g2.kruskal(kminTree2, true) << endl;//打印最小生成树2的总权值
kminTree2.print();//打印最小生成树2的邻接矩阵
//测试无向图3
char vexs[] = { 'A', 'B', 'C', 'D' };//无向图3的顶点元素
int m[4][4] = {//无向图3的邻接矩阵
{0, 2, 3, 4},
{2, 0, 5, 6},
{3, 5, 0, 7},
{4, 6, 7, 0}
};
Graph<char, int> g3(vexs, 4);//无向图3
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < i; ++j) {
if (m[i][j] != 0) {
g3.add_edge(vexs[i], vexs[j], m[i][j]);
}
}
}
Graph<char, int> kminTree3(vexs, 4);//最小生成树3
cout << "KminTree3_w:" << g3.kruskal(kminTree3, true) << endl;//打印最小生成树3的总权值
kminTree3.print();//打印最小生成树3的邻接矩阵
}
int main()
{
TestGraphMinTree();
return 0;
}上述测试程序用到的测试无向图1,2,3及其预期的最小生成树,如下图1所示。
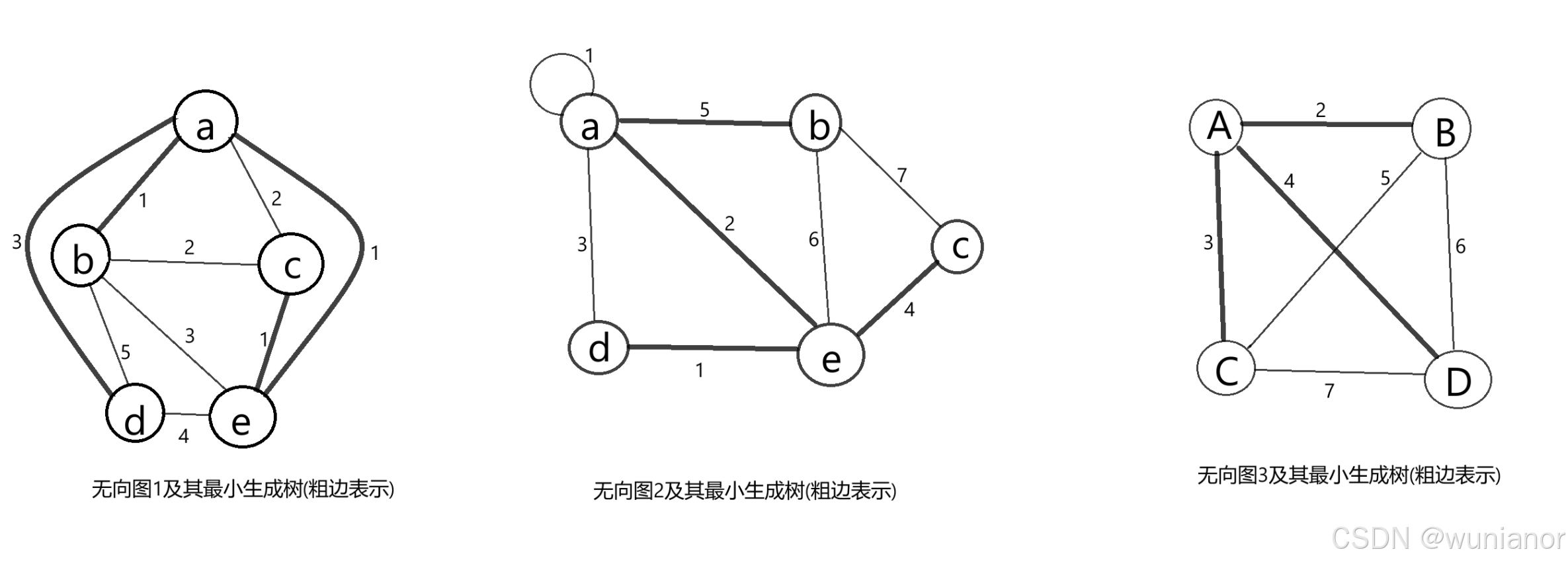
图1 无向图1,2,3及其预期的最小生成树
运行上述测试程序,结果如图2,3,4所示,与预期结果相同。
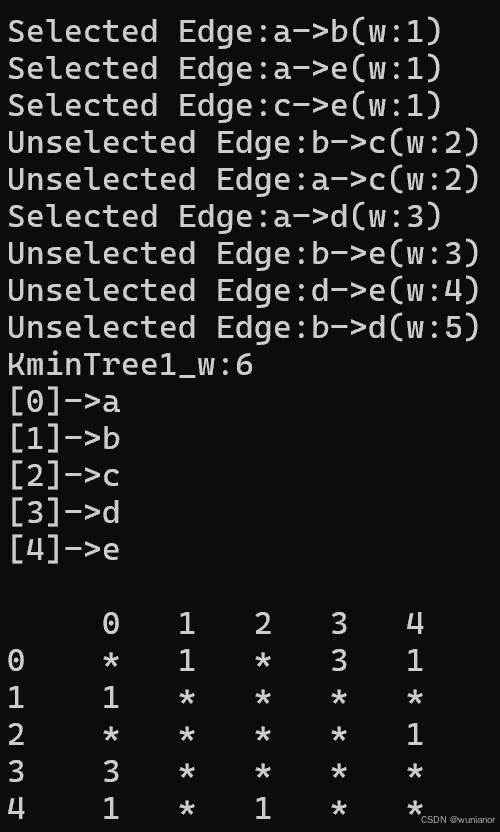
图2 无向图1生成的最小生成树1
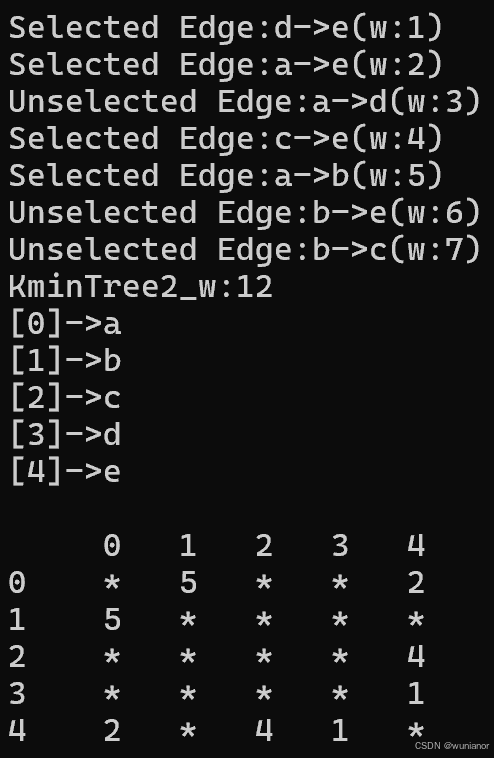
图3 无向图2生成的最小生成树2
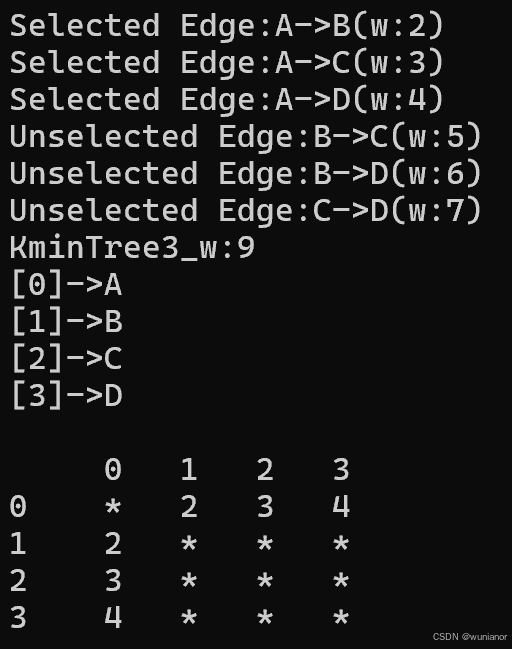
图4 无向图3生成的最小生成树3
(二)结果分析
正确性分析
从输出结果来看,程序按照Kruskal算法的要求,首先选择了权重最小的边,并且通过并查集判断避免了形成环。每次选择的边都符合最小生成树的构建规则,最终得到的边的集合确实构成了一棵包含所有顶点且权重之和最小的树。
性能分析
时间复杂度:
构建优先级队列(小堆)的时间复杂度为O(V^2logE),如果图为稀疏图则可近似认为是O(ElogE),其中V是图中的顶点数,E是图中的边数。插入一条边的时间复杂度为O(logE)。
并查集的操作(查找根、合并集合)的时间复杂度为O(α(n)),其中α为阿克曼函数的反函数,其增长极其缓慢,可以近似认为是O(1)。
在构建最小生成树的过程中,每次从堆中取出一条边需要O(logE)的时间,最多需要取出E条边,又因为并查集操作的时间复杂度可以近似认为是O(1),所以这部分的时间复杂度为O(ElogE)。
空间复杂度:
算法中使用了一个优先级队列来存储边,其空间复杂度为O(E) 。同时使用了一个并查集,其空间复杂度为O(V) 。所以总的空间复杂度为O(E+V) 。
六.总结和展望
(一)总结
算法实现
本实验成功实现了基于优先级队列和并查集改进的Kruskal算法来求解最小生成树。通过使用优先级队列有效地对边进行排序,利用并查集准确地判断边是否会形成环,从而构建出最小生成树。
性能分析
对算法的时间复杂度和空间复杂度进行了分析,了解到算法在处理边和顶点较多的图时的性能表现。
(二)展望
应用拓展
最小生成树算法在许多实际领域有广泛的应用,如网络设计、电路布局等。可以将该算法应用到实际项目中,解决实际问题,并根据实际需求对算法进行定制和扩展。
七、参考资料
1.C++标准库文档(参考优先级队列priority_queue、向量vector等容器的使用)
2.同时使用路径压缩和启发式合并优化的并查集操作的时间复杂度(https://oi-wiki.org/ds/dsu/)

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









