









从之前分享的强化学习、DQN中,我们可以看到在计算目标值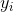 时和计算当前值用的是同一个网络Q,这样在计算算目标值时用到了我们需要训练的网络Q,之后我们又用目标值来更新网络Q的参数,这样的参数,这样两者的依赖性太强,不利于算法的收敛,下面通过两个DQN的变种Nature DQN和Double DQN来解决这个问题。DQN的亮点之一就是采用经验回放技巧来缓和训练样本之间的关联性,但是由于采用的是均匀随机采样,其实一些样本对梯度的更新是比较小的,如果同等对待,那就会增加计算成本,甚至会导致效果不佳,Prioritized Replay DQN提出了优先回放来提高模型效率;而Dueling DQN从网络架构出发,直接把状态动作函数拆分为两部分:一部分是状态值函数;另一部分是优势函数。下面分别介绍一下这几种DQN的变种:
时和计算当前值用的是同一个网络Q,这样在计算算目标值时用到了我们需要训练的网络Q,之后我们又用目标值来更新网络Q的参数,这样的参数,这样两者的依赖性太强,不利于算法的收敛,下面通过两个DQN的变种Nature DQN和Double DQN来解决这个问题。DQN的亮点之一就是采用经验回放技巧来缓和训练样本之间的关联性,但是由于采用的是均匀随机采样,其实一些样本对梯度的更新是比较小的,如果同等对待,那就会增加计算成本,甚至会导致效果不佳,Prioritized Replay DQN提出了优先回放来提高模型效率;而Dueling DQN从网络架构出发,直接把状态动作函数拆分为两部分:一部分是状态值函数;另一部分是优势函数。下面分别介绍一下这几种DQN的变种:
Nature DQN算法
在NatureDQN中提出了使用两个网络,一个原网络Q用来选择动作,并更新参数,另一个目标网络Q′只用来计算目标值,在这里目标网络Q′的参数不会进行迭代更新,而是隔一定时间从原网络Q中异步更新过来,因此两个网络的结构也需要完全一致,否则无法进行参数复制,其他内容和DQN完全一样。
Double DQN算法
尽管NatureDQN在解决更新目标与更新Q网络方面有一定的改善作用,但是仍然无法克服Qlearning固有的缺陷-过估计,过估计造成的原因是每次选择动作是采用贪婪策略,是公式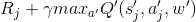 中的max造成的,max操作使得估计的值函数比真实的值要大。为了解决值函数过估计的问题,Hasselt提出了DoubleDQN算法,这个算法和NatureDQN一样也有两个网络,但是与natureDQN不同,它的原网络Q和目标网络Q′是独立的,参数不会共享。
中的max造成的,max操作使得估计的值函数比真实的值要大。为了解决值函数过估计的问题,Hasselt提出了DoubleDQN算法,这个算法和NatureDQN一样也有两个网络,但是与natureDQN不同,它的原网络Q和目标网络Q′是独立的,参数不会共享。
其计算目标值yj的步骤可以拆分为两步:
1)通过原网络Q获得最大值函数的动作a;
2)是通过目标Q′网络获得上面的动作a对应的值
将上面两个步骤合并起来就是Double DQN的目标值,如下所示:
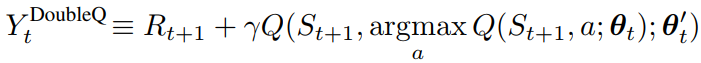
除此之外,其他和NatureDQN一样
Prioritized Replay DQN算法
Double DQN改进了Qlearning中max的操作,经验回放仍然采用均匀分布,但是并非所有的样本对智能体都有意义,至少不是同等重要。而且有一种Blind Cliffwalk环境,当回报非常稀疏的时候,想要充分探索是非常有挑战的,如下图:
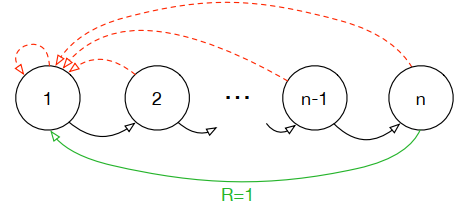
当环境只有n个状态的时候,随机选择一个序列动作会有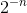 的概率才能得到第一个非零回报,最相关的转移隐藏在大量失败的尝试中。为此提出了Prioritizedreplay,它的思想是TD偏差越大,智能体学习效率越高,权重也越大。
的概率才能得到第一个非零回报,最相关的转移隐藏在大量失败的尝试中。为此提出了Prioritizedreplay,它的思想是TD偏差越大,智能体学习效率越高,权重也越大。
假设样本i的TD偏差为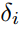 ,则该样本的采样概率为:
,则该样本的采样概率为:
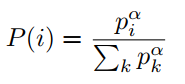
指数α说明优先级,如果α=0,相当于是均匀分布。
Pi有两种计算方法:
第一种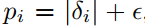 :,ε是一个比较小的正数,避免TD偏差为0,采样概率为0的情况;
:,ε是一个比较小的正数,避免TD偏差为0,采样概率为0的情况;
第二种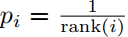 :,其中
:,其中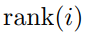 是根据的排序。
是根据的排序。
如果每次抽样都需要针对 p 对所有样本排序, 这将会是一件非常消耗计算能力的事. 文中提出了一种被称作SumTree的方法。
SumTree 是一种树形结构, 每片树叶存储每个样本的优先级 p, 每个树枝节点只有两个分叉, 节点的值是两个分叉的合, 所以 SumTree 的顶端就是所有 p 的合. 如下图所示。最下面一层树叶存储样本的 p, 叶子上一层最左边的 13 = 3 + 10, 按这个规律相加, 顶层的 root 就是全部 p 的合了.

抽样时, 我们会将 p 的总合除以 batch size, 分成 batch size 那么多区间,(n=sum(p)/batch_size). 如果将所有 node 的 priority 加起来是42的话, 我们如果抽6个样本, 这时的区间拥有的 priority 可能是这样.
[0-7], [7-14],[14-21], [21-28], [28-35], [35-42]
然后在每个区间里随机选取一个数. 比如在第区间 [21-28] 里选到了24, 就按照这个 24 从最顶上的42开始向下搜索. 首先看到最顶上 42 下面有两个 child nodes, 拿着手中的24对比左边的 child 29, 如果左边的 child 比自己手中的值大, 那我们就走左边这条路, 接着再对比 29 下面的左边那个点 13, 这时, 手中的 24 比 13 大, 那我们就走右边的路, 并且将手中的值根据 13 修改一下, 变成 24-13 = 11. 接着拿着 11 和 13 左下角的 12 比, 结果 12 比 11 大, 那我们就选 12 当做这次选到的 priority, 并且也选择 12 对应的数据
由于采用优先回放的概率分别后,动作值函数的估计值是一个有偏估计,为了矫正这个偏差,需要乘以一个重要性采用系数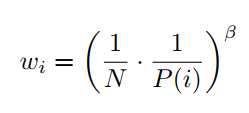
Prioritized Replay DQN算法的伪代码如下:

Dueling DQN算法
前面已经介绍了几种DQN的变种,而Dueling DQN算法则是把动作值函数分解为状态值函数和优势函数(每个动作在该状态的值函数的值与该状态所有动作值函数的平均值差额),公式如下:
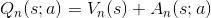
更具体的形式如下:
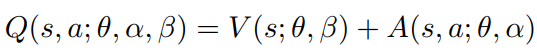
但是,利用上面的式子计算Q值会出现一个unidentifiable问题:给定一个Q,是无法得到唯一的V和A的。比如,V和A分别加上和减去一个值能够得到同样的Q,但反过来显然无法由Q得到唯一的V和A
解决方案:
强制令所选择贪婪动作的优势函数为0:

我们能得到唯一的值函数
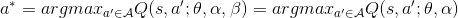
, 我们得到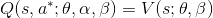
解决方案的改进
使用优势函数的平均值代替上述的最优值
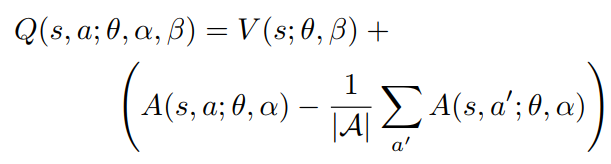
采用这种方法,虽然使得值函数V和优势函数A不再完美的表示值函数和优势函数(在语义上的表示),但是这种操作提高了稳定性。而且,并没有改变值函数V和优势函数A的本质表示。
Dueling DQN算法结构图如下:

参考文献:
https://www.jianshu.com/p/db14fdc67d2c
https://www.jianshu.com/p/b421c85796a2


















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











