




 本文介绍如何在MaxCompute和Hive中定位数据倾斜问题,包括通过作业回放查看执行耗时、对比数据量变化以及具体阶段(Map、Join、Reduce)的分析方法。
本文介绍如何在MaxCompute和Hive中定位数据倾斜问题,包括通过作业回放查看执行耗时、对比数据量变化以及具体阶段(Map、Join、Reduce)的分析方法。
SQL性能优化系列:
Hive/MaxCompute SQL性能优化(一):什么是数据倾斜
前言
前面的文章我们简单介绍了什么是数据倾斜,今天我们来讲一下如何定位是否出现了数据倾斜,以及是在什么阶段出现的数据倾斜。
作业回放
在Maxcompute的Logview中是可以回放作业执行的耗时的,当然也可以在下面直接看到各阶段的执行耗时,若发现某个阶段的执行时间特别长,且点击它之后,下面的实例中出现了Long-tails/Data-Skews,或某个实例的执行比其他实例慢很多。则大概率是出现了数据倾斜。
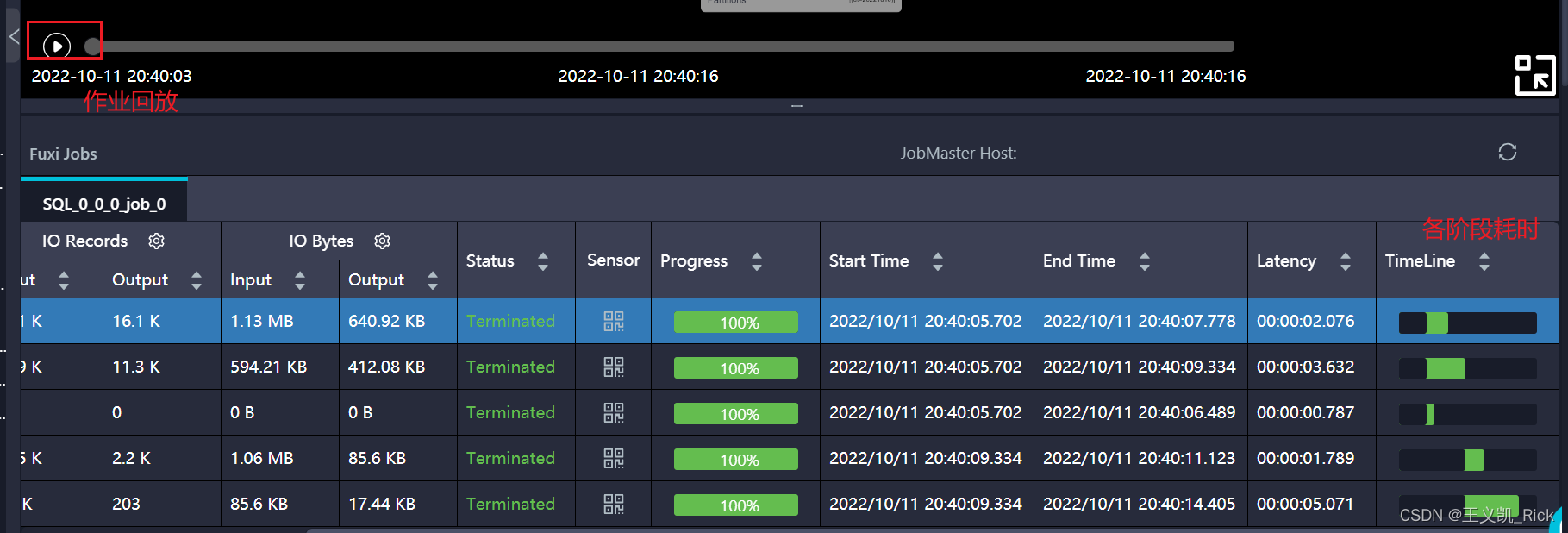

对于Hive,则可以在日志中看是否在某个阶段耗时较长一直卡在99%。

数据量对比
第二种方式是对比该输出表的数据量,相比过去每天是否出现大幅的波动,如之前每天10万数据,今天突然变成1亿条,那就很有可能是出现了笛卡尔积的情况导致数据放大。
定位节点
在作业回放的内容中,我们可以清楚的看到,作业在执行的过程中是在哪个阶段(map/join/reduce)出现的性能问题。
定位数据
针对不同的阶段,分析的方式也不一样。
Map阶段:在map阶段出现倾斜的原因一种是上游数据分布不均,小文件过多。另一种情况是在map端聚合的时候某些mapper读取的文件中某些值量级过多导致长尾。
Join阶段:Join阶段最容易出现数据倾斜,大部分情况是在关联的时候出现热点值导致数据倾斜。或者是大小表关联导致的数据倾斜。
Reduce阶段:在map阶段聚合导致key值分布不均匀。join阶段产生很多null值被分发到同一个reduce实例导致数据倾斜。多次使用distinct导致数据倾斜。动态分区导致小文件过多产生数据倾斜。
解决思路
在上面我们可以看到无论是map,join还是reduce都有很多种出现数据倾斜的原因,针对不同的产生原因有不同的优化方式。
如:列剪裁,过滤脏数据,预处理,mapjoin,调整参数增加资源等等。
在后面的文章中我们会逐一介绍上述情况下出现的数据倾斜的优化策略和方式,敬请期待。
如果我的文章对你有帮助,请帮忙转发/点赞/收藏,谢谢!


















 4254
4254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











