




 本文介绍了一种在ICRA上发表的方法,用于三维物体的关键点检测及6DoF位姿估计,特别适用于instance-and-category-based场景。通过Faster R-CNN检测2D边界框,结合stacking hourglass网络结构,输出一组关键点热力图,解决了遮挡和3D模型获取难题。
本文介绍了一种在ICRA上发表的方法,用于三维物体的关键点检测及6DoF位姿估计,特别适用于instance-and-category-based场景。通过Faster R-CNN检测2D边界框,结合stacking hourglass网络结构,输出一组关键点热力图,解决了遮挡和3D模型获取难题。
ICRA上的一篇文章,提出了一种检测三维物体关键点检测以及6 DoF位姿估计的方法,可以用于instance- and category-based 的场景。
代码:https://github.com/geopavlakos/object3d/
项目:https://www.seas.upenn.edu/~pavlakos/projects/object3d/
论文:https://arxiv.org/abs/1703.04670
首先采用Faster R-CNN检测得到目标的2D bb, 然后在执行所提出的方法。所使用的网络结构是stacking hourglass,来源于human pose estimation,与cornetNet中的backbone有些类似。网络的输入是RGB图像,输出是一组heatmaps, 每个关键点对应一个heatmap。每个heatmap的真值是一个以关键点真值为中心,方差为1的高斯仿真得到标签图像,目标函数是
L
2
L_2
L2损失。
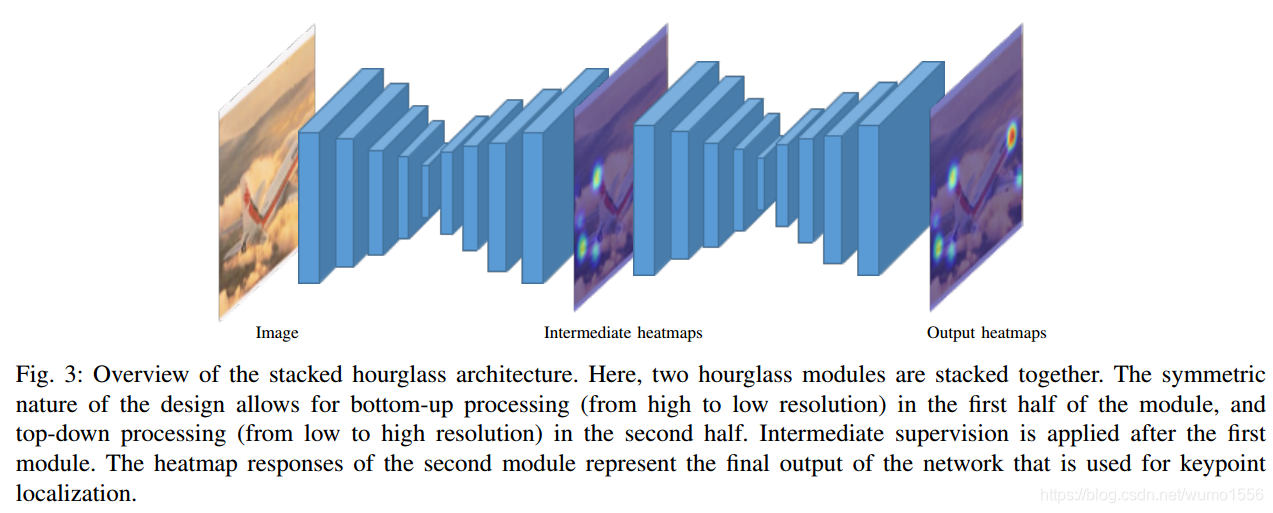
使用stacking hourglass有三个优点:
- 可以整合局部和全局信息
- stacking提供了一种迭代有效的过程,且对估计值可以求精;
- 中间监督可以用作有效的训练策略,尤其是在梯度消失的情况
文章中提到了在检测得到关键点后,直接使用PnP方法的两个问题:
- 由于遮挡或背景中的false detection,由网络预测得到的关键点可能被不精确的渲染;
- 目标精确的3D模型通常难以获得
文章中提出了一种deformable shape models方法解决这种问题。针对每一类物体,使用对应的3D CAD模型以及标注的关键点,构建可变形模型 S ∈ R 3 × p \boldsymbol{S}\in \mathbb{R}^{3\times p} S∈R3×p:
S = B 0 + ∑ i = 1 k c i B i \boldsymbol{S} = \boldsymbol{B}_0 + \sum_{i=1}^kc_i\boldsymbol{B}_i S=B0+i=1∑kciBi
其中
B
0
\boldsymbol{B}_0
B0是一给定3D模型的平均形状,
B
1
,
…
,
B
k
\boldsymbol{B}_1, \dots , \mathbf{B}_k
B1,…,Bk是由PCA计算得到形状分量。给定图像中检测的关键点,记为
W
∈
R
2
×
p
\boldsymbol{W}\in \mathbb{R}^{2\times p}
W∈R2×p,优化问题为:
min
θ
1
2
∥
ξ
(
θ
)
D
1
2
∥
F
2
+
λ
2
∥
c
∥
2
2
\min_{\theta}\frac{1}{2}\left \| \xi(\theta)\boldsymbol{D}^\frac{1}{2} \right \|^2_F + \frac{\lambda}{2}\left\| \boldsymbol{c} \right\|_2^2
θmin21∥∥∥ξ(θ)D21∥∥∥F2+2λ∥c∥22
文章中提出了针对弱透视与全透视相机模型下该问题的求解,其中在全透视模型下,使用对关键点网络预测进行的加权。
针对instance-based场景,文章收集了175幅RGB-D图像,手工标注了10个关键点,比较了弱透视、全透视模型与直接使用EPnP方法的位姿估计精度,全透视模型最好、EPnP其次,弱透视最差。弱透视模型用于初始化全透视场景。
instance-based场景下数据集的制作步骤为:
- 收集RGB-D数据
- Kinect 重建3D模型
- 在手工精心设置初始值后,由ICP算法计算每幅图像的位姿精确值
- 手工选择10个模型点,并使用计算得到的位姿精确值投影到图像上
class-based 场景使用了PASCAL3D+数据集,不再叙述了。
在6GB TitanX上关键点检测时间低于0.2s,位姿计算时间低于0.1s。
这篇文献还是很有意义的,对于instance-specific 的3D关键点检测中关键点检测以及数据集的制作是有一定的启发的。在精度上,该文献中全透视模型的旋转误差中值与均值分别3.11和3.57。代码由matlab和torch7完成,还没看。

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









