




 本文详细介绍Kafka集群的安装、配置与监控过程,包括下载KafkaEagle、解压、环境变量设置、配置文件修改及启动验证。涵盖topic创建、producer与consumer启动、topic信息查看及消费情况检查等关键步骤。
本文详细介绍Kafka集群的安装、配置与监控过程,包括下载KafkaEagle、解压、环境变量设置、配置文件修改及启动验证。涵盖topic创建、producer与consumer启动、topic信息查看及消费情况检查等关键步骤。
下载,解压,配置环境变量,修改配置,启动验证。
使用Kafka Eagle监控kafka集群:kafka监控系统kafka eagle安装使用
1.下载2.4.1版本
写文章的时候看到2.5.0已经发版的,部署方式一样。
2.解压tar包
tar -zxvf kafka_2.11-2.4.1.tgz -C .
3.配置环境变量
vim /etc/profile
export JAVA_HOME=/opt/app/jdk1.8.0_181
export KAFKA_HOME=/opt/app/kafka_2.11-2.4.1
export KE_HOME=/opt/app/kafka-eagle-web-1.4.6
export PATH=$KE_HOME/bin:$KAFKA_HOME/bin:$PATHsouce /etc/profile
4.修改配置文件
vim $KAFKA_HOME/config/server.properties
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
listeners=PLAINTEXT://sdakf01:9092
message.max.bytes=100000000
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
#log.dirs=/tmp/kafka-logs
log.dirs=/opt/app/kafka_2.11-2.4.1/log
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
#zookeeper.connect=localhost:2181
zookeeper.connect=sdakf01:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
5.启动验证
1.启动自带的zookeeper:
bin/zookeeper-server-start.sh [-daemon] config/zookeeper.properties
2.启动kafka:
bin/kafka-server-start.sh [-daemon] config/server.properties
这里的-daemon为可选参数,加上就是后台启动,不加就是前台启动会打印到控制台。
3.验证:
创建topic:
./kafka-topics.sh --create --zookeeper sdakf01:2181 --replication-factor 1 --partitions 3 --topic wyk_csdn
这里的--replication-factor当有几个broker节点才可以最多有几个备份,因为我是单机的,所以指定的是1。
-------2021.12.13:更新------
之前忘记贴创建topic成功的截图,有人在评论区质疑其可用性和原创性。所以专门重装了一个执行一下,给出截图证明。可以质疑,但请不要这种态度。@Amazing66


-----------------------------------
列所有topic:
./kafka-topics.sh --list --zookeeper sdakf01:2181

启动producer:
./kafka-console-producer.sh --broker-list sdakf01:9092 --topic wyk_csdn
启动consumer:
./kafka-console-consumer.sh --bootstrap-server sdakf01:9092 --zookeeper sdakf01:2181 --topic wyk_csdn
消费数据:


查看topic信息:
./kafka-topics.sh --describe --zookeeper sdakf01:2181 --topic wyk_csdn

查看消费情况:
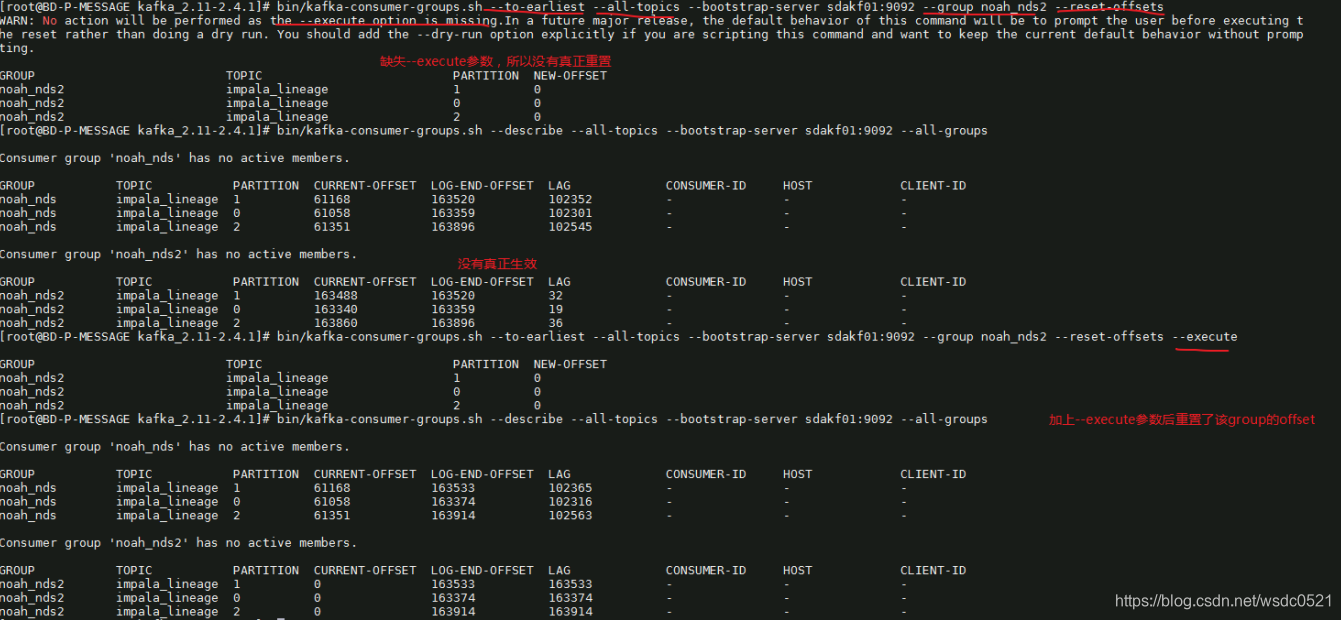
./kafka-consumer-groups.sh --describe --all-groups --all-topics --bootstrap-server sdakf01:9092
./kafka-consumer-groups.sh --describe --all-topics --bootstrap-server sdakf01:9092 --group noah_nds2

重置offset:
./kafka-consumer-groups.sh --reset-offsets --to-earliest --bootstrap-server sdakf01:9092 --all-topics --group noah_nds2 --execute


















 850
850





 到【灌水乐园】发言
到【灌水乐园】发言









