




 本文详细介绍了Faster R-CNN的核心贡献——区域提议网络(RPN),包括其工作原理、损失函数、训练策略等。通过RPN生成的候选框与Fast R-CNN结合,提升了目标检测的效率和精度。
本文详细介绍了Faster R-CNN的核心贡献——区域提议网络(RPN),包括其工作原理、损失函数、训练策略等。通过RPN生成的候选框与Fast R-CNN结合,提升了目标检测的效率和精度。
回顾R-CNN系列:
(1),R-CNN:生成候选框 + 对每个框进行分类回归的结构(生成region proposals + 提特征 + 多svm分类器 + bb回归);
(2),Fast R-CNN:在feature map上生成候选框,使用RoIpooling以统一全连接层的输入(softmax分类回归,146倍);
Faster R-CNN,贡献:提出RPN网络
(一)RPN
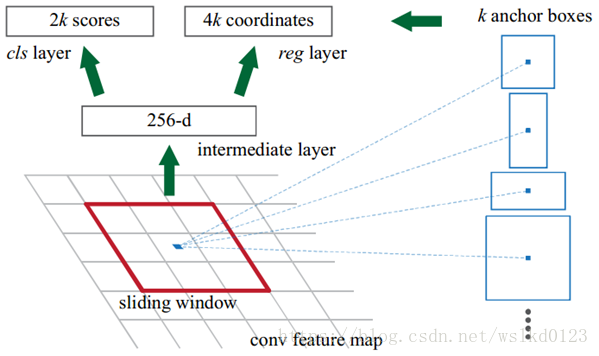
1):输入,特征图。
2):输出,一系列proposals及其分数。
3):步骤,先进行一个卷积核为3*3的卷积,生成维度为256的特征图;
再分别进行两个1*1的卷积,生成维度为2*k(预测前景和背景)和4*k(预测BB的4个坐标)的特征图;
4):损失函数
(1)为每个anchor设置标签:positive(和某一个真实框IoU最高;或和任意真实框IoU大于0.7)
negative(和所有真实框IoU小于0.3);
(2)其他的anchors不参与训练;
(3) loss function:
其中,i 为每个mini-batch中anchor的编号;
pi是第i个anchor为前景的概率;
pi*是真实框为前景的概率(1或0);
ti是第i个anchor的位置表示(一个4维数组);
ti*是真实框的位置表示(一个4维数组);
而,分类损失函数是二值损失函数;回归损失函数使用smooth L1(计算ti和ti*的4项smooth L1值然后相加)。
t包含四项:
其实是预测框相对于anchor的偏移量,x, y为中心坐标,w, h为宽和高;ti*同理。
5):RPN的训练(FRCN论文中的方案)
1):每个mini-batch有256个anchor,且取于同一张图片;
2):positive和negative为1:1,若positive不够,用negative填充;
3):用SGD训练,
所有的new layers权重初始化为高斯分布(均值为0,标准差为0.01),
所有的other layers(如共享卷积层)通过ImageNet classification 预训练得到;
4):用PASCAL VOC数据集fine-tuning(ZF net所有层,VGG16中conv3_1以上层),
前60k个mini-batch学习率为0.001,后20k个mini-batch学习率为0.0001,
momentum选0.9,学习衰减率选0.0005。
(二)RPN和Fast R-CNN检测网络的训练策略
论文中提出了三种方法:
1):交替训练,先训练RPN,再用该RPN生成的proposals训练Fast R-CNN,然后用被Fast R-CNN微调过的权重初 始化RPN,然后训练RPN,交替循环;
2):近似联合训练,把RPN loss和Fast R-CNN loss结合在一起同时训练;
3):非近似联合训练,对近似联合训练改进,论文中未讨论。
论文中最后选用的是一种4阶段法:
1):按(一)中方法单独训练RPN;
2):利用上一步产生的proposals单独训练Fast R-CNN;
3):用检测网络初始化RPN的训练,固定卷积层,然后fine-tune RPN特有层;
4):经上,卷积层已共享。现在,固定卷积层,然后fine-tune Fast R-CNN特有层。

















 3657
3657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









