



线上服务出现异常如何及时感知,每天不定时观察线上日志还是等用户反馈错误?
🤔…
这个问题应该有更好的答案…
试试Alertmanager
既然人工监测不是很合适,那就安排一个机器人吧!
怎么做?从日志收集logstash开始,到Alertmanager进行告警信息分组、抑制、静默,再到企业微信群聊机器人@具体的服务owner。
从日志收集开始
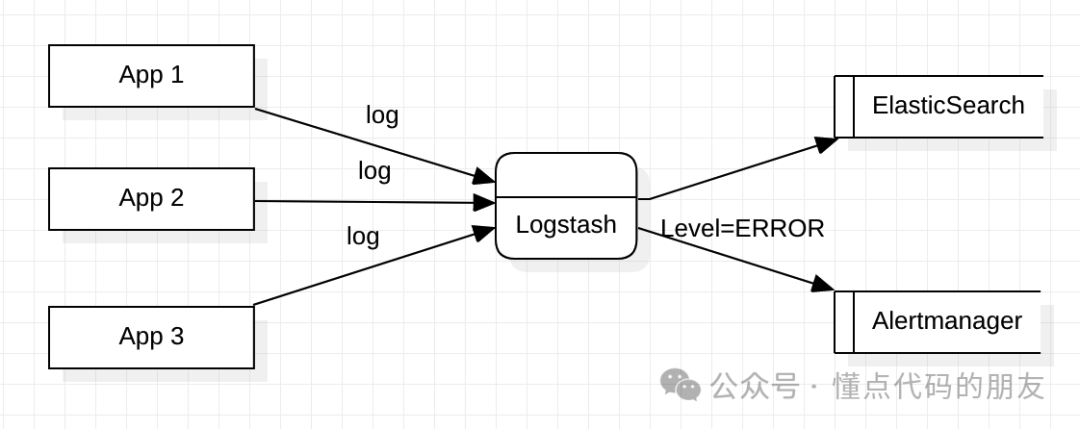
因为我们所有服务日志已经是由logstash统一收集了,所以这一步就比较简单了。在logstash输出时添加一个管道,把异常日志往Alertmanager输出一份,配置如下:
output {
# elasticsearch
...
# 添加异常日志输出
if 'ERROR' == [level] or 'WARN' == [level] {
http {
http_method => "post"
format => "json_batch"
url => "http://alertmanager/api/v1/alerts"
mapping => {
"labels" => {
"app" => "%{springAppName}"
"env" => "%{springProfilesActive}"
"level" => "%{level}"
"logger_name" => "%{logger_name}"
"traceId" => "%{traceId}"
}
"annotations" => {
"time" => "%{@timestamp}"
"message" => "%{message}"
"stack_trace" => "%{stack_trace}"
}
}
}
}
}
根据 alertmanager 的 api 配置好消息的格式,设置app、env、level等字段为标签,方便后续根据标签分组、静默。
日志告警规则管理
为什么要加一个Alertmanager而不是直接让logstash把异常日志发出去?
并不是logstash做不到,而是当logstash直接把异常发出去之后就会发现:
-
突然收到一堆告警,一模一样的消息发这么多,吓死我了
-
这个干嘛发给我,是下游服务出问题了已经发给他了还给我发
-
这个异常无关痛痒,不用再看了,别发了
-
再发,不看了
先部署Alertmanager
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: ops
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 30m
# 配置邮件发送信息
smtp_smarthost: 'smtp.example.com:25'
smtp_from: 'alertmanager@example.com'
smtp_auth_username: 'alertmanager@example.com'
smtp_auth_password: '1234'
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 app=order、env=pre、level=warn 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['app', 'env','level']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 3h
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: rocket
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: wecom-robot-rocket
match:
app: mall-order
receivers:
- name: 'email-rocket'
email_configs:
- to: 'rocket@example.com'
send_resolved: true
- name: 'wecom-robot-rocket'
webhook_configs:
- url: 'http://localhost:8080/api/webhook/send?key=yourWeComRobotKey&mentions=userId,all'
- name: 'wecom-rocket'
wechat_configs:
- corp_id: 'corp_id'
to_user: 'userId'
agent_id: 10001
api_secret: 'secret'
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: alert-pv-volume
namespace: ops
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data/alert"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: ops
labels:
app: alertmanager
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:v0.24.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: alertcfg
- mountPath: "/alertmanager/data"
name: alert-persistent-storage
- name: wecom-robot-adapter
image: wangsj/wecom-robot-adapter:1.2
ports:
- name: http
containerPort: 8080
protocol: TCP
volumes:
- name: alertcfg
configMap:
name: alert-config
- name: alert-persistent-storage
persistentVolumeClaim:
claimName: alert-pv-claim
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: ops
labels:
app: alertmanager
spec:
type: ClusterIP
ports:
- port: 9093
selector:
app: alertmanager
异常日志告警管理
分组
把同类型的警报进行分组,合并多条警报到一个通知中。在生产环境中,特别是云环境下的业务之间密集耦合时,若出现多台 Instance 故障,可能会导致成千上百条警报触发。在这种情况下使用分组机制, 可以把这些被触发的警报合并为一个警报进行通知,从而避免瞬间突发性的接受大量警报通知,使得管理员无法对问题进行快速定位。
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 app=order、env=pre、level=warn 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['app', 'env','level']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 3h
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: rocket
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: wecom-robot-rocket
match:
app: mall-order
抑制
当某条警报已经发送,停止重复发送由此警报引发的其他异常或故障的警报机制。
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal:
- alertname
- instance
静默
根据标签快速对警报进行静默处理;对传进来的警报进行匹配检查,如果接收到警报符合静默的配置,Alertmanager 则不会发送警报通知。
企业微信机器人通知
Alertmanager 可以将告警信息推送到邮箱、企业微信、钉钉、WebHook等多种目的地,这里主要是用WebHook方式推送到企业微信群聊。在企业微信群聊中新增机器人,用机器人的key替换下面url中的{企业微信机器人的key},并可设置需要@的用户ID。
receivers:
# 邮件通知
- name: 'rocket-email'
email_configs:
- to: 'rocket@example.com'
send_resolved: true
# 企业微信通知,直接发给个人或部门,需要企业微信后台配置自建应用
- name: 'rocket-wecom'
wechat_configs:
- corp_id: 'corp_id'
to_user: 'userId'
agent_id: 10001
api_secret: 'secret'
# 企业微信群聊机器人(推荐,任意企业微信群聊创建机器人后即可)
- name: 'wecom-robot-rocket'
webhook_configs:
- url: 'http://localhost:8080/api/webhook/send?key={企业微信机器人的key}&mentions=userId,all'
- name: 'wecom-robot-zhangsan'
webhook_configs:
- url: 'http://localhost:8080/api/webhook/send?key={企业微信机器人的key}&mentions=zhangsan'
最后
在了解完异常日志告警机器人的工作流程后,希望各位小伙伴在编程开发时重视日志打印的规范,以便机器人可以高效准确地将异常信息推送出来。


















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









