




有没有想过,如果在redis内判断某个值是否存在,使用什么方式最快?使用Set的话当体量大的时候不仅查询慢,而且还占用非常大的空间,本篇就介绍一个即快速又节约空间的方式,使用布隆过滤器来判断某个值是否在集合内。
目录
Redis6系列文章:
Redis系列(一)、CentOS7下安装Redis6.0.3稳定版
Redis系列(六)、数据类型之有序集合ZSet(sorted_set)
Redis系列(十)、详解Redis持久化方式AOF、RDB以及混合持久化
Redis系列(十一)、Redis6新特性之ACL安全策略(用户权限管理)
Redis系列(十二)、Redis6集群搭建及原理(主从、哨兵、集群)
Redis系列(十三)、pub/sub发布与订阅(对比List和Kafka)
Redis系列(十四)、Redis6新特性之RESP3与客户端缓存(Client side caching)
Redis系列(十五)、Redis6新特性之集群代理(Cluster Proxy)
Redis系列(十七)、Redis中的内存淘汰策略和过期删除策略
Redis系列(十八)、Redis中的管道pipeline操作(Python)
介绍
布隆过滤器(Bloom Filter),是一个二进制向量和一系列随机映射函数实现。它是一种概率型数据结构,特点是高效、占用空间小,常用于判断某个元素是否在一个集合中,这个结果并不是完全准确的,它只能给一个概率性的结果,但只要正确的使用,在足够大体量的数据中这个概率几乎可以忽略不计。
安装
官网
在Github上下载最新版的源码包 下载RedisBloom_v2.2.3 :
Bloom_Github: https://github.com/RedisBloom/RedisBloom
Bloom_Python: https://github.com/RedisBloom/redisbloom-py
编译
进入RedisBloom源码包进行编译,编译完成后我们得到文件redisbloom.so:
tar -zxvf RedisBloom-2.2.3.tar.gz -C .
cd RedisBloom-2.2.3
make安装
为了方便管理Redis的模块,我在Redis目录下新建module目录并将刚才编译的文件复制到该目录下,然后安装该模块:
1. 创建模块目录并将编译的bloomfiler模块放进去
mkdir /opt/app/redis6/module
mv redisbloom.so /opt/app/redis6/module/
2安装Bloom Filter模块 有两种方式
#2.1 修改配置文件redis.conf,加上下面这行代码,使用绝对路径
loadmodule /opt/app/redis6/module/redisbloom.so
#2.2 也可以在启动Redis服务器的时候指定参数安装模块
redis-server --loadmodule /opt/app/redis6/module/redisbloom.so
3. 重启Redis服务器
systemctl restart redis 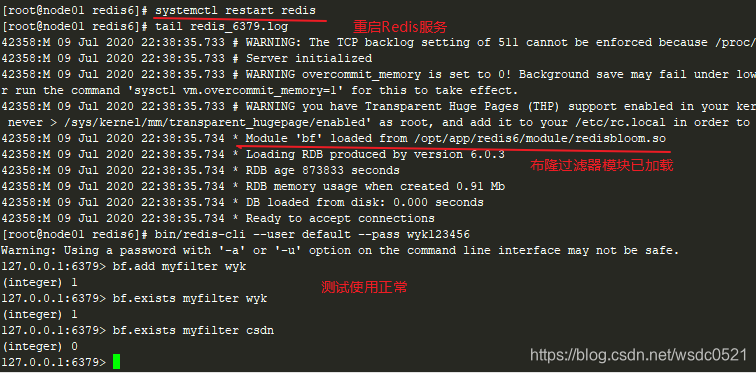
原理
布隆过滤器
每个布隆过滤器对应到Redis中就是一个位数组和几个不同的无偏型hash函数(无偏型是指把元素的hash值算的比较均匀),当我们向布隆过滤器中新增元素时,会调用这几个hash函数将算出来的几个整型索引值对应到位数组中的位置,将那几个位置的值标为1,默认该位数组上所有值都是0。
在判断元素是否在该集合中时,也是调用这几个hash函数将算出来的几个整型索引值对应到位数组中的位置,判断这几个位置是否全部为1,如果有不为1的值,那么该元素一定不在这个集合内,如果全部为1,则该元素可能存在于该集合内。
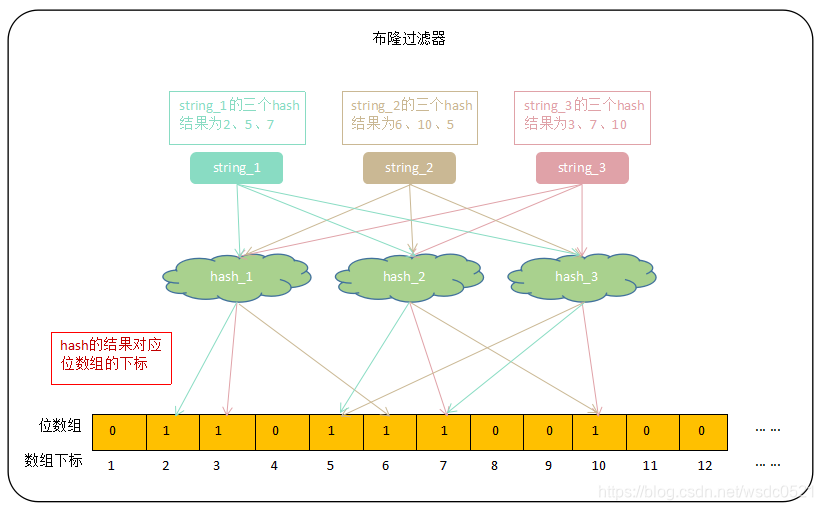
由上图可以看到,string_1,sting_2,string_3在被三个hash算法计算之后的结果会作为下标到位数组对应的位置将值更新为1,因此当我们想要判断string_1是否在集合中的时候,只需要判断位数组的下标位置2,5,7的值是否为1,当三个位置有不为1的值时,那么string_1一定不在该集合中,当三个值都为1的时候,string_1可能在集合中。这里为什么说可能呢? 举个例子:还是上面的图,string_1,string_2,string_3都在集合内,此时如果我想判断string_4(hash后的值为2,3,6)是否在集合中,可以看到位数组中下标为2,3,6的值都是1,因为被string_1,string_2,string_3的计算结果给更新过了,此时布隆过滤器给我们的结果是string_4在集合内,而我们知道string_4其实不在集合内的,所以这里是会有误判的存在。
这个误判的失败率跟hash算法的个数以及位数组的长度有关 ,数组越长、hash算法越多、插入元素越少,误判率就会越低。反之则误判率越高。而位数组长度越长或者hash算法越多,也会影响到空间效率和查询效率,因此我们需要根据实际需要合理的去使用布隆过滤器。
布隆过滤器可以判断某个元素一定不存在,但是无法判断它一定存在;
优点:
- 空间效率高,空间占用小
- 查询效率高
缺点:
- 不能删除元素(已被更新为1的位数组中的位,不能再被更新为0)
- 有误判率
空间占用
布隆过滤器有两个参数,第一个是预计元素的数量n,第二个是误判率p。公式根据这两个输入得到两个输出,第一个输出是位数组的长度m,也就是需要的存储空间大小(bit),第二个输出是hash函数的最佳数量k。hash函数的数量也会直接影响到误判率,最佳的数量会有最低的误判率。
计算公式:
k≈0.7*(m/n)
p≈0.6185^(m/n) 由上面的公式我们可以得到下面几个结论:
- 位数组m越长,误判率p就越低;
- 位数组m越长,hash函数最佳数量k就越多,影响计算效率;
- 当一个元素平均需要一个字节(8bit)空间时,即m/n=8,误判率大约2%;
因此我们可以大致估算出在不同的误判率p下,每个元素的平均占用空间m/n:
| 误判率p | 每个元素的平均占用(m/n) |
| 0.0001% | 28.755bit |
| 0.001% | 23.962bit |
| 0.01% | 19.170bit |
| 0.1% | 14.377bit |
| 1% | 9.585bit |
| 10% | 4.792bit |
即使在误判率P为百万分之一时,每个元素的占用也就29bit,就算存100万个元素,也不过消耗28MB的空间,由此可见,布隆过滤器的空间效率非常高,占用非常小。相比于直接存储在set中,无论是查询速度还是存储方式都更优秀。
如果想了解更多布隆过滤器的相关推导公式请参考:布隆过滤器 (Bloom Filter) 详解
使用
我们可以在命令行或者其他语言的客户端使用,上面给出了python的客户端地址,我们也可以使用pip命令安装,这里演示命令行和python客户端的使用方式。
命令行:
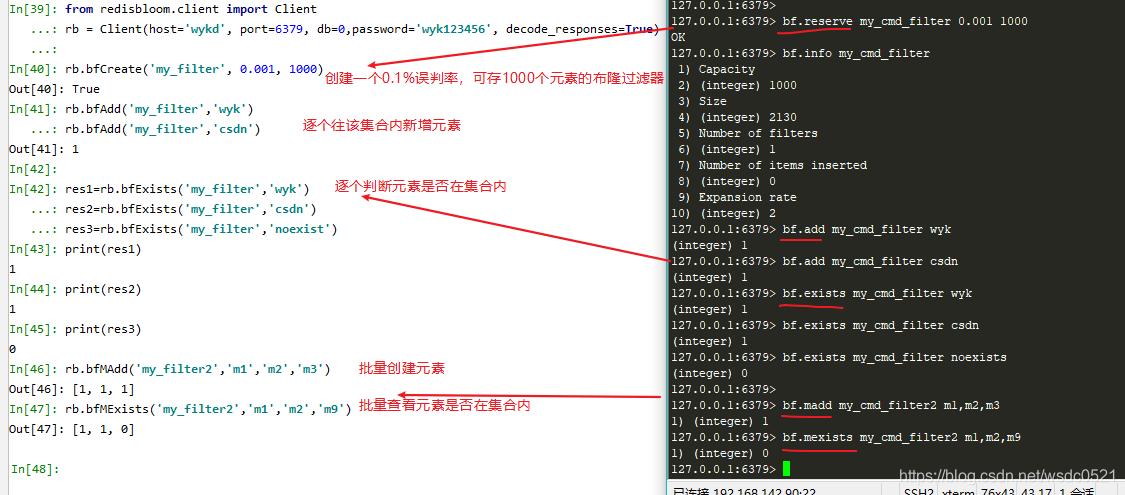
#创建一个误判率0.1%,可存储1000个元素的布隆过滤器
bf.reserve my_cmd_filter 0.001 1000
#查看布隆过滤器
bf.info my_cmd_filter
#新增元素
bf.add my_cmd_filter wyk
#判断元素是否在集合内
bf.exists my_cmd_filter wyk
#批量新增元素
bf.madd my_cmd_filter2 m1,m2,m3
#批量判断元素是否在集合内
bf.mexists my_cmd_filter2 m1,m2,m9
Python:
#获取布隆过滤器连接
from redisbloom.client import Client
rb = Client(host='wykd', port=6379, db=0,password='wyk123456', decode_responses=True)
#创建一个0.1%误判率,可存放1000个元素的布隆过滤器
rb.bfCreate('my_filter', 0.001, 1000)
#给布隆过滤器新增元素
#若过滤器不存在则自动创建过滤器且默认为1%错判率,长度为100;
rb.bfAdd('my_filter','wyk')
rb.bfAdd('my_filter','csdn')
#判断元素是否存在
res1=rb.bfExists('my_filter','wyk')
res2=rb.bfExists('my_filter','csdn')
res3=rb.bfExists('my_filter','noexist')
print(res1) #res:1
print(res2) #res:1
print(res3) #res:0
#批量新增元素
#若过滤器不存在则自动创建过滤器且默认为1%错判率,长度为100;
rb.bfMAdd('my_filter2','m1','m2','m3')
#批量判断元素是否存在,返回列表
rb.bfMExists('my_filter2','m1','m2','m9') #res: [1,1,0]
应用场景
前面提到,布隆过滤器可以用于判断元素是否在集合内,经过合理的配置,布隆过滤器的常用场景有下面几种:
- 爬虫避免爬到重复内容
- 消息推送避免推送给相同的人
- 刷抖音头条等信息流app时避免看到重复的内容
- 解决缓存穿透等缓存问题;
另外除了布隆过滤器(Bloom Filter),redisbloom中还有三种过滤算法Cuckoo Filter、Count-Min Sketch、Top-K,其中布谷过滤器(Cuckoo Filter)可以解决布隆过滤器无法删除的缺点。有兴趣的同学可以深入了解一下。
希望本文对你有帮助,请点个赞鼓励一下作者吧~ 谢谢!


















 1784
1784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











