



Redis
介绍:
Redis是一个基于内存的key-value结构数据库(MySQL是通过数据文件方式存储在磁盘上,数据结构是二维表)
特点:

![]()
更改配置文件:
使用密码:
redis默认是不需要密码的,如果要设置密码,需要:打开redis.windows.conf,搜索pass (加一个空格),找到这个部分:# requirepass foobared,foobared部分改为你想设置的密码,然后去掉注释#,就可以了。
使用:
启动服务
在当前下载redis的文件路径下打开cmd,输入redis-server.exe redis.windows.conf,回车

启动服务后,可以选择两种方式进行连接
连接:
cmd方式:
在这个文件路径下再打开一个cmd,注意上面打开那个cmd不要关,然后输入redis-cli.exe,这里返回127.0.0.1:6379就说明连上了
图形界面方式:
下载图形化界面Another Redis Desktop Manager,新建连接,输入配置信息,进行连接
常用数据类型:

各种数据类型的特点:

常用命令:
字符串操作命令:

哈希操作命令:

列表操作命令:

集合操作命令:

有序集合操作命令:

通用命令:

操作Redis:
Redis的Java客户端:

下面我们使用Spring Data Redis来操作Redis
Spring Data Redis使用方式:

配置类RedisTemplate:
@Configuration
@Slf4j
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
log.info("开始创建redis模板对象...");
RedisTemplate redisTemplate = new RedisTemplate();
//设置redis连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置redis key的序列化器
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}
代码演示:
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testRedisTemplate() {
System.out.println(redisTemplate);
//操作字符串
ValueOperations valueOperations = redisTemplate.opsForValue();
//操作Hash
HashOperations hashOperations = redisTemplate.opsForHash();
//操作List
ListOperations listOperations = redisTemplate.opsForList();
//操作set
SetOperations setOperations = redisTemplate.opsForSet();
//操作有序集合
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
}
/**
* 操作字符串类型的数据
*/
@Test
public void testStirng() {
// set get setex setnx
redisTemplate.opsForValue().set("city","北京");
String city = (String) redisTemplate.opsForValue().get("city");
System.out.println(city);
redisTemplate.opsForValue().set("code","6562",60, TimeUnit.SECONDS);
redisTemplate.opsForValue().setIfAbsent("lock","1");
redisTemplate.opsForValue().setIfAbsent("lock","2");
}
/**
* 操作哈希类型的数据
*/
@Test
public void testHash() {
//hset hget hdel hkeys hvals
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.put("100","name","xiaobai");
hashOperations.put("100","age","20");
String name = (String) hashOperations.get("100", "name");
System.out.println(name);
Set keys = hashOperations.keys("100");
System.out.println(keys);
List values = hashOperations.values("100");
System.out.println(values);
hashOperations.delete("100","age");
}
/**
* 操作列表类型的数据
*/
@Test
public void testList() {
// lpush lrange rpop llen
ListOperations listOperations = redisTemplate.opsForList();
listOperations.leftPushAll("mylist","a","b","c");
listOperations.leftPush("mylist","d");
List mylist = listOperations.range("mylist", 0, -1);
System.out.println(mylist);
listOperations.rightPop("mylist");
Long size = listOperations.size("mylist");
System.out.println(size);
}
/**
* 操作集合类型的数据
*/
@Test
public void testSet() {
// sadd smembers scard sinter sunion srem
SetOperations setOperations = redisTemplate.opsForSet();
setOperations.add("set1","a","b","c");
setOperations.add("set2","b","c","d");
Set set1 = setOperations.members("set1");
System.out.println(set1);
Long size = setOperations.size("set1");
System.out.println(size);
Set intersect = setOperations.intersect("set1", "set2");
System.out.println(intersect);
Set union = setOperations.union("set1", "set2");
System.out.println(union);
setOperations.remove("set1","a","b");
}
/**
* 操作有序集合类型的数据
*/
@Test
public void testZSet() {
// zadd zrange zincrby zrem
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
zSetOperations.add("zset1","a",10);
zSetOperations.add("zset1","b",11);
zSetOperations.add("zset1","c",9);
Set zset1 = zSetOperations.range("zset1", 0, -1);
System.out.println(zset1);
zSetOperations.incrementScore("zset1","c",10);
zSetOperations.remove("zset1","a","b");
}
/**
* 通用命令操作
*/
@Test
public void testCommon() {
// keys exists type del
Set keys = redisTemplate.keys("*");
System.out.println(keys);
Boolean name = redisTemplate.hasKey("name");
Boolean set1 = redisTemplate.hasKey("set1");
for (Object key : keys) {
DataType type = redisTemplate.type(key);
System.out.println(type.name());
}
redisTemplate.delete("mylist");
}Redis缓存三兄弟:
1. 缓存穿透问题
1.1 什么是缓存穿透
使用缓存后代码的性能有了很大的提高,虽然性能有很大的提升但是控制台打出了很多“从数据库查询”的日志,明明判断了如果缓存存在课程信息则从缓存查询,为什么要有这么多从数据库查询的请求的?
这是因为并发数高,很多线程会同时到达查询数据库代码处去执行。
我们分析下代码:
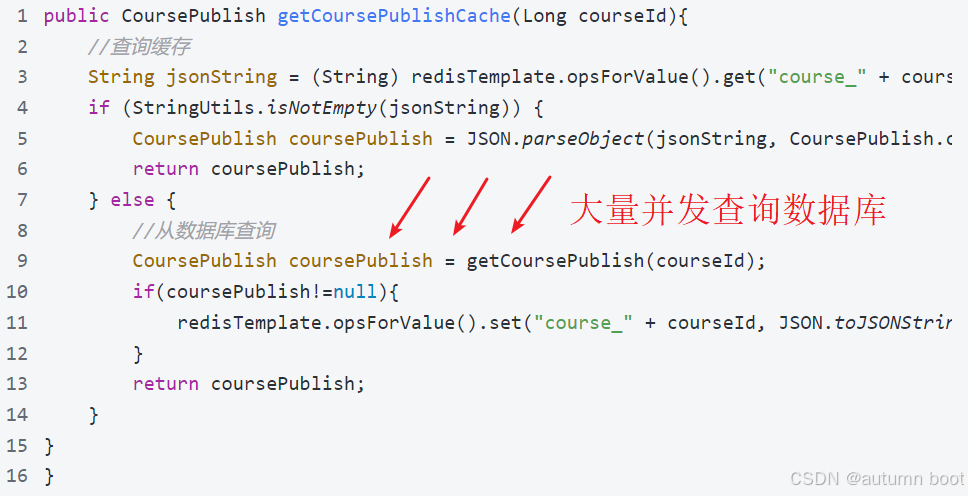
如果存在恶意攻击的可能,如果有大量并发去查询一个不存在的课程信息会出现什么问题呢?
比如去请求/content/course/whole/181,查询181号课程,该课程并不在课程发布表中。
进行压力测试发现会去请求数据库。
大量并发去访问一个数据库不存在的数据,由于缓存中没有该数据导致大量并发查询数据库,这个现象要缓存穿透。
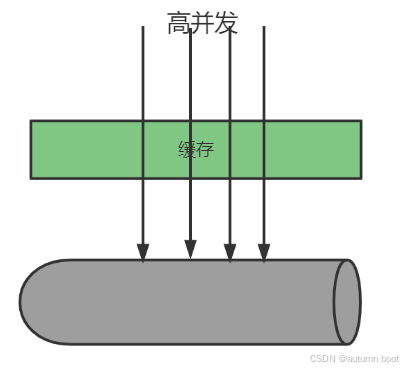
缓存穿透可以造成数据库瞬间压力过大,连接数等资源用完,最终数据库拒绝连接不可用。
1.2 解决缓存穿透
如何解决缓存穿透?
1、对请求增加校验机制
比如:课程Id是长整型,如果发来的不是长整型则直接返回。
2、使用布隆过滤器
什么是布隆过滤器,以下摘自百度百科:
布隆过滤器可以用于检索一个元素是否在一个集合中。如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
布隆过滤器的特点是,高效地插入和查询,占用空间少;查询结果有不确定性,如果查询结果是存在则元素不一定存在,如果不存在则一定不存在;另外它只能添加元素不能删除元素,因为删除元素会增加误判率。
比如:将商品id写入布隆过滤器,如果分3次hash此时在布隆过滤器有3个点,当从布隆过滤器查询该商品id,通过hash找到了该商品id在过滤器中的点,此时返回1,如果找不到一定会返回0。
所以,为了避免缓存穿透我们需要缓存预热将要查询的课程或商品信息的id提前存入布隆过滤器,添加数据时将信息的id也存入过滤器,当去查询一个数据时先在布隆过滤器中找一下如果没有到到就说明不存在,此时直接返回。
实现方法有:
Google工具包Guava实现。
redisson 。
2、缓存空值或特殊值
请求通过了第一步的校验,查询数据库得到的数据不存在,此时我们仍然去缓存数据,缓存一个空值或一个特殊值的数据。
但是要注意:如果缓存了空值或特殊值要设置一个短暂的过期时间。
public CoursePublish getCoursePublishCache(Long courseId) {
//查询缓存
Object jsonObj = redisTemplate.opsForValue().get("course:" + courseId);
if(jsonObj!=null){
String jsonString = jsonObj.toString();
if(jsonString.equals("null"))
return null;
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
} else {
//从数据库查询
System.out.println("从数据库查询数据...");
CoursePublish coursePublish = getCoursePublish(courseId);
//设置过期时间300秒
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish),30, TimeUnit.SECONDS);
return coursePublish;
}
}再测试,虽然还存在个别请求去查询数据库,但不是所有请求都去查询数据库,基本上都命中缓存。
2. 缓存雪崩
2.1 什么是缓存雪崩
缓存雪崩是缓存中大量key失效后当高并发到来时导致大量请求到数据库,瞬间耗尽数据库资源,导致数据库无法使用。
造成缓存雪崩问题的原因是是大量key拥有了相同的过期时间,比如对课程信息设置缓存过期时间为10分钟,在大量请求同时查询大量的课程信息时,此时就会有大量的课程存在相同的过期时间,一旦失效将同时失效,造成雪崩问题。
2.2 解决缓存雪崩
如何解决缓存雪崩?
1、使用同步锁控制查询数据库的线程
使用同步锁控制查询数据库的线程,只允许有一个线程去查询数据库,查询得到数据后存入缓存。
synchronized(obj){
//查询数据库
//存入缓存
}2、对同一类型信息的key设置不同的过期时间
通常对一类信息的key设置的过期时间是相同的,这里可以在原有固定时间的基础上加上一个随机时间使它们的过期时间都不相同。
示例代码如下:
//设置过期时间300秒
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish),300+new Random().nextInt(100), TimeUnit.SECONDS);3、缓存预热
不用等到请求到来再去查询数据库存入缓存,可以提前将数据存入缓存。使用缓存预热机制通常有专门的后台程序去将数据库的数据同步到缓存。
3. 缓存击穿
3.1 什么是缓存击穿
缓存击穿是指大量并发访问同一个热点数据,当热点数据失效后同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用。
比如某手机新品发布,当缓存失效时有大量并发到来导致同时去访问数据库。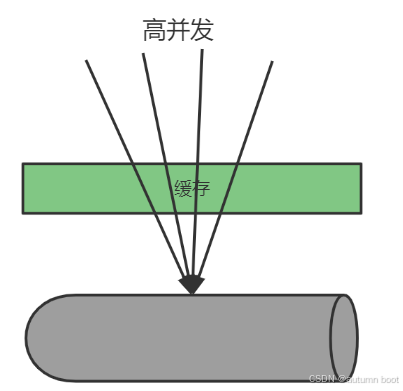
3.2 解决缓存击穿
如何解决缓存击穿?
1、使用同步锁控制查询数据库的线程
使用同步锁控制查询数据库的代码,只允许有一个线程去查询数据库,查询得到数据库存入缓存。
synchronized(obj){
//查询数据库
//存入缓存
}2、热点数据不过期
可以由后台程序提前将热点数据加入缓存,缓存过期时间不过期,由后台程序做好缓存同步。
下边使用synchronized对代码加锁。
public CoursePublish getCoursePublishCache(Long courseId){
synchronized(this){
//查询缓存
String jsonString = (String) redisTemplate.opsForValue().get("course:" + courseId);
if(StringUtils.isNotEmpty(jsonString)){
if(jsonString.equals("null"))
return null;
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
}else{
System.out.println("=========从数据库查询==========");
//从数据库查询
CoursePublish coursePublish = getCoursePublish(courseId);
//设置过期时间300秒
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish),300, TimeUnit.SECONDS);
return coursePublish;
}
}
}对上边的代码进行优化,对查询缓存的代码不用synchronized加锁控制,只对查询数据库进行加锁,如下:
public CoursePublish getCoursePublishCache(Long courseId){
//查询缓存
Object jsonObj = redisTemplate.opsForValue().get("course:" + courseId);
if(jsonObj!=null){
String jsonString = jsonObj.toString();
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
}else{
synchronized(this){
Object jsonObj = redisTemplate.opsForValue().get("course:" + courseId);
if(jsonObj!=null){
String jsonString = jsonObj.toString();
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
}
System.out.println("=========从数据库查询==========");
//从数据库查询
CoursePublish coursePublish = getCoursePublish(courseId);
//设置过期时间300秒
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish),300, TimeUnit.SECONDS);
return coursePublish;
}
}
}小结
1)缓存穿透:
去访问一个数据库不存在的数据无法将数据进行缓存,导致查询数据库,当并发较大就会对数据库造成压力。缓存穿透可以造成数据库瞬间压力过大,连接数等资源用完,最终数据库拒绝连接不可用。
解决的方法:
缓存一个null值。
使用布隆过滤器。
2)缓存雪崩:
缓存中大量key失效后当高并发到来时导致大量请求到数据库,瞬间耗尽数据库资源,导致数据库无法使用。
造成缓存雪崩问题的原因是是大量key拥有了相同的过期时间。
解决办法:
使用同步锁控制
对同一类型信息的key设置不同的过期时间,比如:使用固定数+随机数作为过期时间。
3)缓存击穿
大量并发访问同一个热点数据,当热点数据失效后同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用。
解决办法:
使用同步锁控制
设置key永不过期
无中生有是穿透,布隆过滤null隔离。 缓存击穿key过期, 锁与非期解难题。 大量过期成雪崩,过期时间要随机。 面试必考三兄弟,可用限流来保底。
限流技术方案:alibaba/Sentinel、nginx+Lua


















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









