




 本文探讨了西瓜问题的假设空间,通过实例分析排除与正例不符和与反例一致的假设,最终保留了关键特征的假设。
本文探讨了西瓜问题的假设空间,通过实例分析排除与正例不符和与反例一致的假设,最终保留了关键特征的假设。
假设空间:所有属性值可能取值的集合
版本空间:与已知数据集一致的假设空间的子集合
求西瓜问题的版本空间
色泽属性可取(青绿,乌黑,*),根蒂属性可取(蜷缩,硬挺,稍蜷,*),敲声属性可取(浊响,清脆,沉闷,*),以及好瓜假设不存在(∅\empty∅)。即西瓜问题的假设空间大小为(3*4*4+1=49)
(1)列出所有假设空间
(2)删除与正例不一样的假设,和与反例一致的假设
其假设空间如下:
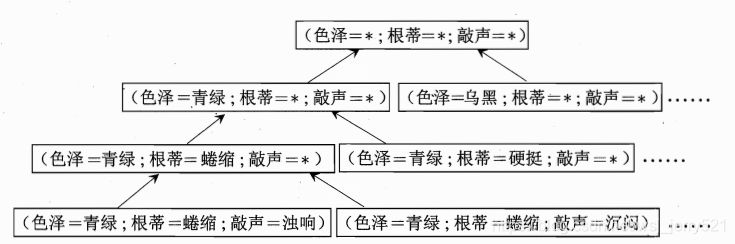

表1.1的假设空间如下表格所示:
| 序号 | 色泽 | 根蒂 | 敲声 | 编号1 | 编号2 | 编号3 | 编号4 | 最终保留 |
|---|---|---|---|---|---|---|---|---|
| 1 | 色泽 = * | 根蒂 = * | 敲声 = * | ×\times× | ||||
| 2 | 色泽 = * | 根蒂 = * | 敲声 = 浊响 | QVQ | ||||
| 3 | 色泽 = * | 根蒂 = * | 敲声 = 清脆 | ×\times× | ||||
| 4 | 色泽 = * | 根蒂 = * | 敲声 = 沉闷 | ×\times× | ||||
| 5 | 色泽=* | 根蒂=蜷缩 | 敲声=* | QVQ | ||||
| 6 | 色泽=* | 根蒂=蜷缩 | 敲声=浊响 | QVQ | ||||
| 7 | 色泽=* | 根蒂=蜷缩 | 敲声=清脆 | ×\times× | ||||
| 8 | 色泽=* | 根蒂=蜷缩 | 敲声=沉闷 | ×\times× | ||||
| 9 | 色泽=* | 根蒂=硬挺 | 敲声=* | ×\times× | ||||
| 10 | 色泽=* | 根蒂=硬挺 | 敲声=浊响 | ×\times× | ||||
| 11 | 色泽=* | 根蒂=硬挺 | 敲声=清脆 | ×\times× | ||||
| 12 | 色泽=* | 根蒂=硬挺 | 敲声=沉闷 | ×\times× | ||||
| 13 | 色泽=* | 根蒂=稍蜷 | 敲声=* | ×\times× | ||||
| 14 | 色泽=* | 根蒂=稍蜷 | 敲声=浊响 | ×\times× | ||||
| 15 | 色泽=* | 根蒂=稍蜷 | 敲声=清脆 | ×\times× | ||||
| 16 | 色泽=* | 根蒂=稍蜷 | 敲声=沉闷 | ×\times× | ||||
| 17 | 色泽 = 青绿 | 根蒂 = * | 敲声 = * | ×\times× | ||||
| 18 | 色泽 = 青绿 | 根蒂 = * | 敲声 = 浊响 | ×\times× | ||||
| 19 | 色泽 = 青绿 | 根蒂 = * | 敲声 = 清脆 | ×\times× | ||||
| 20 | 色泽 = 青绿 | 根蒂 = * | 敲声 = 沉闷 | ×\times× | ||||
| 21 | 色泽=青绿 | 根蒂=蜷缩 | 敲声=* | ×\times× | ||||
| 22 | 色泽=青绿 | 根蒂=蜷缩 | 敲声=浊响 | ×\times× | ||||
| 23 | 色泽=青绿 | 根蒂=蜷缩 | 敲声=清脆 | ×\times× | ||||
| 24 | 色泽=青绿 | 根蒂=蜷缩 | 敲声=沉闷 | ×\times× | ||||
| 25 | 色泽=青绿 | 根蒂=硬挺 | 敲声=* | ×\times× | ||||
| 26 | 色泽=青绿 | 根蒂=硬挺 | 敲声=浊响 | ×\times× | ||||
| 27 | 色泽=青绿 | 根蒂=硬挺 | 敲声=清脆 | ×\times× | ||||
| 28 | 色泽=青绿 | 根蒂=硬挺 | 敲声=沉闷 | ×\times× | ||||
| 29 | 色泽=青绿 | 根蒂=稍蜷 | 敲声=* | ×\times× | ||||
| 30 | 色泽=青绿 | 根蒂=稍蜷 | 敲声=浊响 | ×\times× | ||||
| 31 | 色泽=青绿 | 根蒂=稍蜷 | 敲声=清脆 | ×\times× | ||||
| 32 | 色泽=青绿 | 根蒂=稍蜷 | 敲声=沉闷 | ×\times× | ||||
| 33 | 色泽 = 乌黑 | 根蒂 = * | 敲声 = * | ×\times× | ||||
| 34 | 色泽 = 乌黑 | 根蒂 = * | 敲声 = 浊响 | ×\times× | ||||
| 35 | 色泽 = 乌黑 | 根蒂 = * | 敲声 = 清脆 | ×\times× | ||||
| 36 | 色泽 = 乌黑 | 根蒂 = * | 敲声 = 沉闷 | ×\times× | ||||
| 37 | 色泽=乌黑 | 根蒂=蜷缩 | 敲声=* | ×\times× | ||||
| 38 | 色泽=乌黑 | 根蒂=蜷缩 | 敲声=浊响 | ×\times× | ||||
| 39 | 色泽=乌黑 | 根蒂=蜷缩 | 敲声=清脆 | ×\times× | ||||
| 40 | 色泽=乌黑 | 根蒂=蜷缩 | 敲声=沉闷 | ×\times× | ||||
| 41 | 色泽=乌黑 | 根蒂=硬挺 | 敲声=* | ×\times× | ||||
| 42 | 色泽=乌黑 | 根蒂=硬挺 | 敲声=浊响 | ×\times× | ||||
| 43 | 色泽=乌黑 | 根蒂=硬挺 | 敲声=清脆 | ×\times× | ||||
| 44 | 色泽=乌黑 | 根蒂=硬挺 | 敲声=沉闷 | ×\times× | ||||
| 45 | 色泽=乌黑 | 根蒂=稍蜷 | 敲声=* | ×\times× | ||||
| 46 | 色泽=乌黑 | 根蒂=稍蜷 | 敲声=浊响 | ×\times× | ||||
| 47 | 色泽=乌黑 | 根蒂=稍蜷 | 敲声=清脆 | ×\times× | ||||
| 48 | 色泽=乌黑 | 根蒂=稍蜷 | 敲声=沉闷 | ×\times× | ||||
| 49 | ∅\varnothing∅ | ∅\varnothing∅ | ∅\varnothing∅ | ×\times× |
根据表1.1剔除假设空间中的某些数据
1.根据 编号1. 色泽=青绿 根蒂=蜷缩 敲声=浊响 是(好瓜)
删除假设空间中的:3-4 7-16 19-20 23-49
2.根据 编号2. 色泽=乌黑 根蒂=蜷缩 敲声=浊响 是(好瓜)
删除剩余假设空间中的17-18 21-22
3.根据 编号3 色泽=青绿 根蒂=硬挺 敲声=清脆 否(好瓜)
删除剩余假设空间的1
4.根据 编号4 色泽=乌黑 根蒂=稍蜷 敲声=沉闷 否(好瓜)剩余假设空间无需删除。
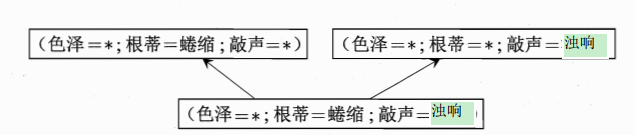
最后剩余2,5,6
2. 色泽= * 根蒂 = * 敲声 = 浊响
3. 色泽=* 根蒂=蜷缩 敲声=*
4. 色泽=* 根蒂=蜷缩 敲声=浊响

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









